
Interview on Artificial Intelligence
by Jerome Kehrli
Posted on Friday Jun 29, 2018 at 04:29PM in Computer Science
This is a collection of three videos I recorded for the "empowerment fundation" as part of their file on Artificial Intelligence.
In parallel and in addition to BeCurious, the Empowerment Foundation launches in 2018 a project of curation files thematic through the bee² program.
Taking up the practice of curating video content, bee² means: exploring the issues that build our world, expand the perspectives of analysis, stimulate awareness to enable everyone to act in a more enlightened and responsible way facing tomorrow's challenges.
It's about bringing out specific issues and allowing everyone to easily discover videos the most relevant, validated by experts, on the given topic without having to browse many sources of information.
The three videos I contributed to are (in french, sorry):
- AI and Cybersecurity: Preventing Bank Fraud
- How does the Google self driving car work ?
- What are the limits of AI?
The three videos can be viewed directly on this very page below.
Read MoreLambda Architecture with Kafka, ElasticSearch and Spark (Streaming)
by Jerome Kehrli
Posted on Friday May 04, 2018 at 12:32PM in Big Data
The Lambda Architecture, first proposed by Nathan Marz, attempts to provide a combination of technologies that together provide the characteristics of a web-scale system that satisfies requirements for availability, maintainability, fault-tolerance and low-latency.
Quoting Wikipedia: "Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods.
This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation.
The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce."
In my current company - NetGuardians - we detect banking fraud using several techniques, among which real-time scoring of transactions to compute a risk score.
The deployment of Lambda Architecture has been a key evolution to help us evolve towards real-time scoring on the large scale.
In this article, I intend to present how we do Lambda Architecture in my company using Apache Kafka, ElasticSearch and Apache Spark with its extension Spark-Streaming, and what it brings to us.
Read MoreTags: architecture big-data elasticsearch kafka lambda-architecture mesos spark
Artificial Intelligence for Banking Fraud Prevention
by Jerome Kehrli
Posted on Monday Apr 30, 2018 at 02:57PM in Banking
In this article, I intend to present my company's - NetGuardians - approach when it comes to deploying Artificial Intelligence techniques towards better fraud detection and prevention.
This article is inspired from various presentations I gave on the topic in various occasions that synthesize our experience in regards to how these technologies were initially triggering a lot of skepticism and condescension and how it turns our that they are now really mandatory to efficiently prevent fraud in financial institutions, due to the rise of fraud costs, the maturity of cybercriminals and the complexity of attacks.
Here financial fraud is considered at the broad scale, both internal fraud, when employees divert funds from their employer and external fraud in all its forms, from sophisticated network penetration schemes to credit card theft.
I don't have the pretension to present an absolute or global overview. Instead, I would want to present things from the perspective of NetGuardians, from our own experience in regards to the problems encountered by our customers and the how Artificial Intelligence helped us solve these problems.
Tags: ai artificial-intelligence bank banking big-data finance fraud-prevention netguardians
Presenting NetGuardians' Big Data technology (video)
by Jerome Kehrli
Posted on Friday Jan 05, 2018 at 07:00PM in Big Data
I am presenting in this video NetGuardians' Big Data approach, technologies and its advantages for the banking institutions willing to deploy big data technologies for Fraud Prevention.
The speech is reported in textual form hereafter.
Read MoreTags: bank banking big-data netguardians video
The Agile Collection Book
by Jerome Kehrli
Posted on Tuesday Dec 12, 2017 at 11:57PM in Agile
Agility in Software Development is a lot of things, a collection of so many different methods. In a recent article I presented the Agile Landscape V3 from Christopher Webb which does a great job in listing these methods and underlying how much Agility is much more than some scrum practices on top of some XP principles.
I really like this infographic since I can recover most-if-not-all of the principles and practices from the methods I am following.
Recently I figured that I have written on this very blog quite a number of articles related to these very Agile Methods and after so much writing I thought I should assemble these articles in a book.
