
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part I : setup the cluster
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:29PM in Big Data
Edited 2017-10-30: I was using ES 5.0.0 with Spark 2.2.0 at the time of writing the initial version of this article.
With ElasticSearch 6.x, and ES-Hadoop 6.x, the game changes a little. The Spark 2.2.0 Dynamic allocation system is now perfectly compatible with the way ES-Hadoop 6.x enforces data locality optimization and everything works just as expected.
In my current company, we implement heavy Data Analytics algorithms and use cases for our customers. Historically, these heavy computations were taking a whole lot of different forms, mostly custom computation scripts in python or else using RDBMS databases to store data and results.
A few years ago, we started to hit the limits of what we were able to achieve using traditional architectures and had to move both our storage and processing layers to NoSQL / Big Data technologies.
We considered a whole lot of different approaches, but eventually, and contrary to what I expected first, we didn't settle for a standard Hadoop stack. We are using ElasticSearch as key storage backend and Apache Spark as processing backend.
Now of course we were initially still considering a Hadoop stack for the single purpose of using YARN as resource management layer for Spark ... until we discovered Apache Mesos.
Today this state of the art ELK-MS - for ElasticSearch/Logstash/Kibana - Mesos/Spark stack performs amazingly and I believe it to be a really lightweight, efficient, low latency and performing alternative to a plain old Hadoop Stack.
I am writing a serie of two articles to present this stack and why it's cool.
This first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Hadoop and Big Data / NoSQL technologies in general by the reader.
Summary
- 1. Introduction
- 2. Target Architecture
- 3. niceideas ELK-MS
- 4. Noteworthy configuration elements
- 5. Conclusion
1. Introduction
Actually deploying a whole Hadoop stack is, let's say, at least heavy. Having HDFS, YARN, the Map Reduce framework and maybe Tez up and running is one thing, and it's maybe not that complicated, sure.
But with such a vanilla stack you're not going very far. You'll at least add the following minimal set of software components: Apache Sqoop for importing data in your HDFS cluster, Apache Pig for processing this data, Apache Hive for querying it. But yeah, then, Hive is so slow for small queries returning small datasets, you'll likely add Stinger ... and then a whole lot of other components.
Now setting all of these software components up and running and tuning them well is a real hassle so one might consider a HortonWorks or Cloudera distribution instead, and this is where it gets really heavy.
Don't get me wrong, both HortonWorks and Cloudera are doing an amazing job and their distributions are awesome.
But I am working in a context where we want something lighter, something more efficient, something easier to set up, master and monitor.
In addition, HDFS is great. But it's really only about distributed storage of data. Vanilla Hadoop doesn't really provide anything on top of this data aside from MapReduce. On the other hand, the NoSQL landscape is filled with plenty of solutions achieving the same resilience and performance than HDFS but providing advanced data querying features on top of this data.
Among all these solutions, ElasticSearch is the one stop shop for our use cases. It fulfills 100% of our requirements and provides us out of the box with all the querying features we require (and some striking advanced features).
Using ElasticSearch for our data storage needs, we have no usage whatsoever for HDFS.
In addition, ElasticSearch comes out of the box with a pretty awesome replacement of Sqoop: Logstash and a brilliant Data Visualization tool that has no free alternative in the Hadoop world: Kibana.
Now regarding Data Processing, here as well we found our one stop shop in the form of Apache Spark. Spark is a (vary) fast and general engine for large-scale data processing. At the ground of our processing needs, there is not one single use case we cannot map easily and naturally to Spark'S API, either using low level RDDs or using the DataFrame API (SparkSQL).
Now Spark requires some external scheduler and resources manager. It can run without it of course but fails in achieving concurrency when doing so.
We were seriously considering deploying Hadoop and YARN for this until we discovered Apache Mesos. Mesos is a distributed systems kernel built using the same principles as the Linux kernel, only at a different level of abstraction. The Mesos kernel runs on every machine and provides Spark with API’s for resource management and scheduling across entire Data-center and cloud environments.
1.1 Rationality
I call the software stack formed by the above components the ELK-MS stack, for ElasticSearch/LogStash/Kibana - Mesos/Spark.
The ELK-MS stack is a simple, lightweight, efficient, low-latency and performing alternative to the Hadoop stack providing state of the art Data Analytics features:
-
lightweight : ELK-MS is lightweight both in terms of setup and runtime.
In terms of setup, the distributed storage engine, ElasticSearch, the resource manager, Mesos, and the distributed processing engine, spark, are amazingly easy to setup and configure. They really work almost out of the box and only very few configuration properties have to be set when it comes to configuring resources in Mesos, honestly trying to optimize anything other than the default value really tends to worsen things.
In terms of runtime, ElasticSearch, Mesos and some components of Spark, the only long-running daemons have a very low memory footprint under low workload. Now of course, both ElasticSearch and Spark have pretty heavy memory needs when working. -
efficient : ElasticSearch, in contrary to HDFS, is not just a wide and simple distributed storage engine. ElasticSearch is in addition a real-time querying engine. It provides pretty advanced features such as aggregations and, up to a certain level, even distributed processing (scripted fields or else). With ELK-MS, the storage layer itself provides basic data analytics features.
In addition, Spark supports through the RDD API most if not all of what we can achieve using low-level Map Reduce. It obviously also supports plain old MapReduce. But the really striking feature of Spark is the DataFrame API and SparqSQL. -
low-latency : Spark is by design much faster than Hadoop. In addition, jobs on spark can be implemented in such as way that the processing time and job initialization time is much shorter than on Hadoop MapReduce (Tez makes things more even on Hadoop though).
But there again Spark has a joker: the Spark Streaming extension. -
performing : in addition to the above, both ElasticSearch and Spark share a common gene, not necessarily widely spread among the NoSQL landscape: the capacity to benefit as much from a big cluster with thousands of nodes than from a big machine with a hundreds of processor.
Spark and ElasticSearch are very good on a large cluster of small machines (and to be honest, the scaling out is really the preferred way to achieve optimal performance with both).
But in contrary to Hadoop, both Spark and ElasticSearch also works pretty good on a single fat machine with hundreds of processors, able to benefit from the multi-processor architecture of one single machine.
The conclusions of the behaviour assessment tests, at the end of the second article, as well as The conclusion of this serie of articles give some more leads on why the ELK-MS stack is cool.
For these reasons, we are extensively using the ELK-MS stack for our Data Analytics needs in my current company.
1.2 Purpose of this serie of articles
Setting up the ELK-MS stack in a nominal working mode is easy, but still requires a few steps. In addition, when assessing the stack and for testing purpose, I needed a way to setup a cluster and test key features such as optimization of data-locality between ElasticSearch and Spark.
I have written a set of scripts taking care of the nominal setup and a test framework based on Vagrant and VirtualBox.
