
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part II : assessing behaviour
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:30PM in Big Data
Edited 2017-10-30: I was using ES 5.0.0 with Spark 2.2.0 at the time of writing the initial version of this article.
With ElasticSearch 6.x, and ES-Hadoop 6.x, the game changes a little. The Spark 2.2.0 Dynamic allocation system is now perfectly compatible with the way ES-Hadoop 6.x enforces data locality optimization and everything works just as expected.
This article is the second article in my serie of two articles presenting the ELK-MS Stack and test cluster.
ELK-MS stands for ElasticSearch/LogStash/Kibana - Mesos/Spark. The ELK-MS stack is a simple, lightweight, efficient, low-latency and performing alternative to the Hadoop stack providing state of the art Data Analytics features.
ELK-MS is especially interesting for people that don't want to settle down for anything but the best regarding Big Data Analytics functionalities but yet don't want to deploy a full-blend Hadoop distribution, for instance from Cloudera or HortonWorks.
Again, I am not saying that Cloudera and HortonWorks' Hadoops distributions are not good. Au contraire, they are awesome and really simplifies the overwhelming burden of configuring and maintaining the set of software components they provide.
But there is definitely room for something lighter and simpler in terms of deployment and complexity.
The first article - entitled - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
This second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses the challenges and constraints on this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Summary
- 1. Introduction
- 2. Testing framework
- 3. Conclusions from assessment tests
- 4. Further work
- 5. Details of Tests
- 6. References
1. Introduction
The reader might want to refer to the Introduction of the first article in the serie.
Summarizing it, this article is about assessing the behaviour of the ELK-MS Stack using the test cluster introduced in the first article.
Especially two questions need to be answered:
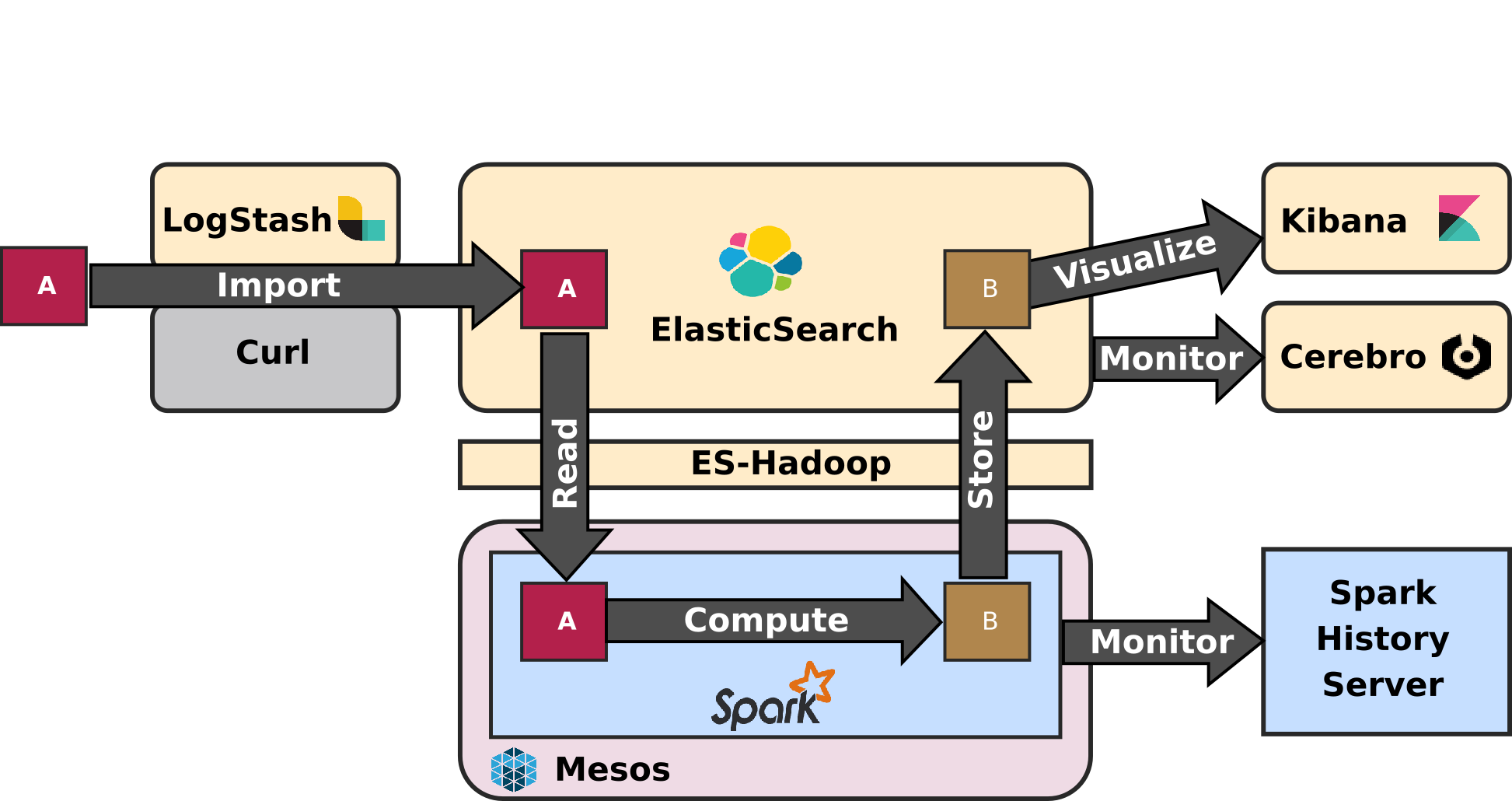
- First, how does data-locality optimization work using ES-Hadoop to read data from ElasticSearch to Spark? On a large cluster, achieving Data Locality is the sinews of war. Before considering the ELK-MS stack as an actual alternative to a more standard Hadoop stack, assessing the sound behaviour and a good respect to data locality of the software stack is not optional.
- Second, how does Mesos schedule spark executors and how does it impact data-locality? Mesos needs to be an effective alternative to YARN when it comes to dispatching spark executors while still taking into account data-locality.
These are the two main objectives of the tests for which I am reporting the conclusions hereafter, as well as a few other points.
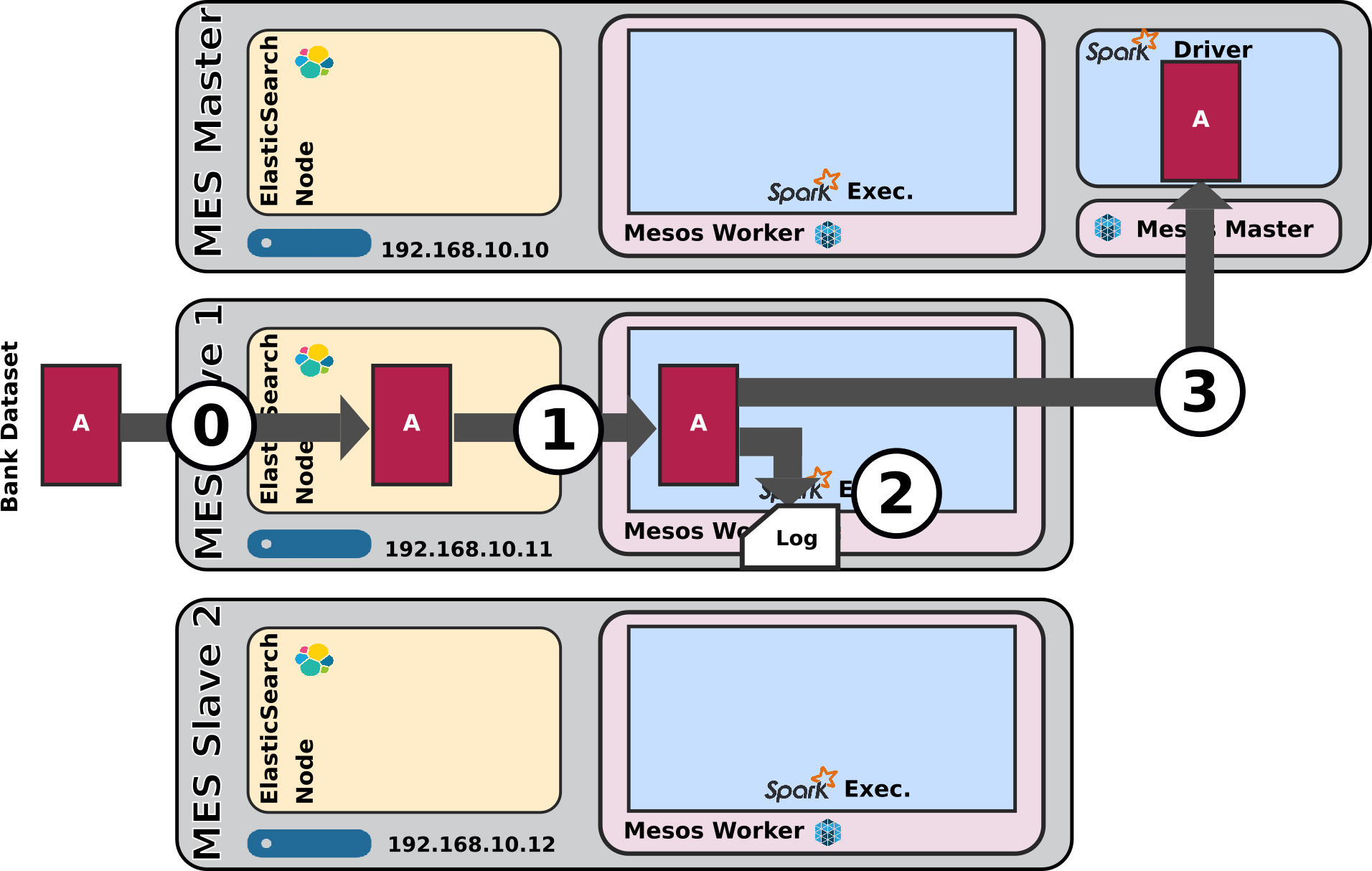
This article is not about testing Spark or Mesos themselves, it's really about testing how ElasticSearch / Mesos / Spark behave all together to support the application architecture from the schema above.