So here it is, The Agile Methods Collection book.
The Agile Methods Collection book is simply a somewhat reformatted version of all the following articles:
- Agile Landscape from Deloitte
- Agile Software Development, lessons learned
- Agile Planning : tools and processes
- DevOps explained
- The Lean Startup - A focus on Practices
- Periodic Table of Agile Principles and Practices
So if you already read all these articles, don't download this book.
If you didn't so far or want to have a kind of reference on all the methods from the collection illustrated above, you might find this book useful.
I hope you'll have as much pleasure reading it than I had writing all these articles.
Deciphering the Bangladesh bank heist
by Jerome Kehrli
Posted on Wednesday Nov 15, 2017 at 11:03PM in Banking
The Bangladesh bank heist - or SWIFT attack - is one of the biggest bank robberies ever, and the most impressive cyber-crime in history.
This is the story of a group of less than 20 cyber-criminals, composed by high profile hackers, engineers, financial experts and banking experts who gathered together to hack the worldwide financial system, by attacking an account of the central bank of Bangladesh, a lower middle income nation and one of the world's most densely populated countries, and steal around 81 million US dollars, successfully, after attempting to steal almost a billion US dollars.
In early February 2016, authorities of Bangladesh Bank were informed that about 81 million USD was illegally taken out of its account with the Federal Reserve Bank of New York using an inter-bank messaging system known as SWIFT. The money was moved via SWIFT transfer requests, ending up in bank accounts in the Philippines and laundered in the Philippines' casinos during the chinese New-Year holidays.
Fortunately, the major part of the billion US dollars they intended to steal could be saved, but 81 million US dollars were successfully stolen and are gone for good.
The thieves have stolen this money without any gun, without breaking physically in the bank, without any form of physical violence. (There are victims though, there are always victims in such case, but they haven't suffered any form of physical violence)
These 81 million US dollars disappeared and haven't been recovered yet. The thieves are unknown, untroubled and safe.
The Bangladesh bank heist consisted in hacking the Bangladesh central bank information system to issue fraudulent SWIFT orders to withdraw money from the banking institution. SWIFT is a trusted and closed network that bank use to communicate between themselves around the world. SWIFT is owned by the major banking institutions.
In terms of technological and technical mastery, business understanding, financial systems knowledge and timing, this heist was a perfect crime. The execution was brilliant, way beyond any Hollywood scenario. And the bank was actually pretty lucky that that the hackers didn't successfully loot the billion US dollars as they planned, but instead only 81 million.
As such, from a purely engineering perspective, studying this case is very exiting. First, I cannot help but admire the skills of the team of thieves team as well as the shape of the attack, and second, it's my job in my current company to design controls and systems preventing such attack from happening against our customers in the future.
In this article, I intend to present, explain and decipher as many of the aspects of the Bangladesh bank heist and I know.
Read MoreTags: bangladesh-bank-heist bank banking cybercrime swift swift-attack
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part III : so why is it cool ?
by Jerome Kehrli
Posted on Wednesday Aug 30, 2017 at 10:43PM in Big Data
So, finally the conclusion of this serie of three articles, the big conclusion, where I intend to present why this ELK-MS, ElasticSearch/LogStash/Kibana - Mesos/Spark, stack is cool.
Without any more waiting, let's give the big conclusion right away, using ElasticSearch, Mesos and Spark can really distribute and scale the processing the way we want and very easily scale the processing linearly with the amount of data to process.
And this, exactly this and nothing else, is very precisely what we want from a Big Data Processing cluster.
At the end of the day, we want a system that books a lot of the resources of the cluster for a job that should process a lot of data and only a small subset of these resources for a job that works on a small subset of data.
And this is precisely what one can achieve pretty easily with the ELK-MS stack, in an almost natural and straightforward way.
I will present why and how in this article.