This first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
2. Target Architecture
Before presenting the components and some noteworthy configuration aspects, let's dig into the architecture of the ELK-MS stack.
2.1 Technical Architecture
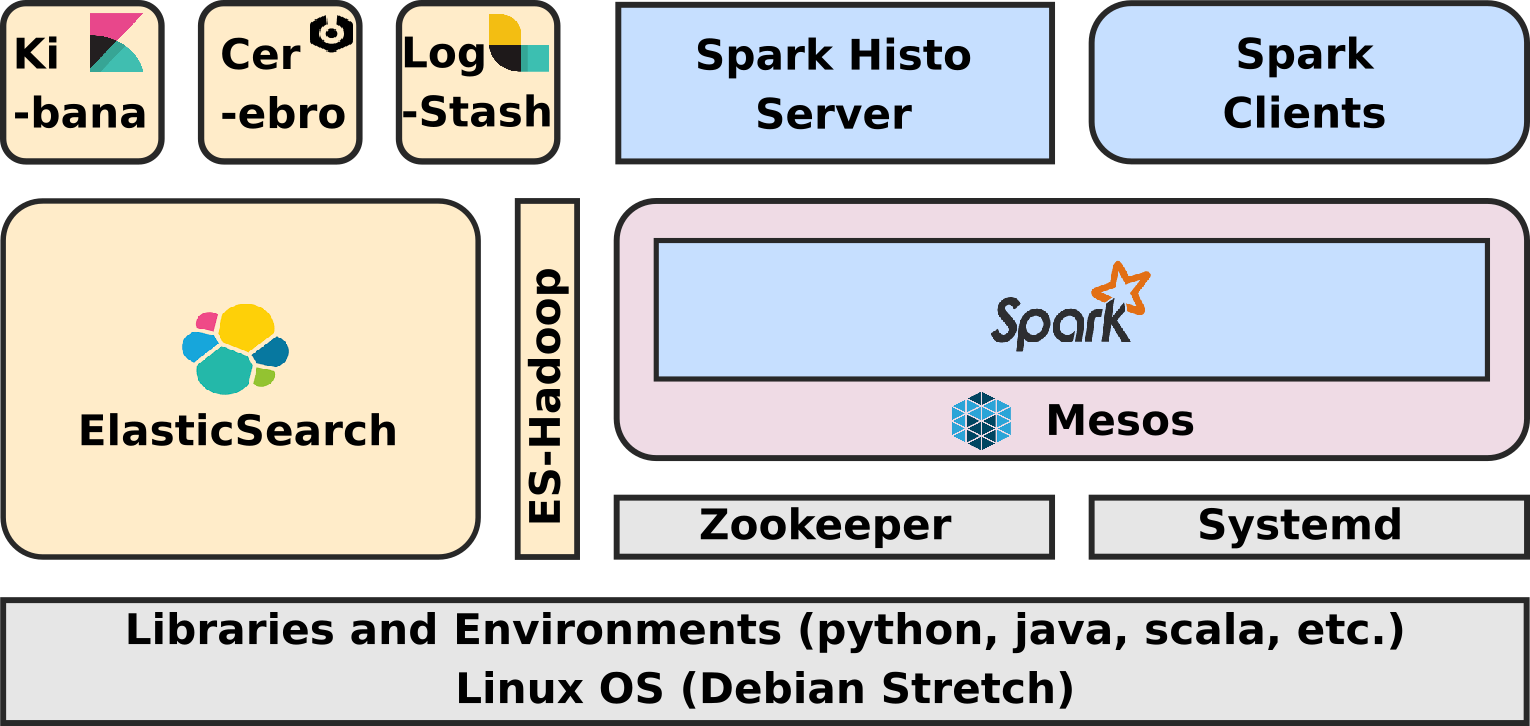
The technical architecture of the ELK-MS stack is as follows
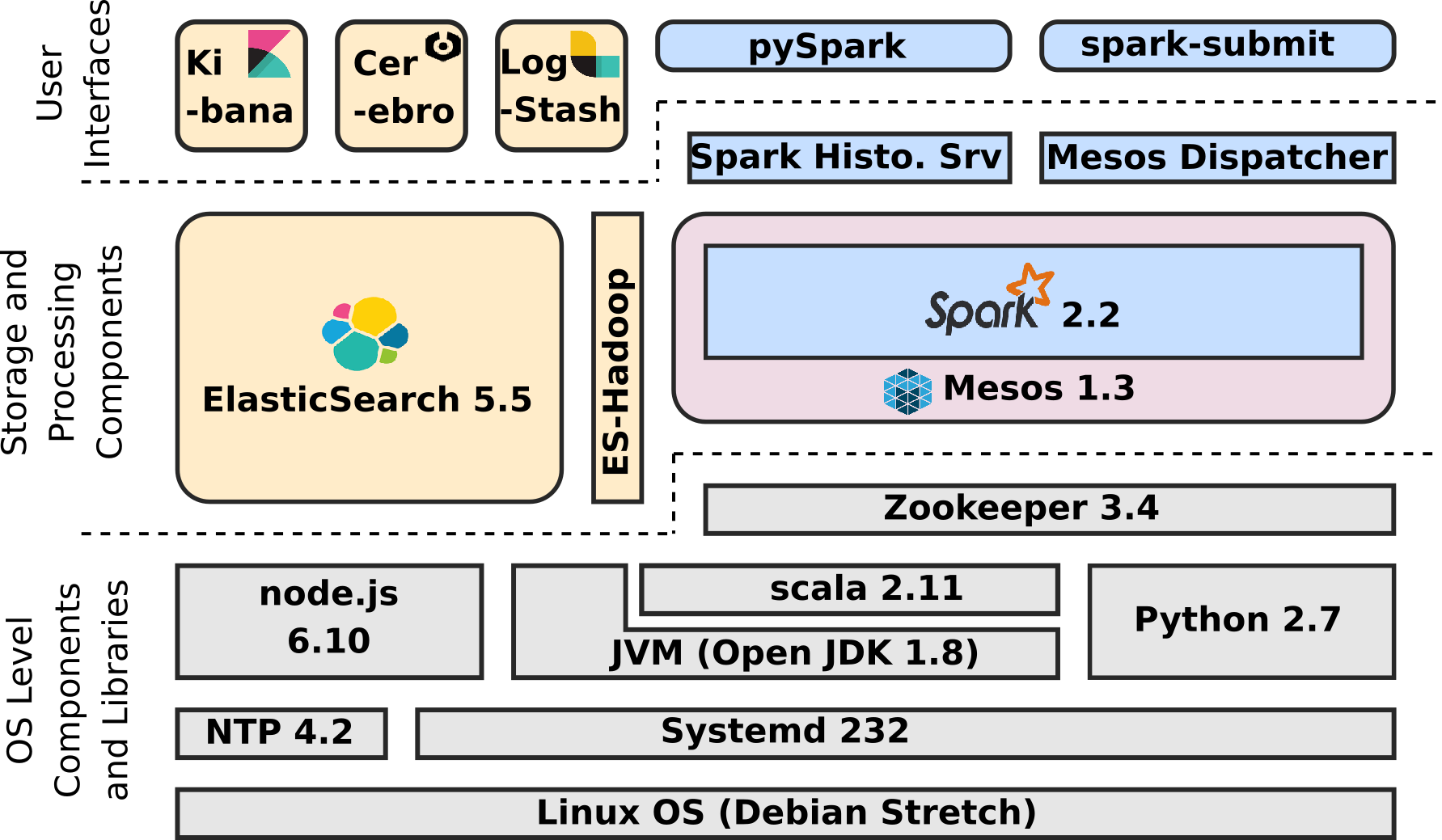
The components in grey are provided out of the box at OS level by Debian Stretch distribution.