In addition, in contrary to the state of the art on Spark, in my current company, we are not going to be using Java or Scala to implement the spark processing logic, we are going to use python.
The reason for this is simple: our Data Scientists know python, period. They do not know Java, they are not willing to learn Scala. Our Data Scientist know R and python and as such as Head of R&D I have made python our standard language for our Data Analytics algorithms (not that I don't like R, au contraire, but I believe python is at the right intersection between Data Science and Engineering).
Choosing python as processing language has an impact when it comes to programming Spark, the support of python is, as a matter of fact, a little under the support of Scala and Java.
Now all of the above give this article is rationality: programming an ElasticSearch / Mesos / Spark Task with python is something that suffers from really little documentation available.
In the previous article I wanted to present how to set things up as well as share my setup tools and in this article I want to present how to use it, it's behaviour and share some short sample programs in the form of my tests package.
2. Testing Framework
I would summarize the specificities of the usage of Spark in my current company as follows:
- Data analytics use cases are implemented in pyspark and python scripts and not native Scala or Java APIs
- The input data and results are stored in ElasticSearch, not in HDFS
- Spark runs on Mesos and not the more standard YARN on Hadoop.
So I needed a way to test and assess that all of this is working as expected and that the behaviour of the Mesos/Spark stack, both from the perspective of concurrency and respect of data-locality in between ES nodes and Spark nodes, is sound.
This is the objective of the niceideas_ELK-MS-TEST framework.
I am presenting this framework, the approach and the tests it contains herunder.
The test framework is available for download here.
2.1 niceideas ELK-MS TEST
The niceideas ELK-MS TEST package structure, after being properly extracted in a local folder, is as follows:
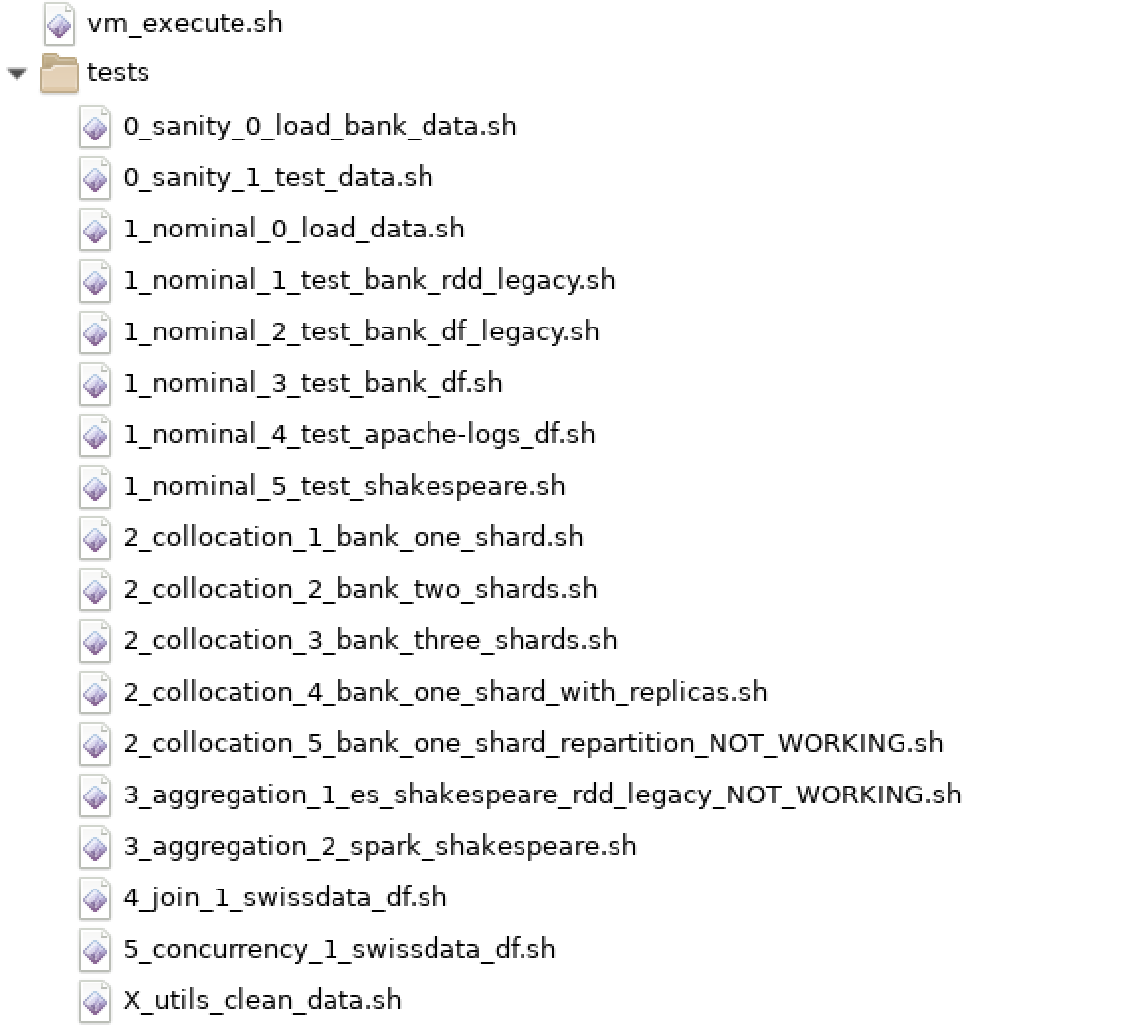
-
./vm_execute.sh: this is the script one calls on the host machine to launch a test. The test to be executed should be given as argument. -
./tests/*: the test scenario scripts.
Executing a test on the ELK-MS Test cluster, is simply done, for instance, by the following command:
badtrash@badbook:/data/niceideas_ELK-MS-TEST$ ./vm_execute.sh scenarii/5_concurrency_1_swissdata_df.sh
This would execute the test 5_1 and show the spark driver logs on the console.