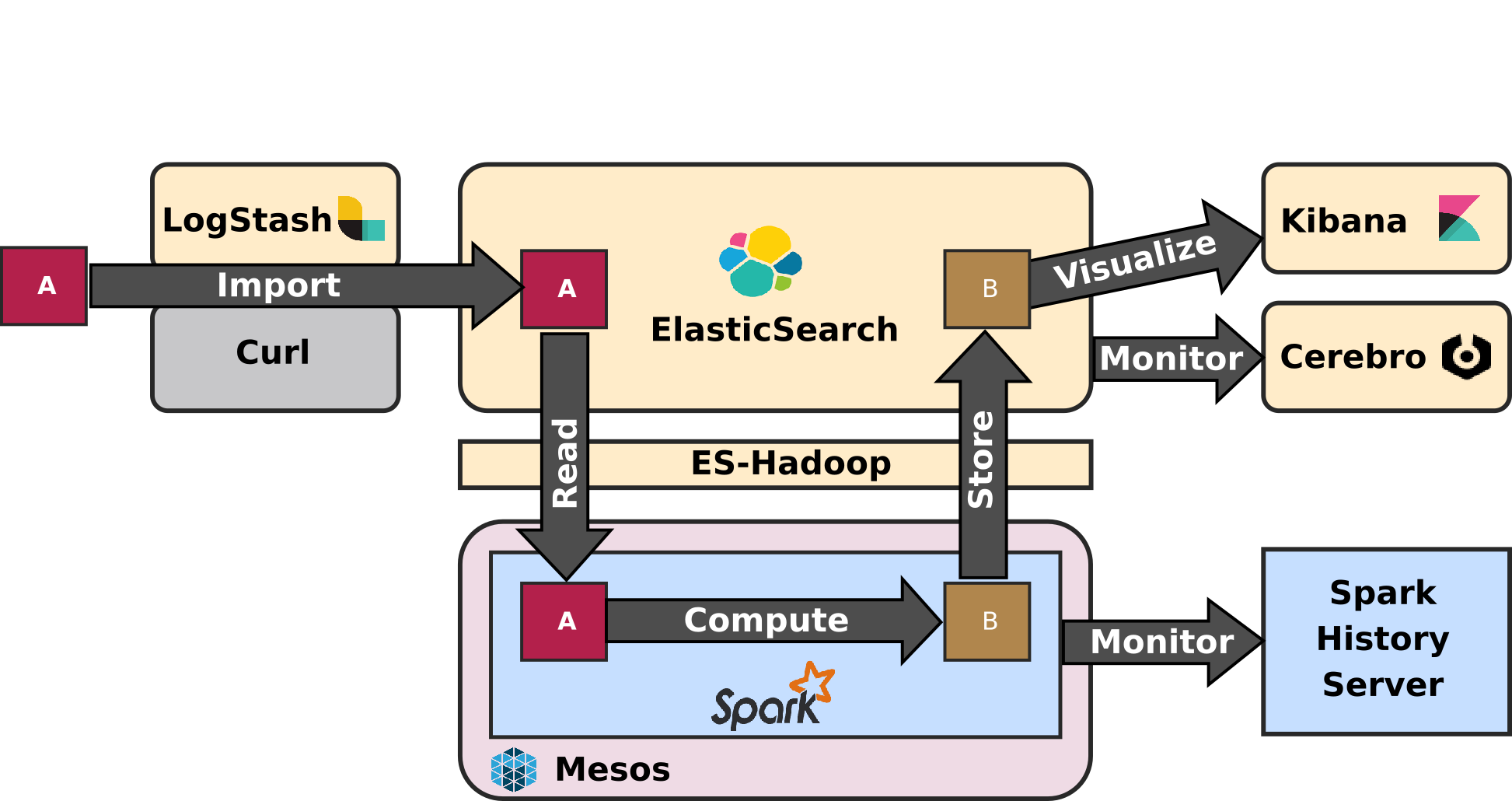
The first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
This third and last article - ELK-MS - part III : so why is it cool? presents, as indicated, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part II : assessing behaviour
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:30PM in Big Data
This article is the second article in my serie of two articles presenting the ELK-MS Stack and test cluster.