The components in yellow are provided by Elastic in the ELK Stack.
Mesos is in light red.
The components in blue are from the Spark Framework.
Let's present all these components.
2.2 Components
This section presents the most essential components of the ELK-MS stack.
2.2.1 ElasticSearch
|
|
From ElasticSearch's web site : "ElasticSearch is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected."
ElasticSearch is a NoSQL Document-oriented database benefitting from the NoSQL Genes: data distribution by sharding (partitioning) and replication. It can run on all kind of hardware, from a big fat hundred CPUs machine to a multi-data centers cluster of commodity hardware.
ElasticSearch support real-time querying of data and advanced analytics features such as aggregation, scripted fields, advanced memory management models and even some support for MapReduce directly in ElasticSearch's engine. |
2.2.2 Logstash
|
|
From Logstash's web site : "Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite "stash." (Ours is Elasticsearch, naturally.)."
Logstash is really the equivalent of Sqoop in the Elastic world. It's a largely configurable data processing engine whose primary intent is to feed ElasticSearch with data that can come from pretty much all imaginable data sources and formats. Of course Logstash can also output data to a very extended set of sinks in addition to ElasticSearch.
Logstash can also be distributed just as ElasticSearch, enabling not only to scale out the data ingestion processing but also enabling smart co-location strategies with ElasticSearch. |
2.2.3 Kibana
|
|
From Kibana's web site : "Kibana lets you visualize your ElasticSearch data and navigate the Elastic Stack, so you can do anything from learning why you're getting paged at 2:00 a.m. to understanding the impact rain might have on your quarterly numbers."
Kibana core ships with the classics: histograms, line graphs, pie charts, sunbursts, and more. They leverage the full aggregation capabilities of ElasticSearch.
In the context of ELK-MS, Kibana is an amazing addition to ElasticSearch, since we can write Spark programs that work with data from ES but also stores their results in ES. As such, Kibana can be used out of the box to visualize not only the input data but also the results of the Spark scripts. |
2.2.4 Cerebro
|
|
From Cerebro's web site : "Cerebro is an open source(MIT License) ElasticSearch web admin tool built using Scala, Play Framework, AngularJS and Bootstrap.." Cerebro is the one-stop-shop, little and simple but efficient, monitoring and administration tool for ElasticSearch.
Cerebro is a must have with ElasticSearch since working only with the REST API to understand ElasticSearch's topology and perform most trivial administration tasks (such as defining mapping templates, etc.) is a real hassle.
|
2.2.5 Spark
|
|
From Spark's web site : "Apache Spark is a fast and general engine for large-scale data processing."
From Wikipedia's Spark article: "Apache Spark provides programmers with an application programming
interface centered on a data structure called the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines,
that is maintained in a fault-tolerant way.
The availability of RDDs facilitates the implementation of both iterative algorithms, that visit their dataset multiple times in a loop, and interactive/exploratory data analysis, i.e., the repeated database-style querying of data. The latency of such applications (compared to a MapReduce implementation, as was common in Apache Hadoop stacks) may be reduced by several orders of magnitude." |
2.2.6 Mesos
|
|
From Mesos' web site : "Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
In the context of ELK-MS, and in a general way when considering running Spark in a production environment, Mesos is the way to go if one doesn't want to deploy a full Hadoop stack to support Spark. In the end, it appears that Mesos performs amazingly, both by suffering only form a very small memory footprint on the cluster and by being incredibly easy to setup and administer. |
2.2.7 Spark on Mesos specificities
Happily Spark and Mesos, both products from the Apache fundation, know about each other and are designed to work with each other.
There are some specificities though when it comes to run Spark on Mesos as opposed to running Spark on the more usual YARN, as explained below,
|
|
Interestingly, mesos handles spark workers in a pretty amazing way. Not only does Mesos consider node locality requirements between spark and ElasticSearch, but Mesos also provides required retry policies and else. When launching a spark job, there is nevertheless one Single Point of Failure that remains: the spark driver that lives outside of the Mesos/Spark cluster, on the machine it is launched by the user or the driving process.
For this reason, spark provides the Spark Mesos Dispatcher that can be used to dispatch the Spark Driver itself on the Mesos/Spark cluster.
The Spark Mesos Dispatcher addresses the single weakness of a spark process: the driver that can crash or exhaust resources and handles it just as any other bit of spark processing. |
Spark History Server
In contrary to spark running in standalone mode, when spark runs on Mesos, it has no long life running backend that the user can use to interact with when Spark is not actually executing a job.
Mesos takes care of creating and dispatching Spark workers when required. When no Spark job is being executed, there is no spark process somewhere one can interact with to query, for instance, the results of a previous job.
Happily spark provides a solution out of the box for this : the spark History Server.
The Spark History Server is a lightweight process that presents the results stored in the Spark Event Log folder, that folder on the filesystem where Spark stores consolidated results from the various workers.
The documentation of Spark is very unclear about this, but since only the spark driver stores consolidated results in the event log folder, if all drivers are launched on the same machine (for instance the Mesos master machine), there is no specific needs for HDFS.
One should note that running the Spark History Server without HDFS to store the event log can be a problem if one uses the Spark Mesos Dispatcher to distribute the driver program itself on the Mesos cluster. In this case using a common NFS share for instance would solve the problem.
2.3. Making it work together : ES-Hadoop
|
|
From ES-Hadoop's web site : "Connect the massive data storage and deep processing power of Hadoop with the real-time search and analytics of Elasticsearch. The Elasticsearch-Hadoop (ES-Hadoop) connector lets you get quick insight from your big data and makes working in the Hadoop ecosystem even better."
Initially ES-Hadoop contains the set of classes implementing the connectors for pretty much all de facto "standards" components of a full hadoop stack, such as Hive, Pig, Spark, etc.