2.2 Test Scenario Script
Each and every test scenario script has the very same structure :
- Create an ad'hoc shell script taking care of downloading a data set and loading in into ElasticSearch
- Execute that Data Loading Shell script
- Create an ad'hoc python script taking care of implementing the Spark processing
- Execute the Data Processing Python script
For instance, a test scenario X_test_Y_variant.sh would have following structure:
#!/bin/bash # 1. Create Data Ingestion script # ----------------------------------------------------------------------------- cat > X_test_Y_variant_do.sh <<- "EOF" #!/bin/bash # echo commands set -x # ... # Various shell commands to proceed with loading the data in ES # ... # turn off command echoing set +x EOF # 2. Exexcute Data Ingestion Script # ----------------------------------------------------------------------------- bash X_test_Y_variant_do.sh if [[ $? != 0 ]]; then echo "Script execution failed. See previous logs" exit -1 fi # 3. Create pyspark script # ----------------------------------------------------------------------------- cat > X_test_Y_variant.py <<- "EOF" from pyspark import SparkContext, SparkConf from pyspark.sql import SQLContext # Spark configuration conf = SparkConf().setAppName("ESTest_X_Y") # SparkContext and SQLContext sc = SparkContext(conf=conf) sqlContext = SQLContext(sc) # ... # Various spark processing commands # ... EOF # 4. Exexcute pyspark script # ----------------------------------------------------------------------------- spark-submit X_test_Y_variant.py if [[ $? != 0 ]]; then echo "Script execution failed. See previous logs" exit -1 fi
This key point of these scripts is that they are self contained and idempotent. They make no assumption about the state of the ELK-MS cluster before and they always start by cleaning all the data before reloading the data required for the tests.
2.3 Used Dataset
All the tests scenarii from the niceideas ELK-MS TEST package used either one of the following datasets:
- Bank Dataset: from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip - a dataset of financial accounts with owner and balance information.
- Shakespeare Dataset: from https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json - the complete work of Shakespeare, every line of every speech.
- Apache logs Dataset: from https://download.elastic.co/demos/kibana/gettingstarted/logs.jsonl.gz - a set or an apache web server log files.
-
Swiss AirBnB: two datasets in fact:
- from http://niceideas.ch/mes/swissairbnb/tomslee_airbnb_switzerland_1451_2017-07-11.csv : the list of AirBnB offers in Switzerland as of July 2017.
- from http://niceideas.ch/mes/swissairbnb/swisscitiespop.txt : the list of swiss cities with population and geoloc information.
The last dataset, related to swiss AirBnB offers and cities information is required to test the behaviour of joins on Spark.
The other datasets represent different volumes and enable us to test various aspects.
2.4 Test purposes
The tests from the niceideas ELK-MS TEST package are presented in details with all results in section 5. Details of Tests.
Before presenting the conclusions inferred from these tests in the next section, this is a short summary of the purpose of every family of tests:
- Nominal tests - assess how the various kinds of APIs of Spark are used to read data from ES: the RDD API, the legacy DataFrame API (SQLContext) and the new DataFrame API (SQLSession).
- Data-locality tests - assess how data-locality optimization between ES and Spark works and to what extent.
- Aggregation tests - how aggregation on ES data works.
- Join tests - how joining two data frames coming from ES works.
- Concurrency tests - how does Mesos / Spark behave when running several jobs at a time.
Again, the section 5. Details of Tests presents each and every test in details, along with the screenshots of Cerebro, Spark History Server, the logs of the spark driver, etc.
3. Conclusions from assessment tests
I am reporting in this section already the conclusions that can be taken from the tests executed in the scope of this work.
The conclusions and important information are presented in this early section already, preventing the reader from the requirement to read all the individual tests presented in details in the next section.
3.1 ES-Hadoop and Data-locality enforcement
Data locality
Data locality is how close data is to the code processing it. There are several levels of locality based on the data’s current location. In order from closest to farthest:
-
PROCESS_LOCALdata is in the same JVM as the running code. This is the best locality possible -
NODE_LOCALdata is on the same node. Examples might be in HDFS on the same node, or in another executor on the same node. This is a little slower than PROCESS_LOCAL because the data has to travel between processes -
NO_PREFdata is accessed equally quickly from anywhere and has no locality preference -
RACK_LOCALdata is on the same rack of servers. Data is on a different server on the same rack so needs to be sent over the network, typically through a single switch -
ANYdata is elsewhere on the network and not in the same rack Spark prefers to schedule all tasks at the best locality level, but this is not always possible. In situations where there is no unprocessed data on any idle executor, Spark switches to lower locality levels. There are two options: a) wait until a busy CPU frees up to start a task on data on the same server, or b) immediately start a new task in a farther away place that requires moving data there.
What Spark typically does is wait a bit in the hopes that a busy CPU frees up. Once that timeout expires, it starts moving the data from far away to the free CPU.
The setting indicating how long it should wait before moving the processing elsewhere is spark.locality.wait=10s.
ES-Hadoop
Data-locality enforcement works amazingly under nominal conditions. ES-Hadoop makes the Spark scheduler understand the topology of the shards on the ES cluster and Spark dispatches the processing accordingly. Mesos doesn't interfere in this regards.
But again, it works only under nominal conditions.
As indicated above, there can be several factors compromising Data-locality:
-
First, imagine that at resource allocation time the Mesos cluster is heavily loaded. Spark will wait for
spark.locality.wait=10strying to get the processing executed on the node where ES stored the target data shard.
But if in this period the node doesn't become free, spark will move the processing elsewhere. -
The second case it not anymore related to spark, but to ElasticSearch. Imagine that at the very moment the spark executor submits the request to ES (through the ES-Hadoop connector), the co-located ES node is busy doing something else (answering another request, indexing some data, etc.).
In this case, ES will delegate the answering of the request to another node and local data-locality is broken.
3.2 Spark coarse grained scheduling by Mesos vs. Fine Grained
In Coarse Grained scheduling mode, the default, Mesos considers spark only at the scale of the required spark executor processes. All Mesos knows about spark is the executor processes on the nodes they are running. Mesos knows nothing of Spark's jobs internals such as stages and tasks.
In addition, static allocation makes Mesos Job pretty easy: try to allocate as many resources from the cluster to spark executors for pending jobs as are available. This has the following consequences:
- First, if a job is submitted to the cluster at a moment when the cluster is completely free, the job will be allocated the whole cluster. If another job comes even only just a few seconds after, it will still need to wait for the cluster to be freed by the first job, and that will happen only when the first job completes.
- Second, if several jobs are waiting to be executed, when the cluster is freed, Mesos will allocate the cluster resources evenly to each and every job. Now imagine that all these jobs are short-lived jobs and only one of them is a long-lived job. At allocation time (static allocation), that long-lived job got only a small portion of the cluster. Even if very soon the cluster becomes free, that job will still need to complete its execution on his small portion, making most of the cluster unused.
Historically, Mesos on Spark can benefit from a Fine Grained scheduling mode instead, where Mesos will schedule not only spark executors on nodes in a rough fashion but really each and every individual spark task instead.
In regards to data-locality optimization, this doesn't seem to have any impact.
In regards to performance on the other hand, Fine Grained scheduling mode really messes performances completely.
The thing is that Mesos requires quite some time to negotiate with the resources providers. If that negotiation happens for every individual spark tasks, a huge amount of time is lost and eventually the impact on performance is not acceptable.
For this reason (and others), the Fine Grained scheduling mode is deprecated: https://issues.apache.org/jira/browse/SPARK-11857
3.3 Spark Static Resource Allocation vs. Dynamic Allocation
By default, Spark's scheduler uses a Static Resource Allocation system. This means that, at the job (or driver) initialization time, Spark, with the help of Mesos in this case, will decide what resource from the Mesos cluster can be allocated to the job. This decision is static, meaning that once decided the set of resources allocated to the job will never change in its whole life regardless of what happens on the cluster (other / additional nodes becoming free, etc.)
This has the consequences listed above in the previous section, the whole cluster is allocated to a single job, further jobs need to wait, etc. and as such it's not very optimal.
Now of course Spark provides a solution to this, the Dynamic Allocation System.
And this is where Spark gets really cool. With Dynamic Allocation, the Spark / Mesos cluster is evenly shared between multiples jobs requesting execution on the cluster regardless of the time of appearance of the jobs.
And with ES-Hadoop 6.x, the Dynamic allocation system is perfectly able to respect the locality requirements communicated by the elastic-search spark connector and respects them as much as possible
3.3.1 ES-Hadoop 5.x and Spark 2.2
With ES-Hadoop version 5.x, the way the elasticsearch-spark connector was enforcing data locality was incompatible with Spark 2.2.0 and as such But unfortunately, when using Dynamic Allocation, Spark simply doesn't take into consideration ES-Hadoop's requirements regarding data locality optimization anymore.