ELK-MS stands for ElasticSearch/LogStash/Kibana - Mesos/Spark. The ELK-MS stack is a simple, lightweight, efficient, low-latency and performing alternative to the Hadoop stack providing state of the art Data Analytics features.
ELK-MS is especially interesting for people that don't want to settle down for anything but the best regarding Big Data Analytics functionalities but yet don't want to deploy a full-blend Hadoop distribution, for instance from Cloudera or HortonWorks.
Again, I am not saying that Cloudera and HortonWorks' Hadoops distributions are not good. Au contraire, they are awesome and really simplifies the overwhelming burden of configuring and maintaining the set of software components they provide.
But there is definitely room for something lighter and simpler in terms of deployment and complexity.
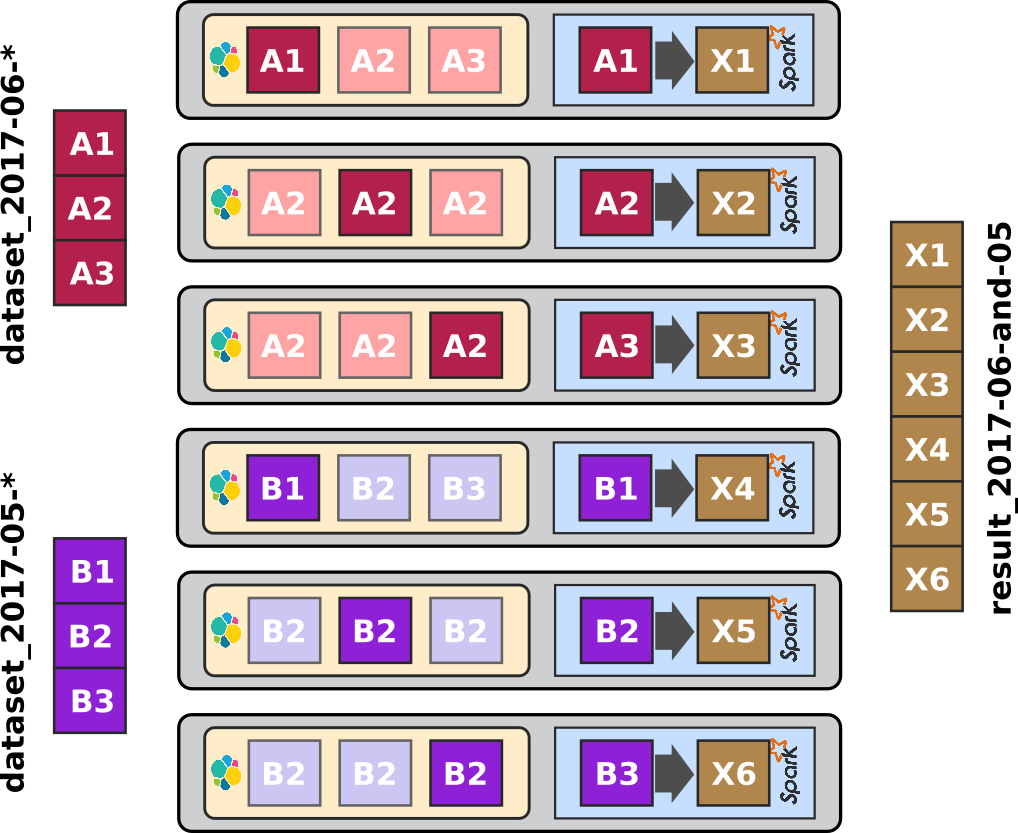
The first article - entitled - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
This second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses the challenges and constraints on this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part I : setup the cluster
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:29PM in Big Data
In my current company, we implement heavy Data Analytics algorithms and use cases for our customers. Historically, these heavy computations were taking a whole lot of different forms, mostly custom computation scripts in python or else using RDBMS databases to store data and results.