In the context of ELK-MS, the ES-Hadoop connector is one of the most important components. When one considers building a large collocated ES / Mesos / Spark cluster and execute tasks requiring to fetch large datasets from ES to Spark, the data-locality knowledge supported by ES-Hadoop is utmost important. The second article of this serie is largely devoted to assessing how and how far the optimization of data-locality works.
When launching a job using Spark, the connector determines the locations of the shards in ElasticSearch that it will be targeting and creates a partition per shard (or even further to allow for greater parallelism). Each of these partition definitions carries with it the index name, the shard id, the slice id and the addresses of the machines where it can find this data on locally. It then relies on Spark's task scheduling to achieve data locality.
|
2.4 Application Architecture
Typical Data Flows on the ELK-MS platform is illustrated by the following Application Architecture schema:
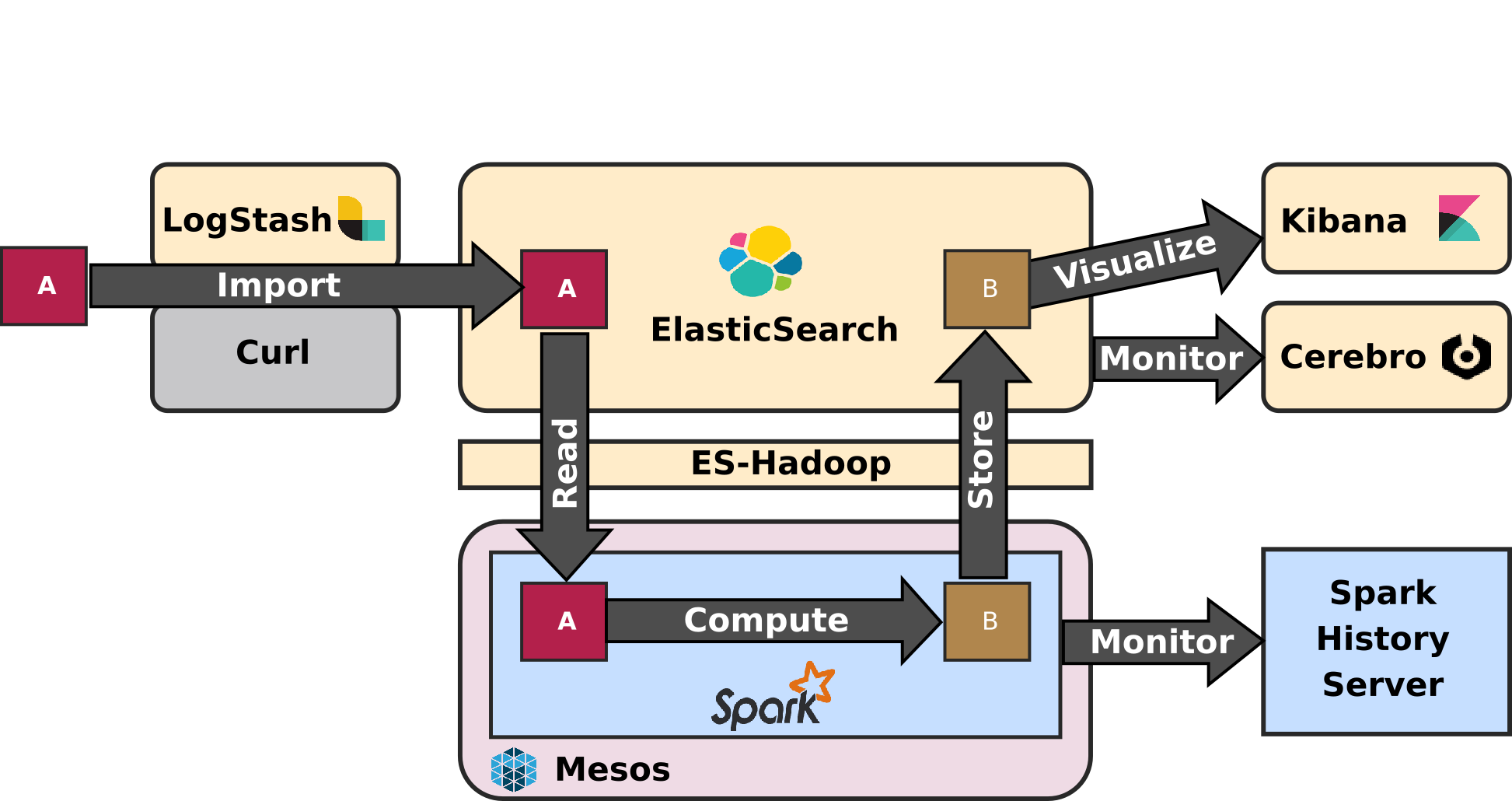
The tests presented "in the second article in this serie: ELK-MS - part II : assessing behaviour" are intended to assess the well behaviour of this application architecture.
3. niceideas ELK-MS
So. Again as stated in introduction before, when playing with ES / Mesos / Spark, it happened quite fast that I got two urgent needs:
- First, I needed a reference for configuring the various software so that they work well together. Instead of writing pages of documentation indicating the settings to tune, I ended up putting all of that in setup scripts aimed at helping me re-apply the configuration at will.
- Second, I needed a test cluster allowing me to assess how various key features were working, among which ensuring optimization of data-locality was one of the most important.
In the end I wrote a set of scripts using Vagrant and VirtualBox aimed at making it possible for me to rebuild the test cluster and reapply the configuration at will. I packaged all these scripts together and call this package the niceideas_ELK-MS package.
This package is available for download here.