Without going into details, the problem comes from the fact that ES-Hadoop makes spark request as many executors as shards and indicates as preferred location the nodes owning the ES shards.
But Dynamic allocation screws all of this by allocating executors only one after the other (more or less) and only after monitoring evolutions of the job processing needs and the amount of tasks created. In no way does the dynamic allocation system give any consideration for ES-Hadoop requirements.
3.3.2 ES-Hadoop 6.x
As indicated in the release notes of the ElasticSearch-Hadoop connector 6.0.0, the ElasticTeam has added support for Spark 2.2.0. This support has fixed the messing up with Dynamic Allocation problem that was suffering ES-Hadoop 5.x.
Now even with Dynamic Allocation properly enables, which is a requirement for us in order to optimize the Mesos Cluster resources consumption, Data Locality os optimized and properly enforced everywhen possible.
3.4 Latency regarding Python instantiation
Executing some tasks in Python takes time in comparison to executing tasks natively in Java or Scala. The problem is that spark tasks in python require to launch the individual task processing in seperate process than the Spark JVM. Only Java and Scala Spark processings run natively in the Spark JVM.
This problem is not necessarily a big deal since the DataFrame or RDD APIs exposed to python pyspark scripts are actually implemented by Scala code underneath, they resolve to native Scala code.
There is one noticeable exception in this regards: UDF (User Defined functions) implemented in python. While this is very possible, it should be avoided at all cost.
One can very well still use pyspark but write UDF in Scala.
- An explanation of this problem : https://fr.slideshare.net/SparkSummit/getting-the-best-performance-with-pyspark
- UDF in Scala : http://aseigneurin.github.io/2016/09/01/spark-calling-scala-code-from-pyspark.html
3.5 Other ES-Hadoop concerns
Repartitioning
I couldn't find a way to make repartitioning work the way I want, meaning re-distributing the data on the cluster in order to scale out the further workload.
I am not saying there is no way, just that I haven't found one so far.
As such, a sound approach regarding initial sharding in ES should be adopted. One should take into consideration that a priori, initial sharding may well drive the way Spark will be able to scale the processing out on the cluster.
While creating by default one shard per node in the cluster would definitely be overkill, the general idea should tend in this direction.
ES level aggregations
It's simply impossible to forge a query from Spark to ElasticSearch through ES-Hadoop that would make ElasticSearch compute aggregation and returning them instead of the raw data.
Such advanced querying features are not available from spark.
The need is well identified but it remains Work in Progress at the moment: https://github.com/elastic/elasticsearch-hadoop/issues/276.
3.6 Other concerns
Spark History Server
Running Spark in Mesos, there is no long-lived Spark process. Spark executors are created when required by Mesos and the Mesos master and slave processes are the only long lived process on the cluster in this regards.
As such, the Spark Application UI (on ports 4040, 4041, etc.) only live for the time of the Spark processing. When the job is finished, the Spark UI application vanishes.
For this reason, Spark provides an History server. The installation and operation of the History Server is presented in the first article of this serie : ELK-MS - part I : setup the cluster.
Interestingly, that history server supports the same JSON / REST API that the usual Spark Console, with only a very few limitations.
For instance, one can use the REST API to discover about the Application-ID of running jobs in order to kill them (whenever required). For this, simply list the jobs and find out about those that have "endTimeEpoch" : -1, meaning the application is still alive:
curl -XGET http://192.168.10.10:18080/api/v1/applications
Limitations of the ELK-MS stack
As stated in the previous article, ElasticSearch is not a distributed filesystem, it's a document-oriented NoSQL database.
There are situations where a distributed filesystem provides interesting possibilities. Those are not provided by the ELK-MS stack as is. It would be interesting to test Ceph on Mesos for this. See http://tracker.ceph.com/projects/ceph/wiki/Ceph-mesos.
4. Further work
I am still considering some next steps on the topic of the ELK-MS stack testing since there are still a few things I would like to test ot assess:
In a raw fashion:
- Find out about how to set maximum nodes booked by Mesos for a single spark job in order to avoid fully booking the cluster.
-
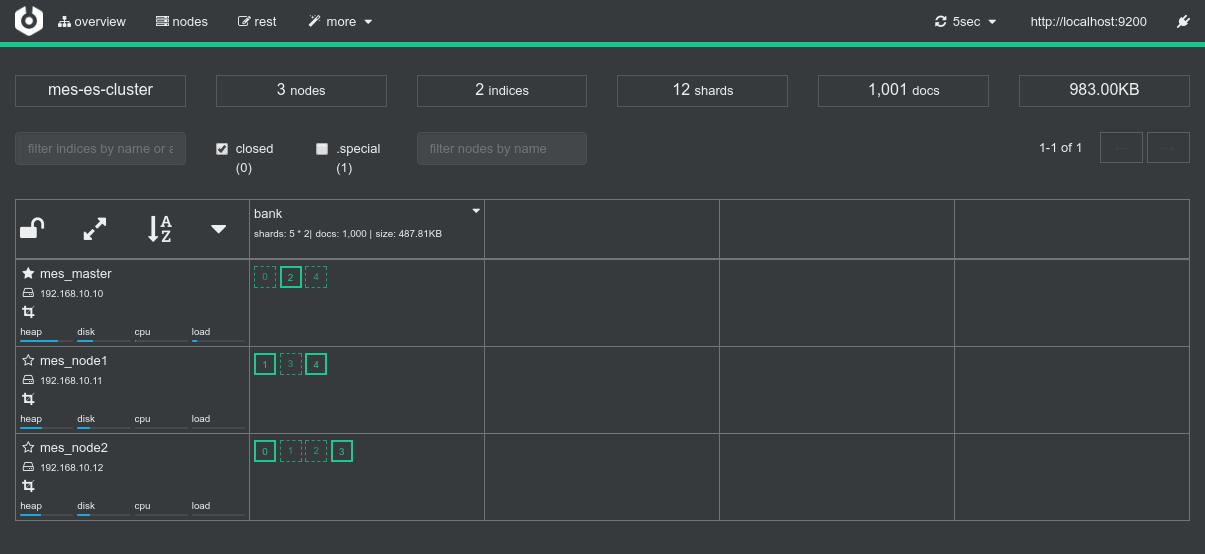
ElasticSearch on mesos
- This seems quite obvious. I expect the overall cluster performance to be way better if Mesos and ES don't compete with each other for hardware resources on nodes.
- There are workaround of course, such as configuring Mesos to avoid using all the CPUs of a node. But that will never be as efficient as letting Mesos distribute the global workload.
- Find a way for repartitioning to work the way I intend it: data should get redistributed across the cluster!
- Give Spark Streaming a try to reduce latency.
-
Try FAIR Spark scheduler and play with it.
- I got satisfying results using spark FIFO scheduler in terms of concurrency and haven't seen the need to change to FAIR.
- It really seems Mesos takes care of everything and I do really not see what the FAIR scheduler can change but I want to be sure.
- There are some chances that this makes me rewrite this whole article ... in another article.
-
Ceph integration on Mesos for binary files processing.
- How to integrate Ceph and spark ? Here as well very little documentation seems to be available.
- I found pretty much only this : https://indico.cern.ch/event/524549/contributions/2185930/attachments/1290231/1921189/2016.06.13_-_Spark_on_Ceph.pdf
-
What about HDFS on Mesos ?
- I would want to give it a try even though I am really rather considering Ceph for the use cases ElasticSearch forbids me to address.
- The thing is that Ceph integrates much better in the UNIX unified filesystem than HDFS
- Even though there is an approach to reach same level of integration with HDFS based on Fuse https://wiki.apache.org/hadoop/MountableHDFS. But that is still limited (doesn't support ownership informations for now)
5. Details of Tests
This very big section now presents each and every tests in details, along with the results in the form the the logs of the script (data feeding and spark driver logs), the screenshots of the UI applications (Cerebro, Mesos Console, Spark History Server).
The conclusions from the individual tests have been reported in the global 3. Conclusions from assessment tests section above.
5.1 Nominal Tests
Nominal tests - assess how the various kinds of APIs of Spark are used to read data from ES: the RDD API, the legacy DataFrame API (SQLContext) and the new DataFrame API (SQLSession).