A few years ago, we started to hit the limits of what we were able to achieve using traditional architectures and had to move both our storage and processing layers to NoSQL / Big Data technologies.
We considered a whole lot of different approaches, but eventually, and contrary to what I expected first, we didn't settle for a standard Hadoop stack. We are using ElasticSearch as key storage backend and Apache Spark as processing backend.
Now of course we were initially still considering a Hadoop stack for the single purpose of using YARN as resource management layer for Spark ... until we discovered Apache Mesos.
Today this state of the art ELK-MS - for ElasticSearch/Logstash/Kibana - Mesos/Spark stack performs amazingly and I believe it to be a really lightweight, efficient, low latency and performing alternative to a plain old Hadoop Stack.
I am writing a serie of two articles to present this stack and why it's cool.
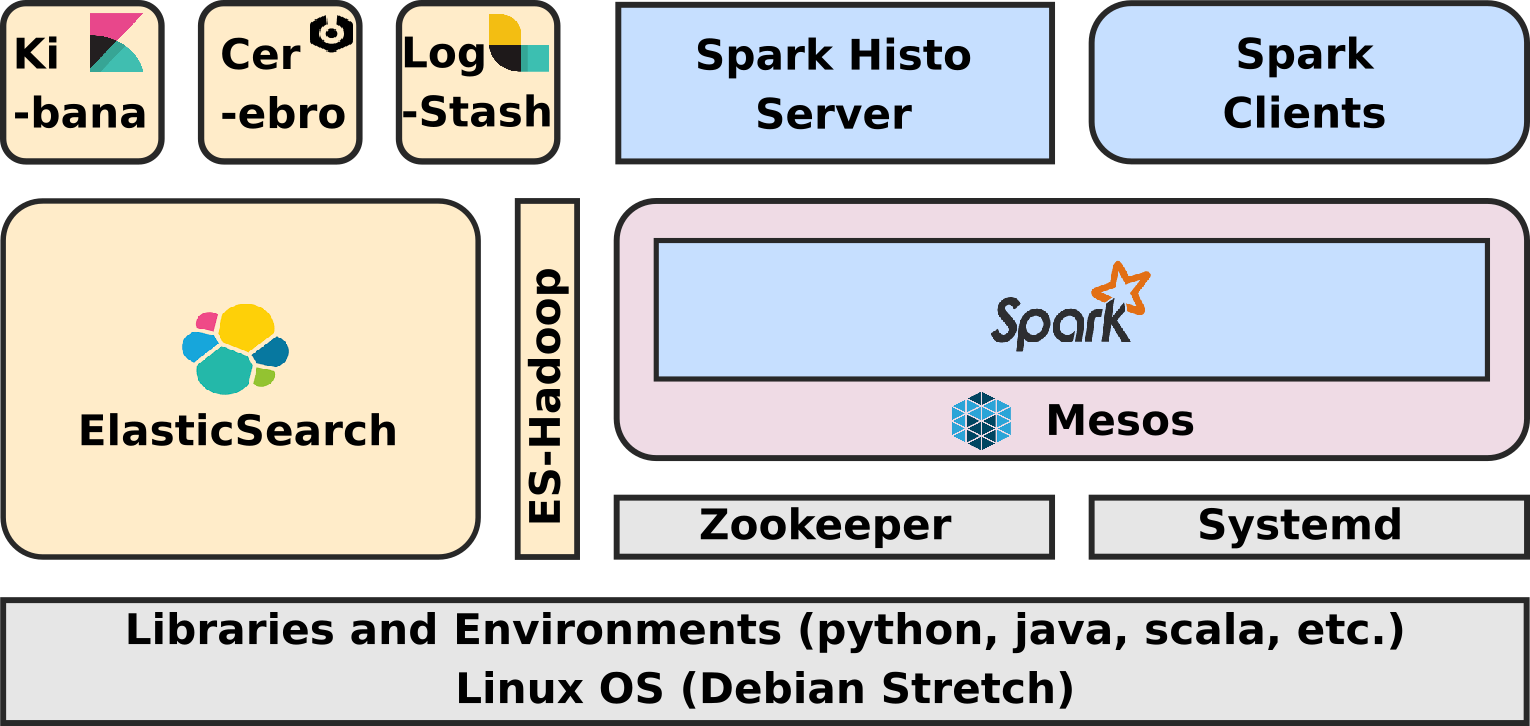
This first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Hadoop and Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
Periodic Table of Agile Principles and Practices
by Jerome Kehrli
Posted on Thursday Jun 29, 2017 at 11:19PM in Agile
After writing my previous article, I wondered how I could represent on a single schematic all the Agile Principles and Practices from the methods I am following, XP, Scrum, Lean Startup, DevOps and others.