3.1 System and principles
The System Architecture of the ELK-MS platform as build by the niceideas_ELK-MS package is as follows:
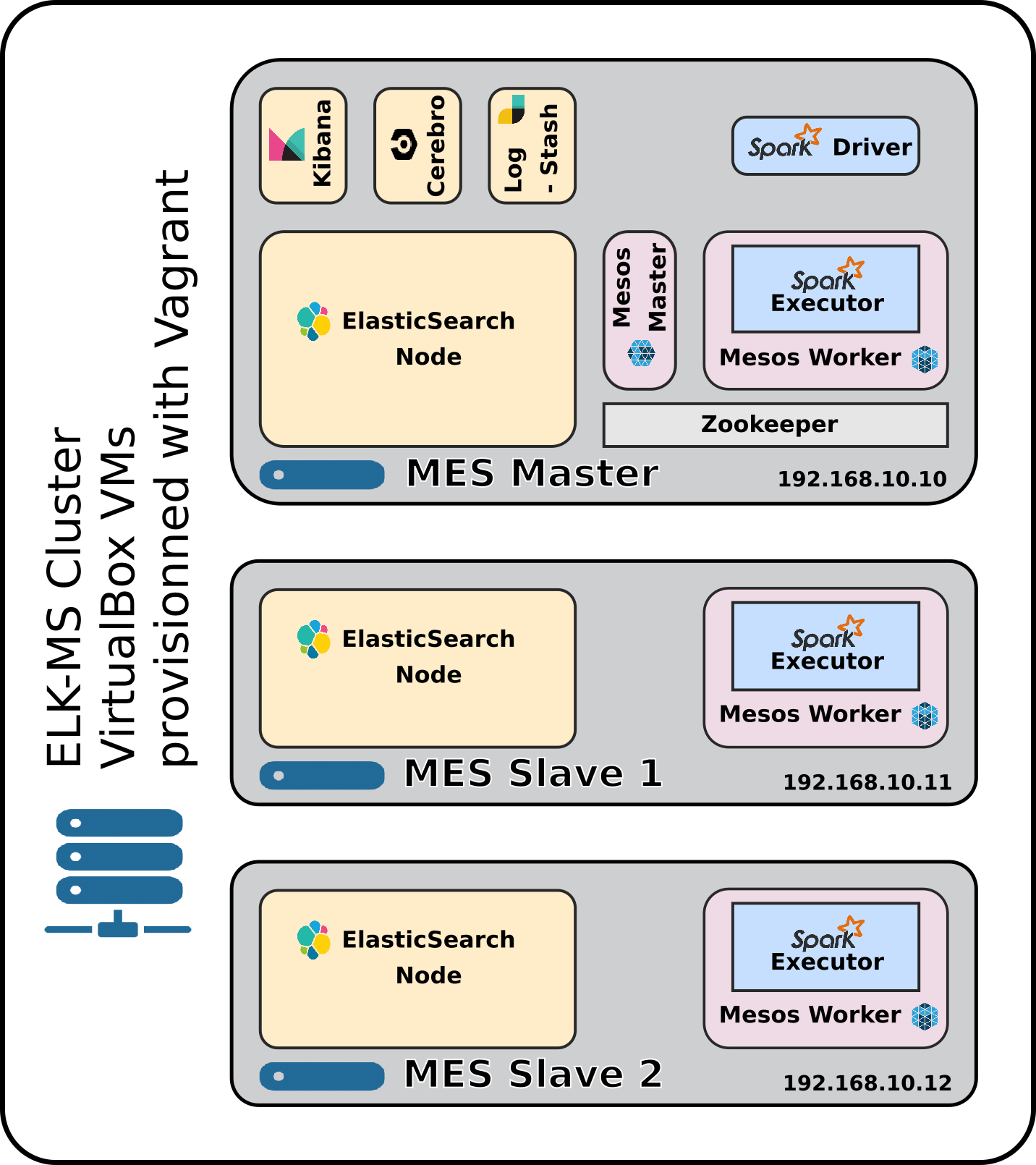
-
The master node, MES Master (for Mesos/Elasticsearch/Spark) is called
mes_master. It contains the full stack of software including the management UIs. The Master node is also a data node. -
The two data nodes, MES Slave X are called
mes_node1andmes_node2. They only provide an ElasticSearch instance and a Mesos worker instance to drive Spark Executors.
Having two possible Mesos Masters is not considered for now but the technical stack is deployed with this possibility wide open by using zookeeper to manage mesos masters.
3.2 The build system
The remainder of this section is a description of the niceideas_ELK-MS package build system and a presentation of the expected results.
3.2.1 Required Tools
First the build system is really intended to work on Linux, but would work as well on Windows except that vagrant commands need to be called directly.
But before digging into this, the following tools need to be installed and properly working on the host machine where the ELK-MS test cluster has to be built:
-
VirtualBox: is an x86 and AMD64/Intel64 virtualization solution.
The niceideas_ELK-MS package will build a cluster of nodes taking the form of VMs running on the host machine (the user computer). -
Vagrant: is a tool for building and managing virtual machine environments in a single workflow.
The niceideas_ELK-MS package uses Vagrant to build and manage the VMs without any user interaction required and to drive the provisioning scripts execution. -
vagrant-reload vagrant plugin is require to reload the machines after some changes applied by the provisionning scripts requiring a VM reboot.
See https://github.com/aidanns/vagrant-reload/blob/master/README.md.
3.2.2 Build System Project Layout
The niceideas_ELK-MS package structure, after being properly extracted in a local folder, is as follows:
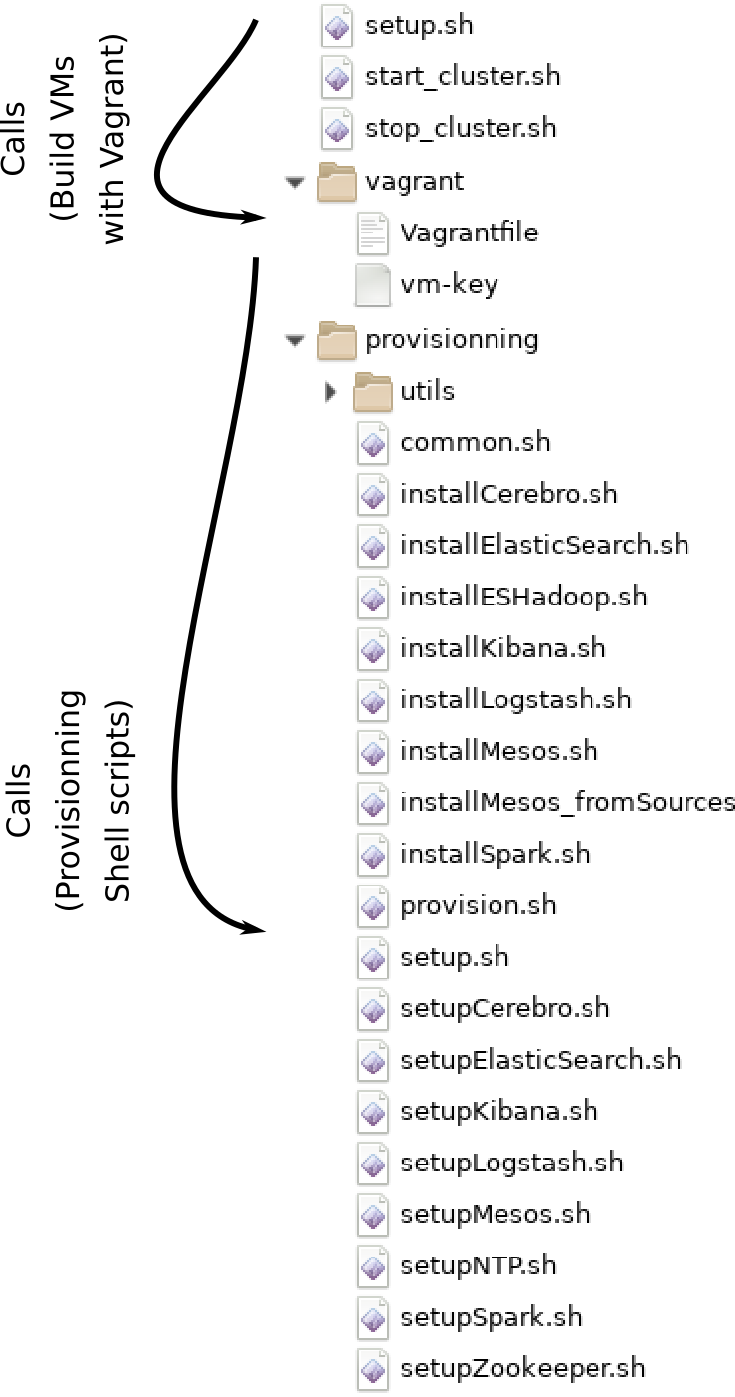
-
./setup.sh: basically takes care of everything by calling vagrant to build the 3 VMs -
./vagrant/VagrantFile: vagrant definition file to define the 3 VMs and the provisioning scripts -
./provisionning/*: the provisoning scripts. The entry point issetup.shthat calls each and every other script.