5.1.1 Legacy RDD API on bank dataset
Test details
- Test Script:
1_nominal_1_test_bank_rdd_legacy.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: see how Spark's RDD API can be used to fetch data from ElasticSearch and how sharding in ES impacts executors layout on the cluster
Relevant portion of spark Script
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
# Spark configuration
conf = SparkConf().setAppName("ESTest_1_1")
# SparkContext and SQLContext
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
# Simplest possible query
q = "?q=*"
es_read_conf = {
"es.resource" : "bank",
"es.query" : q
}
es_rdd = sc.newAPIHadoopRDD(
inputFormatClass="org.elasticsearch.hadoop.mr.EsInputFormat",
keyClass="org.apache.hadoop.io.NullWritable",
valueClass="org.elasticsearch.hadoop.mr.LinkedMapWritable",
conf=es_read_conf)
es_df = sqlContext.createDataFrame(es_rdd)
# I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count : THIS IS FUNNY :
# it relaunches the whole Distributed Data Frame Processing
print ("Fetched %s accounts (re-computed)") % es_df.count()
# Print count
print ("Fetched %s accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 1_nominal_1_test_bank_rdd_legacy.log
- Screenshots from the various admin console after the test execution:
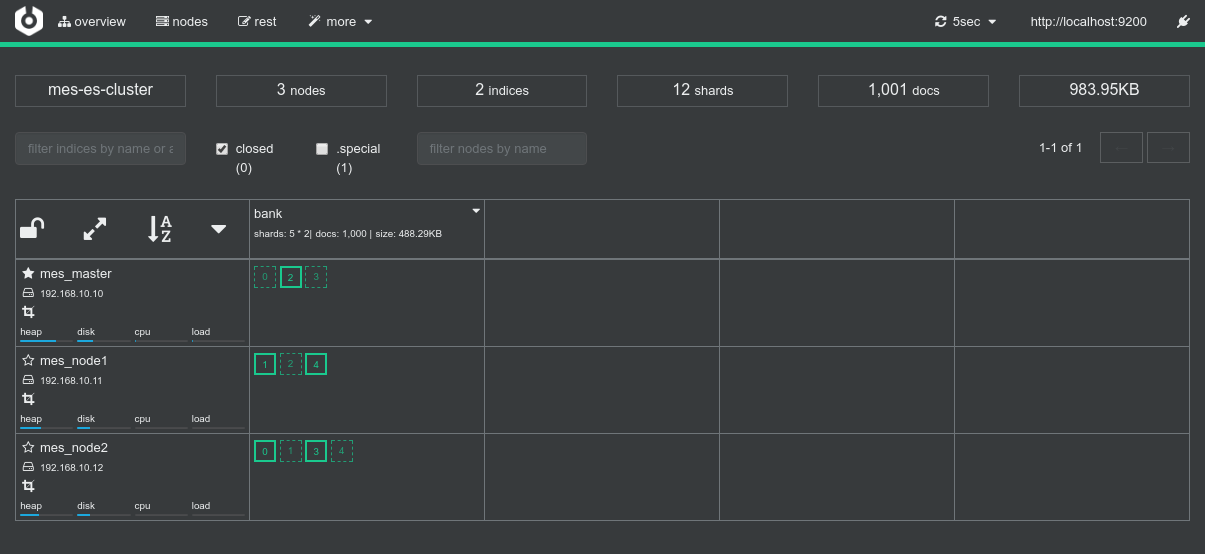
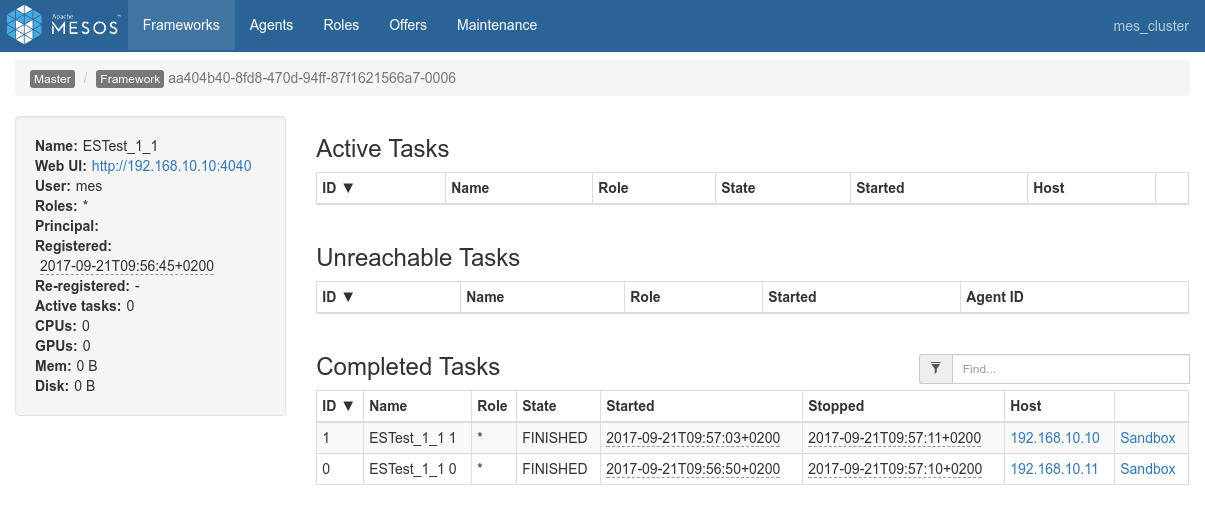
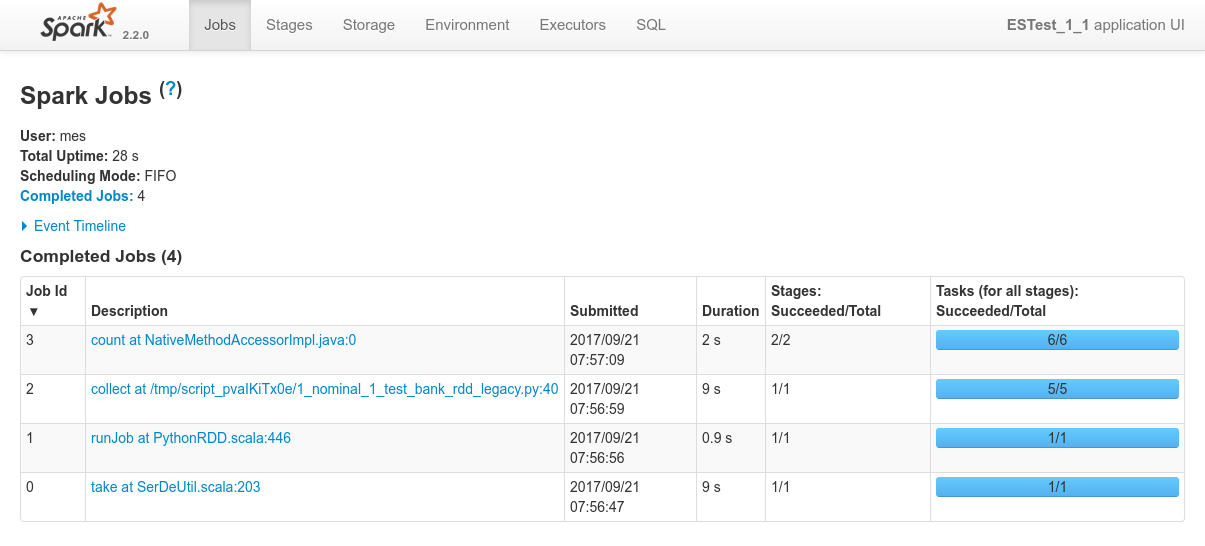
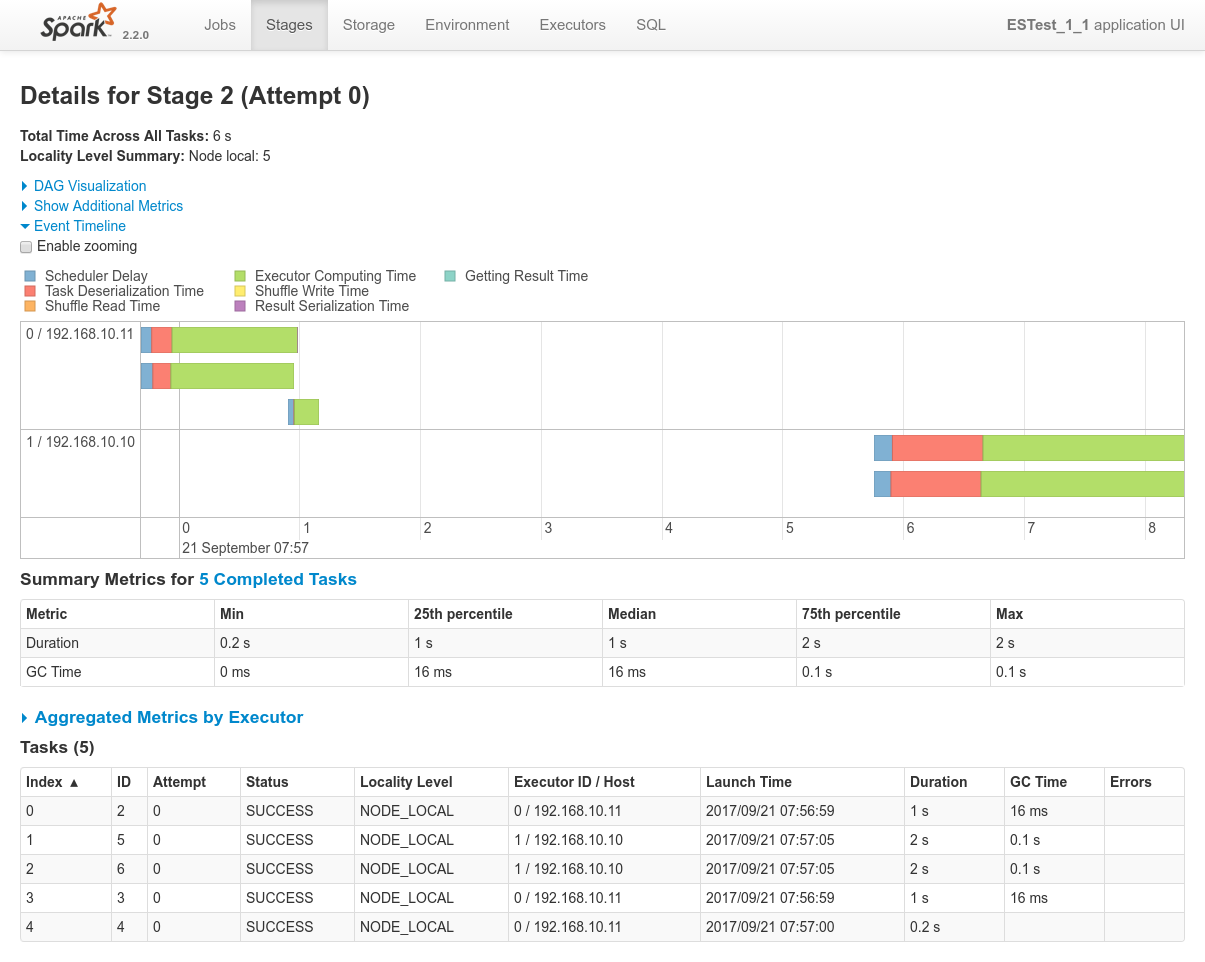
Conclusions
-
Spark can read data from ElasticSearch using the ES-Hadoop connector and the RDD API really out of the box.
One just needs to configure a few settings to thenewAPIHadoopRDDAPI:inputFormatClass="org.elasticsearch.hadoop.mr.EsInputFormat"keyClass="org.apache.hadoop.io.NullWritable"valueClass="org.elasticsearch.hadoop.mr.LinkedMapWritable"
-
Mesos spreads the workload on the cluster efficiently.