I found that the approach I used in in a former schematic - a graph of relationship between practices - is not optimal. It already looks ugly with only a few practices and using the same approach for the whole set of them would make it nothing but a mess.
So I had to come up with something else, something better.
Recently I fell by chance on the Periodic Table of the Elements... Long time no see... Remembering my physics lessons in University, I always loved that table. I remembered spending hours understanding the layout and admiring the beauty of its natural simplicity.
So I had the idea of trying the same layout, not the same approach since both are not comparable, really only the same layout for Agile Principles and Practices.
The result is hereunder: The Periodic Table of Agile Principles and Practices:
The layout principle is and the description of the principles and practices is explained hereafter.
Read MoreTags: agile periodic-table practices
Agile Planning : tools and processes
by Jerome Kehrli
Posted on Wednesday Jun 14, 2017 at 08:42PM in Agile
All the work on Agility in the Software Engineering Business in the past 20 years, initiated by Kent Beck, Ward Cunningham and Ron Jeffries, comes from the finding that traditional engineering methodologies apply only poorly to the Software Engineering business.
If you think about it, we are building bridges from the early stages of the Roman Empire, three thousand years ago. We are building heavy mechanical machinery for almost three hundred years. But we are really writing software for only fifty years.
In addition, designing a bridge or a mechanical machine is a lot more concrete than designing a Software. When an engineering team has to work on the very initial stage of the design of a bridge or mechanical machine, everyone in the team can picture the result in his mind in a few minutes and breaking it down to a set of single Components can be done almost visually in one's mind.
A software, on the other hand, is a lot more abstract. This has the consequence that a software is much harder to describe than any other engineering product which leads to many levels of misunderstanding.
The waterfall model of Project Management in Software Engineering really originates in the manufacturing and construction industries.
Unfortunately, for the reasons mentionned above, despite being so widely used in the industry, it applies only pretty poorly to the Software Engineering business. Most important problems it suffers from are as follows:
- Incomplete or moving specification: due to the abstract nature of software, it's impossible for business experts and business analysts to get it right the first time.
- The tunnel effect: we live in a very fast evolving world and businesses need to adapt all the time. The software delivered after 2 years of heavy development will fulfill (hardly, but let's admit it) the requirements that were true two years ago, not anymore today.
- Drop of Quality to meet deadlines: An engineering project is always late, always. Things are just a lot worst with software.
- Heightened tensions between teams: The misunderstanding between teams leads to tensions, and it most of the time turns pretty ugly pretty quick.
So again, some 20 years ago, Beck, Cunningham and Jeffries started to formalize some of the practices they were successfully using to address the uncertainties, the overwhelming abstraction and the misunderstandings inherent to software development. They formalized it as the eXtreme Programming methodology.
A few years later, the same guys, with some other pretty well known Software Engineers, such as Alistair Cockburn and Martin Fowler, gathered together in a resort in Utah and wrote the Manifesto for Agile Software Development in which they shared the essential principles and practices they were successfully using to address problems with more traditional and heavyweight software development methodologies.
Today, Agility is a lot of things and the set of principles of practices in the whole Agile family is very large. Unfortunately, most of them require a lot of experience to be understood and then applied successfully within an organization.