Rationality
In a DevOps world, there are better tools than shell scripts to proceed with VM or machine provisioning, such as Ansible, Chef, Puppet, etc.
But in my case, I want it to be possible for me to go on any VM, any machine and re-apply my configuration to Spark, Mesos, ElasticSearch or else by simply calling a shell script with a few arguments.
So even though there are more efficient alternatives, I kept shell scripts here for the sake of simplicity.
Building the ELK-MS test cluster on Windows
With VirtualBox and Vagrant properly installed on Windows, nothing should prevent someone from building the cluster on Windows.
But in this case, of course, the root scripts setup.sh, start_cluster.sh, stop_cluster.sh are not usable (or else cygwin ? MingW ?).
In this case, the user should call vagrant manually to build the 3 VMs mes_master, mes_node1 and mes_node2 as follows:
c:\niceideas_ELK-MS\vagrant> vagrant up mes_master ... c:\niceideas_ELK-MS\vagrant> vagrant up mes_node1 ... c:\niceideas_ELK-MS\vagrant> vagrant up mes_node2 ...
3.3 Calling the build system and results
Again, calling the build system to fully build the cluster, on Linux, is as simple as:
badtrash@badbook:/data/niceideas_ELK-MS/setup$ ./setup.sh
A full dump of the result of the setup.sh script is available here.
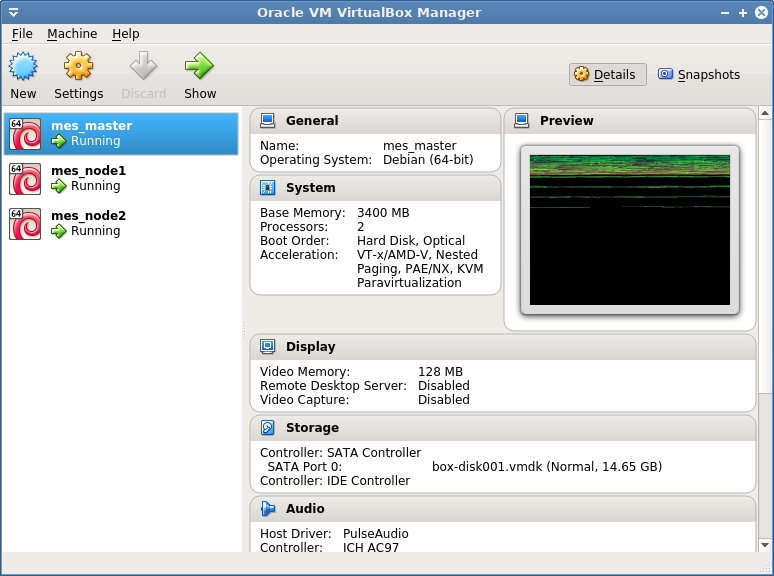
3.4 Testing the System
After calling the setup.sh script above, the 3 VMs are properly created, as one can check in VirtualBox:
In addition, the 4 UI applications should be available at following addresses (caution, the links below return to your cluster, not niceideas.ch):
- Cerebro on http://192.168.10.10:9000/
- Mesos Console on http://192.168.10.10:5050/
- Spark History Server on http://192.168.10.10:18080/
- Kibana on http://192.168.10.10:5601/
Cerebro: (http://192.168.10.10:9000/)
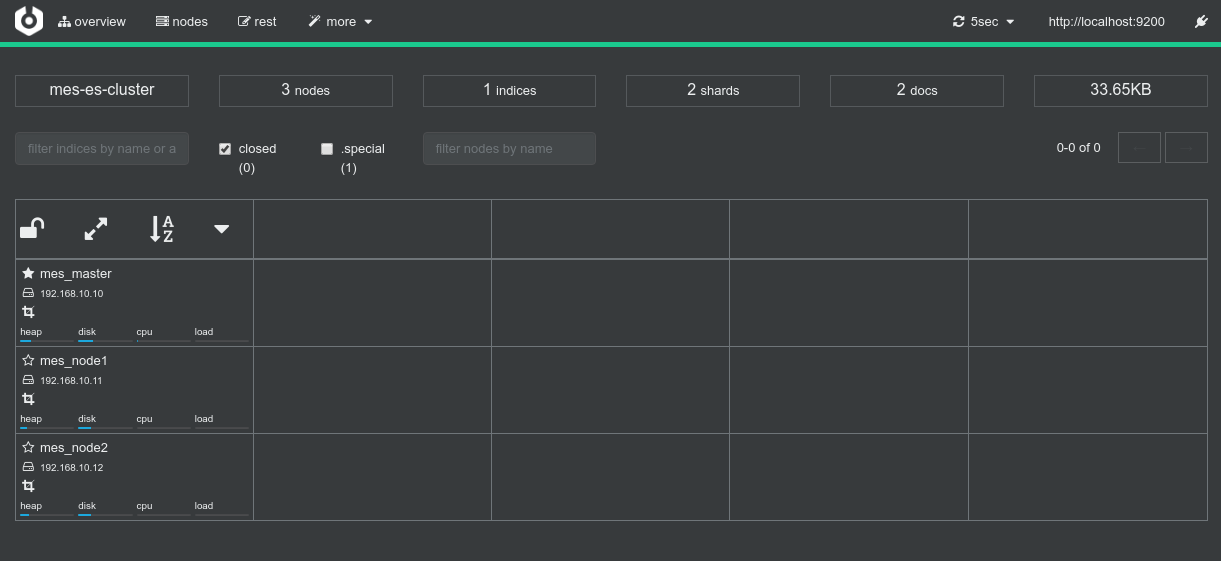
(One can see the 3 nodes available)
Mesos: (http://192.168.10.10:5050/)
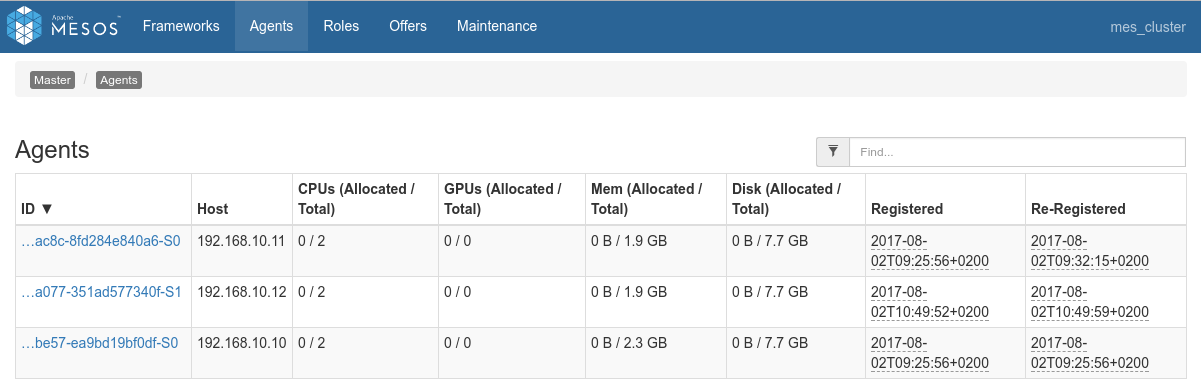
(One can see the 3 nodes available)
Spark History Server: (http://192.168.10.10:18080/)
Kibana: (http://192.168.10.10:5601/)
3.5 Tips & Tricks
This closes the presentation of the niceideas_ELK-MS package. The remainder of this article gives some hints regarding the configuration of the different software components.