- This test was run alone on the cluster
- 2 nodes are sufficient to run the job since, thanks to replicas two nodes have actually all the shards
- Mesos creates a dedicated spark executor on each of the 2 nodes
- Sparks then successfully distribute the RDD on the 2 executors
-
Data-locality optimization works out of the box.
- There are 5 shards in ElasticSearch, which, with replicas, are well spread on the cluster
- Mesos / Spark dispatches the workload efficiently since it creates 5 RDD partitions for the 5 shards, each and every of them respecting data locality (
NODE_LOCAL) and as such respecting the requirements given by the ES-Hadoop connector.
5.1.2 Legacy DataFrame API on bank dataset
Test details
- Test Script:
1_nominal_2_test_bank_df_legacy.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: see how Spark's legacy DataFrame API can be used to fetch data from ElasticSearch and how sharding in ES impacts executors layout on the cluster
Relevant portion of spark Script
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
# Spark configuration
conf = SparkConf().setAppName("ESTest_1_2")
## !!! Caution : this is pre 2.0 API !!!
# SparkContext and SQLContext
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
es_df = sqlContext.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count : THIS IS FUNNY :
# it relaunches the whole Distributed Data Frame Processing
print ("Fetched %s women accounts (re-computed)") % es_df.count()
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 1_nominal_2_test_bank_df_legacy.log
- Screenshots from the various admin console after the test execution:
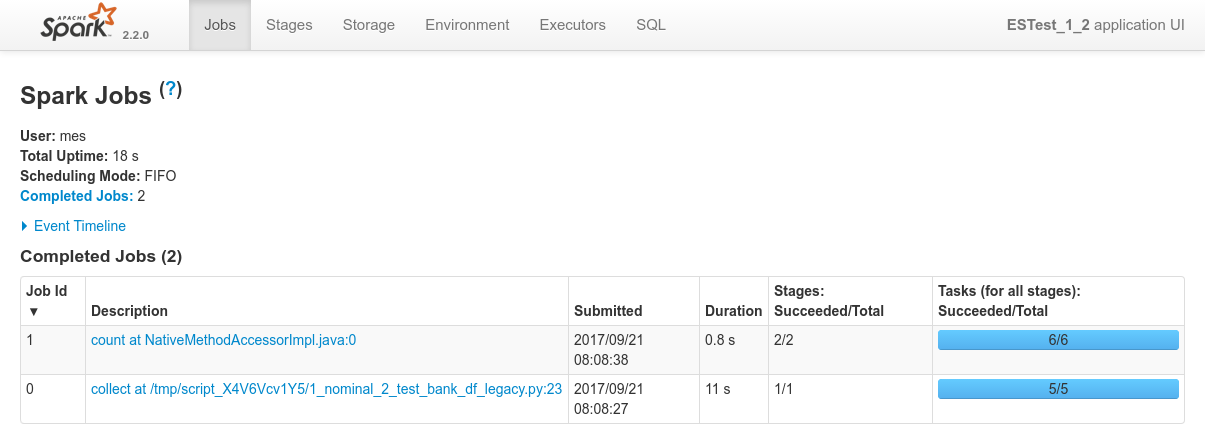
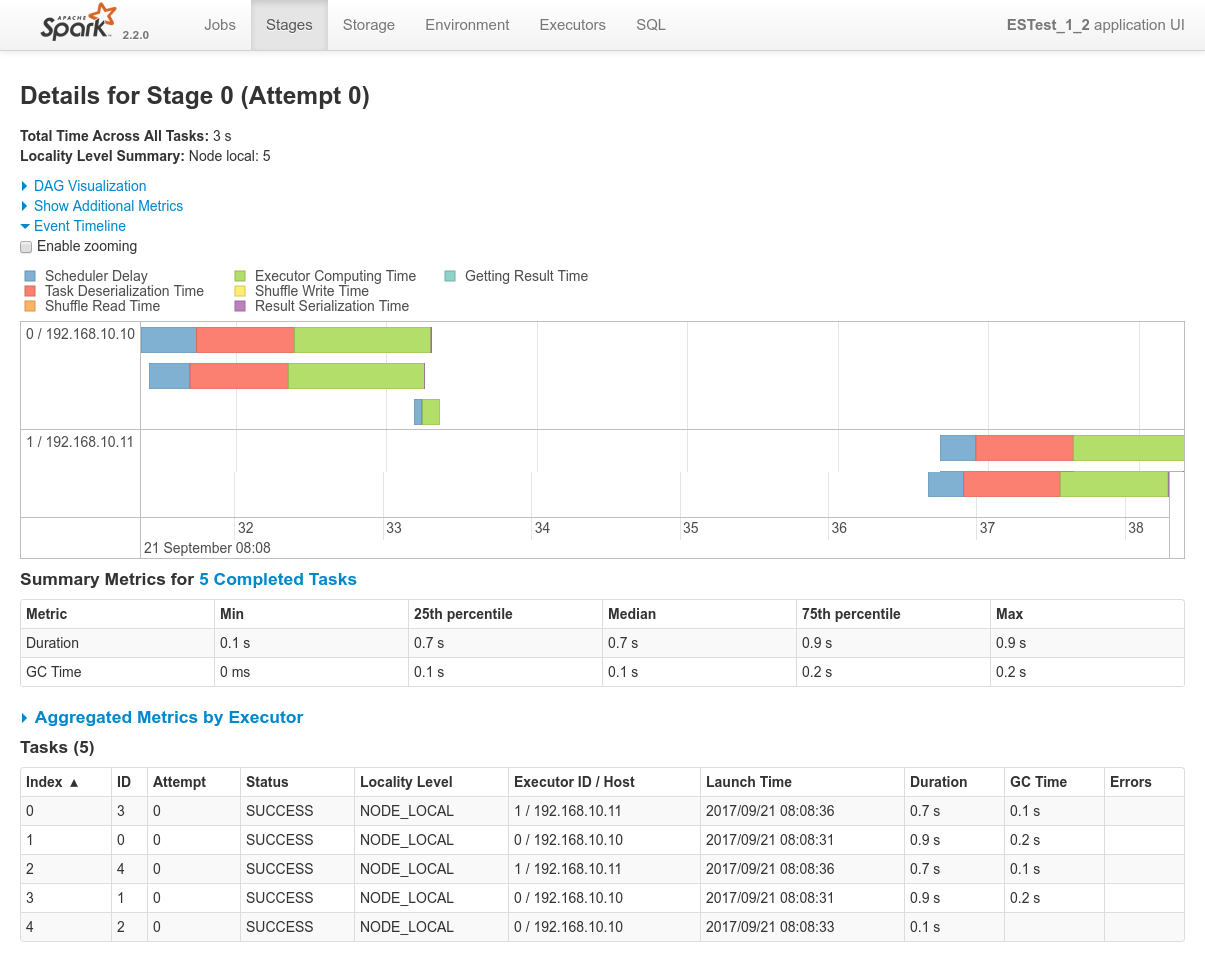
Conclusions
-
Spark can read data from ElasticSearch using the ES-Hadoop connector and the Legacy DataFrame API (SQLContext) really out of the box.