Unfortunately, the complexity of embracing a sound Agile Software Development Methodology and the required level of maturity a team has to have to benefit from its advantages is really completely underestimated.
I cannot remember the number of times I heard a team pretending it was an Agile team because it was doing a Stand up in the morning and deployed Jenkins to run the unit tests at every commit. But yeah, honestly I cannot blame them. It is actually difficult to understand Agile Principles and Practices when one never suffered from the very drawbacks and problems they are addressing.
I myself am not an agilist. Agility is not a passion, neither something that thrills me nor something that I love studying in my free time. Agility is to me simply a necessity. I discovered and applied Agile Principles and practices out of necessity and urgency, to address specific issues and problems I was facing with the way my teams were developing software.
The latest problem I focused on was Planning. Waterfall and RUP focus a lot on planning and are often mentioned to be superior to Agile methods when it comes to forecasting and planning.
I believe that this is true when Agility is embraced only incompletely. As a matter of fact, I believe that Agility leads to much better and much more reliable forecasts than traditional methods mostly because:
- With Agility, it becomes easy to update and adapt Planning and forecasts to always match the evolving reality and the changes in direction and priority.
- When embracing agility as a whole, the tools put in the hands of Managers and Executive are first much simpler and second more accurate than traditional planning tools.
In this article, I intend to present the fundamentals, the roles, the processes, the rituals and the values that I believe a team would need to embrace to achieve success down the line in Agile Software Development Management - Product Management, Team Management and Project Management - with the ultimate goal of making planning and forecasting as simple and efficient as it can be.
All of this is a reflection of the tools, principles and practices we have embraced or are introducing in my current company.
Tags: agile agile-planning devops lean-startup scrum visual-management xp
Bytecode manipulation with Javassist for fun and profit part II: Generating toString and getter/setters using bytecode manipulation
by Jerome Kehrli
Posted on Monday Apr 24, 2017 at 10:38PM in Java
Following my first article on Bytecode manipulation with Javassist presented there: Bytecode manipulation with Javassist for fun and profit part I: Implementing a lightweight IoC container in 300 lines of code, I am here presenting another example of Bytecode manipulation with Javassist: generating toString method as well as property getters and setters with Javassist.
While the former example was oriented towards understanding how Javassist and bytecode manipulation comes in help with implementing IoC concerns, such as what is done by the spring framework of the pico IoC container, this new example is oriented towards generating boilerplate code, in a similar way to what Project Lombok is doing.
As a matter of fact, generating boilerplate code is another very sound use case for bytecode manipulation.
Boilerplate code refers to portions of code that have to be included or written in the same way in many places with little or no alteration.
The term is often used when referring to languages that are considered verbose, i.e. the programmer must write a lot of code to do minimal job. And Java is unfortunately a clear winner in this regards.
Avoiding boilerplate code is one of the main reasons (but by far not the only one of course !) why developers are moving away from Java in favor of other JVM languages such as Scala.
In addition, as a reminder, a sound understanding of the Java Bytecode and the way to manipulate it are strong prerequisites to software analytics tools, mocking libraries, profilers, etc. Bytecode manipulation is a key possibility in this regards, thanks to the JVM and the fact that bytecode is interpreted.
Traditionally, bytecode manipulation libraries suffer from complicated approaches and techniques. Javassist, however, proposes a natural, simple and efficient approach bringing bytecode manipulation possibilities to everyone.
So in this second example about Javassist we'll see how to implement typical Lombok features using Javassist, in a few dozen lines of code.
Read MoreThe Digitalization - Challenge and opportunities for financial institutions
by Jerome Kehrli
Posted on Tuesday Mar 21, 2017 at 09:52PM in General
A few weeks ago, I did a speech about the Digitalization and its impact on financial institutions, both in terms of challenges and opportunities in the context of my role as Head of R&D in my current company.
I am reporting here my speech as an article.
Even though the Digitalization and its impacts is something so widely discussed and studied nowadays, even in banking institutions, I still find it puzzling that so many of them struggle following the pace.