Readers interested in understanding what the build system of niceideas_ELK-MS presented above does without the hassle of analyzing the setup scripts can continue reading hereunder.
Reader interested only in understanding the cluster layout and the concerns of the ES / Spark integration can move to the second article in this serie: ELK-MS - part II : assessing behaviour.
Killing a stuck job
Once in a while, for various reasons, a job gets stuck. In this case the easiest way to kill it is using the Spark Web console.
But wait, hold on, you just said above that such a console is not available when running through Mesos ?
Well actually, the Spark console is available as long as the spark job is alive ... which is the case, happily, when a spark job is stuck.
So one can follow the link provided by Mesos on the Spark console and use the usual kill link from there.
Spark fine grained scheduling by Mesos
When reading about Mesos fine grained scheduling of spark job, one might think it makes sense to give it a try ... don't!
Spark fine grained scheduling by Mesos is really really messed up.
One might believe that it helps concurrency and better resource allocation but it really doesn't, In practice what happens is that an amazing proportion of time is lost scheduling all the individual spark tasks, plus it often compromises co-location of data between ES and Spark.
It's even deprecated in the latest spark versions.
More information in this regards is available here: https://issues.apache.org/jira/browse/SPARK-11857.
4. Noteworthy configuration elements
The below presents the important configuration aspects taken care of by the provisioning scripts.
4.1 NTP
Related scripts from the niceideas_ELK-MS package are as follows:
- Configuration script:
setupNTP.sh
Just as with every big data or NoSQL cluster, having a shared common understanding of time in the cluster is key. So NTP needs to be properly set up.
On master mes_master
Sample portion from /etc/ntp.conf:
pool ntp1.hetzner.de iburst pool ntp2.hetzner.com iburst pool ntp3.hetzner.net iburst
On slaves mes_node1 and mes_node2
Sample portion from /etc/ntp.conf:
server 192.168.10.10 #enabling mes_master to set time restrict 192.168.10.10 mask 255.255.255.255 nomodify notrap nopeer noquery #disable maximum offset of 1000 seconds tinker panic 0
4.2 Zookeeper
Related scripts from the niceideas_ELK-MS package are as follows:
- Configuration script:
setupZookeeper.sh
Zookeeper is really only required when considering several Mesos master since in this case we need the quorum feature of zookeeper to proceed with proper election of the master and to track their state.
At the moment ELK-MS has only one Mesos master, but we'll make it production and HA ready by already setting up and using zookeeper.
On master mes_master
Sample portion from /etc/zookeeper/conf/zoo.cfg:
server.1=192.168.10.10:2888:3888
In addition, we need to set zookeeper master id in /etc/zookeeper/conf/myid.
Let's just put a single character "1" in it for now.
4.3 Elasticsearch
Related scripts from the niceideas_ELK-MS package are as follows:
- Installation script:
installElasticSearch.sh - Configuration script:
setupElasticSearch.sh - Systemd service file:
elasticsearch.service
There's not a whole lot of things to configure in ES. The installation and setup scripts are really just created a dedicated users, a whole bunch of folders and simlinks, etc.
The only important configuration elements are as follows:
On master mes_master
Sample portion from /usr/local/lib/elasticsearch-6.0.0/config/elasticsearch.yml :
# name of the cluster (has to be common) cluster.name: mes-es-cluster # name of the node (has to be unique) node.name: mes_master # Bind on all interfaces (internal and external) network.host: 0.0.0.0 # We're good with one node discovery.zen.minimum_master_nodes: 1 #If you set a network.host that results in multiple bind addresses #yet rely on a specific address for node-to-node communication, you #should explicitly set network.publish_host network.publish_host: 192.168.10.10
On slaves mes_node1 and mes_node2
Sample portion from /usr/local/lib/elasticsearch-6.0.0/config/elasticsearch.yml :
# name of the cluster (has to be common) cluster.name: mes-es-cluster # name of the node (has to be unique, this is for node1) node.name: mes_node1 # Bind on all interfaces (internal and external) network.host: 0.0.0.0 # We're good with one node discovery.zen.minimum_master_nodes: 1 # enabling discovery of master discovery.zen.ping.unicast.hosts: ["192.168.10.10"] #If you set a network.host that results in multiple bind addresses #yet rely on a specific address for node-to-node communication, you #should explicitly set network.publish_host # (this is for node1) network.publish_host: 192.168.10.11
4.4 Logstash, Kibana, Cerebro
Related scripts from the niceideas_ELK-MS package are as follows:
- Logstash Installation script:
installLogstash.sh - Logstash Configuration script:
setupLogstash.sh
- Cerebro Installation script:
installCerebro.sh - Cerebro Configuration script:
setupCerebro.sh - Cerebro Systemd service file:
cerebro.service
- Kibana Installation script:
installKibana.sh - Kibana Configuration script:
setupKibana.sh - Kibana Systemd service file:
kibana.service
There is really nothing specific to report in terms of configuration for these 3 tools.