The single configuration required isformat("org.elasticsearch.spark.sql") on theSQLContextAPI -
Here as well, the Dynamic allocation system allocates nodes to the job one after the other.
After two nodes alolocated to the job, all shards (thx to replicas) become available locally and data localiy optimization can be satisfied without any other node required. The job executes on these 2 nodes. - In this case, as seen on result_1_2_job_0_stage_0.png, spark successfully respects data locality as well.
5.1.3 DataFrame API on bank dataset
Test details
- Test Script:
1_nominal_3_test_bank_df.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: see how Spark's New (>= 2.0) DataFrame API can be used to fetch data from ElasticSearch and how sharding in ES impacts executors layout on the cluster
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_1_3")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count : THIS IS FUNNY :
# it relaunches the whole Distributed Data Frame Processing
print ("Fetched %s women accounts (re-computed)") % es_df.count()
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 1_nominal_3_test_bank_df.log
- Screenshots from the various admin console after the test execution:
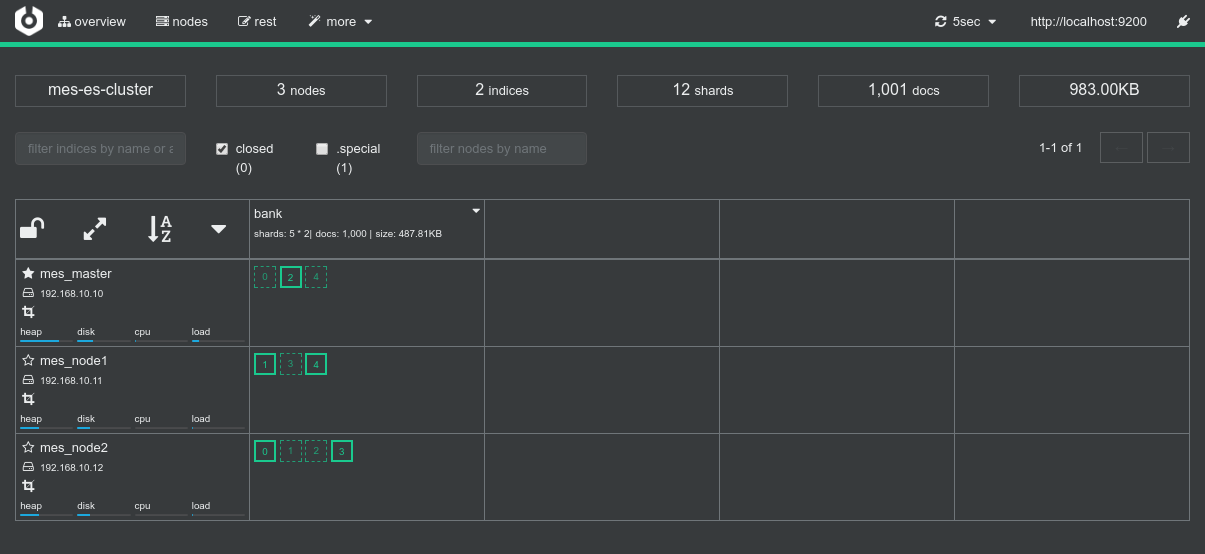
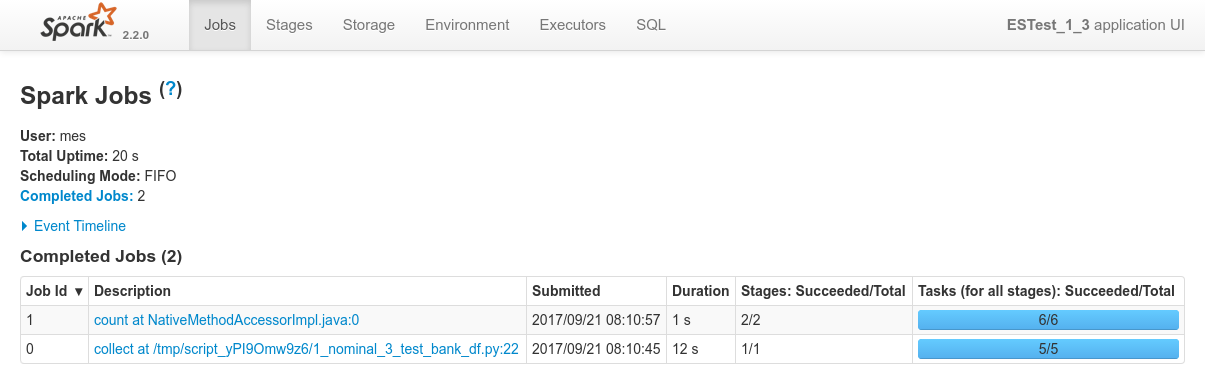
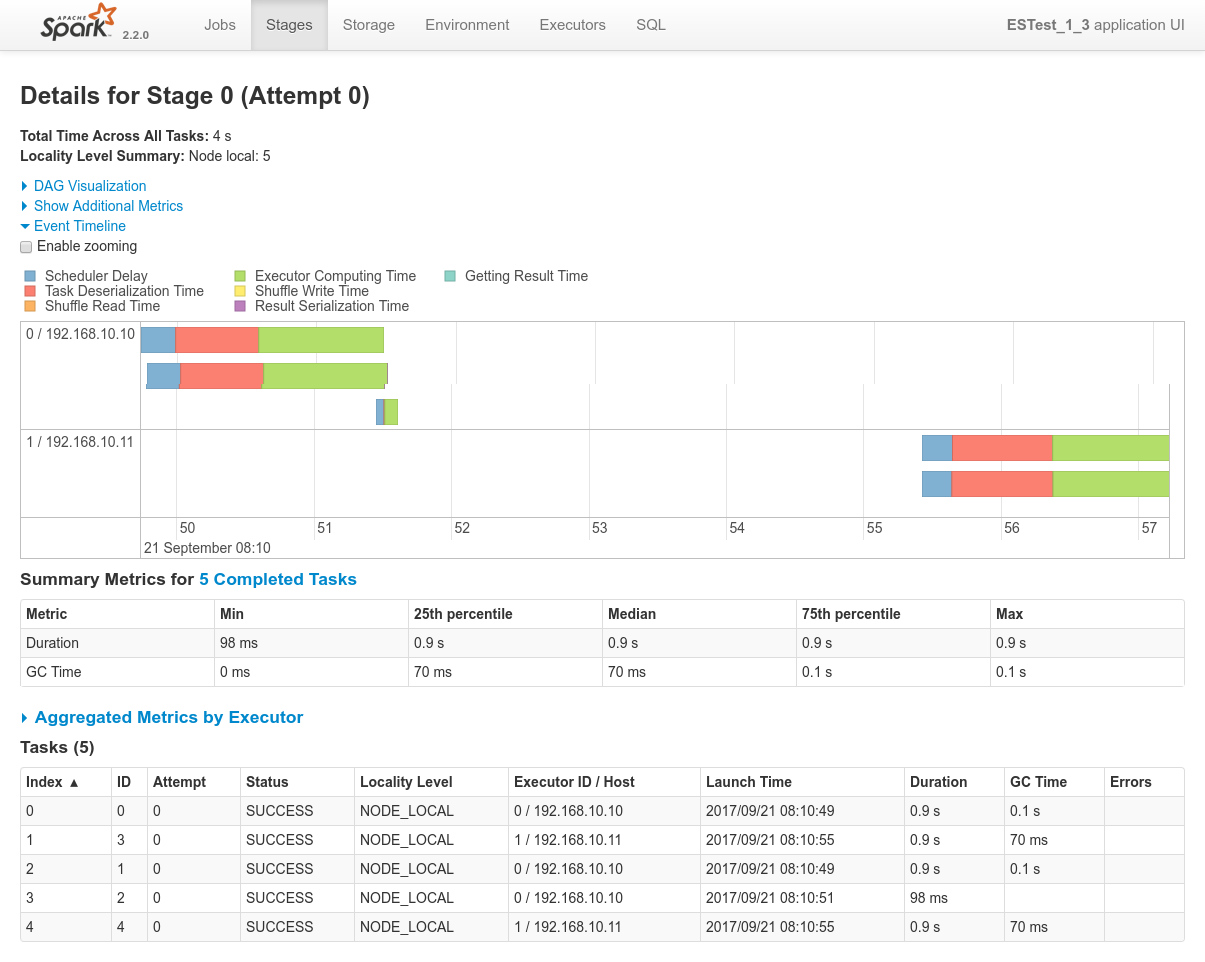
Conclusions
-
Spark can read data from ElasticSearch using the ES-Hadoop connector and the New DataFrame API (SQLSession) really out of the box.
The single configuration required here as well isformat("org.elasticsearch.spark.sql") on theSQLSessionAPI - Nothing specific to report regarding the other aspects: Mesos and Spark's dynamic allocation system distribute the workload as expected, still creates a dedicated Spark Executor for 2 nodes of the cluster which is sufficient (thx replicas), Spark respects data locality strictly, etc.