Having said that, many others on the other hand have well understood how much technology is about to disrupt the banking business just as Uber has disrupted the transportation business and AirBnB the lodging business and many good and enlightening initiatives start to flourish in the news.
But still, it seems to me that most innovations in banking are really coming from small players or even startups - think of fintechs - instead of coming from the big players of the banking industry. For instance, paying everything with a cellphone is a thing for a few years now in many African countries while it's not at all in Europe, even in Switzerland, THE country of banking.
Especially in Switzerland, financial institutions struggle keeping up with evolution of their business coming from the digitalization on one side and the regulatory pressure as well as the reduction of the margins on the other side.
Discussing this very matter further exceeds the scope of this article of course but I want to report below my speech notes and present what I see as the most important challenges and opportunities for the banking industry coming from the digitalization.
Tags: bank banking challenge digital-transformation digitalization finance opportunities
Agile Landscape from Deloitte
by Jerome Kehrli
Posted on Thursday Mar 02, 2017 at 11:51PM in Agile
I've seen this infographic from Christopher Webb at Deloitte (at the time) recently.
This is the most brilliant infographic I've seen for years.
Christopher Webb presents here a pretty extended set of Agile Practices associated to their respective frameworks. The practices presented are a collection of all Agile practices down the line, related to engineering but also management, product identification, design, operation, etc.
(Source : Christopher Webb - LAST Conference 2016 Agile Landscape - https://www.slideshare.net/ChrisWebb6/last-conference-2016-agile-landscape-presentation-v1)
I find this infographic brilliant since its the first time I see a "one ring to rule them all" view of what I consider should be the practices towards scaling Agility at the level of the whole IT Organization.
Very often, when we think of Agility, we limit our consideration to solely the Software Build Process.
But Agility is more than that. And I believe an Agile corporation should embrace also Agile Design, Agile Operations and Agile Management.
This infographic does a great job in presenting how these frameworks enrich and complements each others towards scaling Agility at the level of the whole IT Organization.
To be honest there are even many more frameworks that those indicated on this infographic and Chris Webb is presenting some additional - reaching 43 in total - in his presentation.
But I believe he did a great job in presenting the most essential ones and presenting how these practices, principles and framework work together to achieve the ultimate goal of every corporation: skyrocketing employee productivity and happiness, maximizing customer satisfaction and blowing operational efficiency up.
Now I would want to present why I think considering Agility down the line in each and every aspect around the engineering team and how these frameworks completing each other are important.
Read MoreTags: agile agile-landscape
Bytecode manipulation with Javassist for fun and profit part I: Implementing a lightweight IoC container in 300 lines of code
by Jerome Kehrli
Posted on Monday Feb 13, 2017 at 09:30PM in Java
Java bytecode is the form of instructions that the JVM executes.
A Java programmer, normally, does not need to be aware of how Java bytecode works.
Understanding the bytecode, however, is essential to the areas of tooling and program analysis, where the applications can modify the bytecode to adjust the behavior according to the application's domain. Profilers, mocking tools, AOP, ORM frameworks, IoC Containers, boilerplate code generators, etc. require to understand Java bytecode thoroughly and come up with means of manipulating it at runtime.
Each and every of these advanced features of what is nowadays standard approaches when programming with Java require a sound understanding of the Java bytecode, not to mention completely new languages running on the JVM such as Scala or Clojure.
Bytecode manipulation is not easy though ... except with Javassist.
Of all the libraries and tools providing advanced bytecode manipulation features, Javassist is the easiest to use and the quickest to master. It takes a few minutes to every initiated Java developer to understand and be able to use Javassist efficiently. And mastering bytecode manipulation, opens a whole new world of approaches and possibilities.
The goal of this article is to present Javassist in the light of a concrete use case: the implementation in a little more than 300 lines of code of a lightweight, simple but cute IoC Container: SCIF - Simple and Cute IoC Framework.
Read More