4.5 Mesos
Related scripts from the niceideas_ELK-MS package are as follows:
- Installation script:
installMesos.sh - Configuration script:
setupMesos.sh - Mesos startup script:
mesos-init-wrapper.sh - Mesos Master Systemd startup file:
mesos-master.service - Mesos Slave Systemd startup file:
mesos-slave.service
The noteworthy configuration aspects are as follows.
On both master and slaves
The file /usr/local/etc/mesos/mesos-env.sh contains common configuration for both mesos-master and mesos-slave.
So we should create this file on every node of the cluster.
#Working configuration export MESOS_log_dir=/var/log/mesos #Specify a human readable name for the cluster export MESOS_cluster=mes_cluster #Avoid issues with systems that have multiple ethernet interfaces when the Master #or Slave registers with a loopback or otherwise undesirable interface. # (This is for master, put IP of the node) export MESOS_ip=192.168.10.10 #By default, the Master will use the system hostname which can result in issues #in the event the system name isn't resolvable via your DNS server. # (This is for master, put IP of the node) export MESOS_hostname=192.168.10.10
Then, the file /usr/local/etc/mesos/mesos-slave-env.sh configures mesos-slave.
Since we run a mesos-slave process on the mes_master machine as well, we define this file on every node of the cluster as well.
#Path of the slave work directory. #This is where executor sandboxes will be placed, as well as the agent's checkpointed state. export MESOS_work_dir=/var/lib/mesos/slave #we need the Slave to discover the Master. #This is accomplished by updating the master argument to the master Zookeeper URL export MESOS_master=zk://$MASTER_IP:2181/mesos
On master mes_master only:
The mesos-master process is configured by /usr/local/etc/mesos/mesos-master-env.sh:
#Path of the master work directory. #This is where the persistent information of the cluster will be stored export MESOS_work_dir=/var/lib/mesos/master #Specify the master Zookeeper URL which the Mesos Master will register with export MESOS_zk=zk://$192.168.10.10:2181/mesos # Change quorum for a greater value if one has more than one master # (only 1 in our case) export MESOS_quorum=1
4.6 Spark
Related scripts from the niceideas_ELK-MS package are as follows:
- Installation script:
installSpark.sh - Configuration script:
setupSpark.sh - Dynamic Allocation Configuration script:
setupSparkDynamicAllocation.sh - Spark History Server start wrapper:
start-spark-history-server-wrapper.sh - Spark History Server Systemd startup file:
spark-history-server.service - Spark Mesos Dispatcher start wrapper:
start-spark-mesos-dispatcher-wrapper.sh - Spark Mesos Dispatcher Systemd startup file:
spark-mesos-dispatcher.service
Aside from the specific startup wrappers and systemd service configuration files required for the Spark History Server and the Spark Mesos Dispatcher, the noteworthy configuration elements are as follows.
On both master and slaves
The file /usr/local/lib/spark-2.2.0/conf/spark-env.sh defines common environment variables required by spark workers and drivers.
So we should create this file on every node of the cluster (in addition the master also executes spark workers).
#point to your libmesos.so if you use Mesos export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/mesos-1.3.0/lib/libmesos.so #Important configuration directories export SPARK_CONF_DIR=/usr/local/lib/spark-2.2.0/conf export SPARK_LOG_DIR=/usr/local/lib/spark-2.2.0/logs
The file /usr/local/lib/spark-2.2.0/conf/spark-defaults.conf defines common configuration properties required by spark workers and drivers.
So we should create this file on every node of the cluster (since the master as well executes spark workers).
#Finding the mesos master through zookeeper spark.master=mesos://zk://$MASTER_IP:2181/mesos #Activating EventLog stuff (required by history server) spark.eventLog.enabled=true spark.eventLog.dir=/var/lib/spark/eventlog #Default serializer spark.serializer=org.apache.spark.serializer.KryoSerializer #Limiting the driver (client) memory spark.driver.memory=800m #Settings required for Spark driver distribution over mesos cluster #(Cluster Mode through Mesos Dispatcher) spark.mesos.executor.home=/usr/local/lib/spark-2.2.0/ #If set to true, runs over Mesos clusters in coarse-grained sharing mode, #where Spark acquires one long-lived Mesos task on each machine. #If set to false, runs over Mesos cluster in fine-grained sharing mode, #where one Mesos task is created per Spark task. #(Fine grained mode is deprecated and one should consider dynamic allocation #instead) spark.mesos.coarse=true #ElasticSearch setting (first node to be reached => can use localhost everywhere) spark.es.nodes=localhost spark.es.port=9200 es.nodes.data.only=false #The scheduling mode between jobs submitted to the same SparkContext. #Can be FIFO or FAIR. FAIR Seem not to work well with mesos #(FIFO is the default BTW ...) spark.scheduler.mode=FIFO #How long to wait to launch a data-local task before giving up #and launching it on a less-local node. spark.locality.wait=20s # Configuring dynamic allocation # (See Spark configuration page online for more information) spark.dynamicAllocation.enabled=true #(Caution here : small values cause issues. I have executors killed with 10s for instance) spark.dynamicAllocation.executorIdleTimeout=120s spark.dynamicAllocation.cachedExecutorIdleTimeout=300s # Configuring spark shuffle service (required for dynamic allocation) spark.shuffle.service.enabled=true
On master mes_master only
In the very same file /usr/local/lib/spark-2.2.0/conf/spark-defaults.conf, we add what is required for Spark History Server:
#For the filesystem history provider, #the directory containing application event logs to load. spark.history.fs.logDirectory=file:///var/lib/spark/eventlog #The period at which to check for new or updated logs in the log directory. spark.history.fs.update.interval=5s
4.7 ES-Hadoop
Related scripts from the niceideas_ELK-MS package are as follows:
- Installation script:
installESHadoop.sh
Nothing specific to report, basically the only thing to be done to install ES-Hadoop is to copy the spark driver elasticsearch-spark-20_2.11-6.0.0.jar to the spark jars folder /usr/local/lib/spark-2.2.0/jars/.
5. Conclusion
With all of the information above, you should be able to set up your own ElasticSearch / Mesos / Spark Cluster in no time.
Or simply use the niceideas_ELK-MS package to build a test cluster using one single command.
Now the next article in this serie, ELK-MS - part II : assessing behaviour will present the tests I did on this test cluster and the conclusions in terms of behaviour assessment.
I'm already telling you the big conclusion: Using ElasticSearch / Mesos / Spark for your Big Data Analytics needs is mind-joggling. It works really amazingly and supports a striking range of use cases while being a hundred times lighter than a plain old Hadoop stack both to setup and to operate.
Kuddos to the folks at Apache and at Elastic for making this possible.
Tags: big-data elasticsearch elk elk-ms kibana logstash mesos spark