5.1.4 DataFrame API on Apache-logs dataset
Test details
- Test Script:
1_nominal_4_test_apache-logs_df.sh - Input Dataset: Apache Logs Dataset from https://download.elastic.co/demos/kibana/gettingstarted/logs.jsonl.gz
- Purpose: see how Spark's New (>= 2.0) DataFrame API can be used to fetch data from ElasticSearch from another dataset and how sharding in ES impacts executors layout on the cluster
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_1_4")
# es.read.field.exclude (default empty) :
# Fields/properties that are discarded when reading the documents
# from Elasticsearch
conf.set ("es.read.field.exclude", "relatedContent")
# es.read.field.as.array.include (default empty) :
# Fields/properties that should be considered as arrays/lists
conf.set ("es.read.field.as.array.include", "@tags,headings,links")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# Query configuration only (cannot pass any ES conf here :-( )
es_query_conf= {
"pushdown": True
}
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("apache-logs-*")
# I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count : THIS IS FUNNY :
# it relaunches the whole Distributed Data Frame Processing
print ("Fetched %s logs (re-computed)") % es_df.count()
# Print count
print ("Fetched %s logs (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 1_nominal_4_test_apache-logs_df.log
- Screenshots from the various admin console after the test execution:
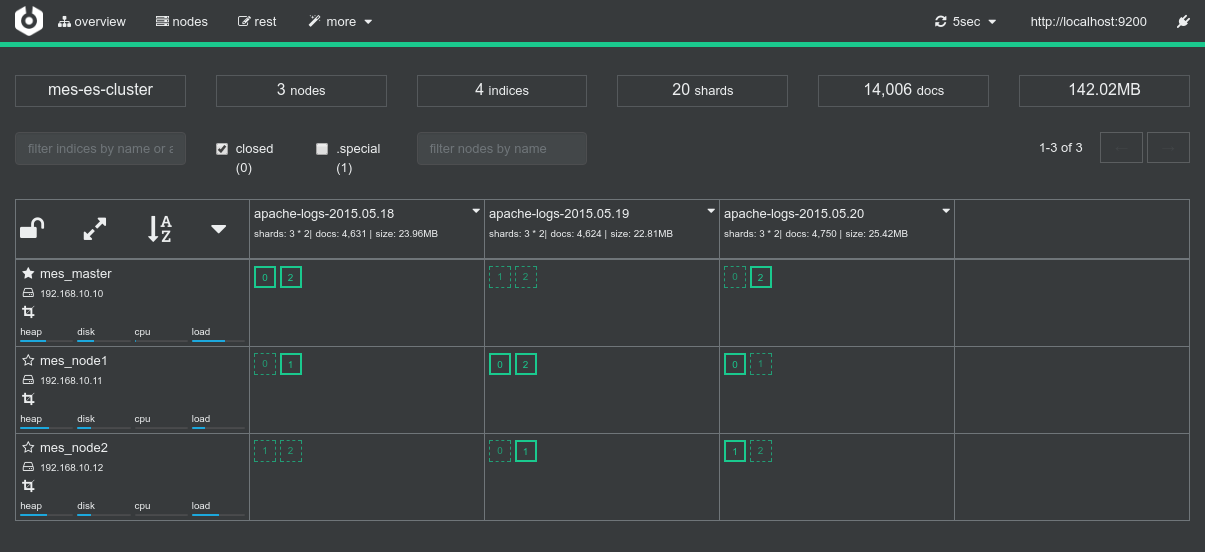
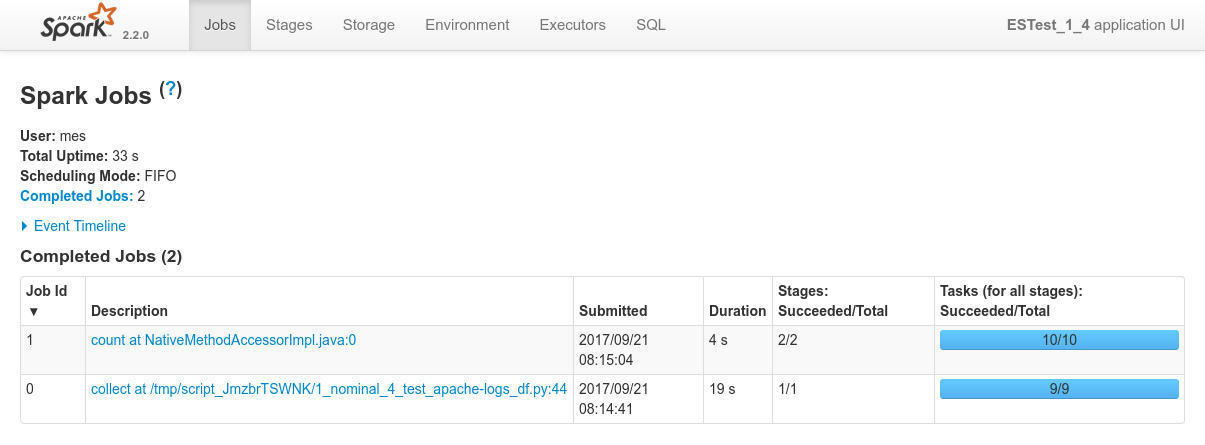
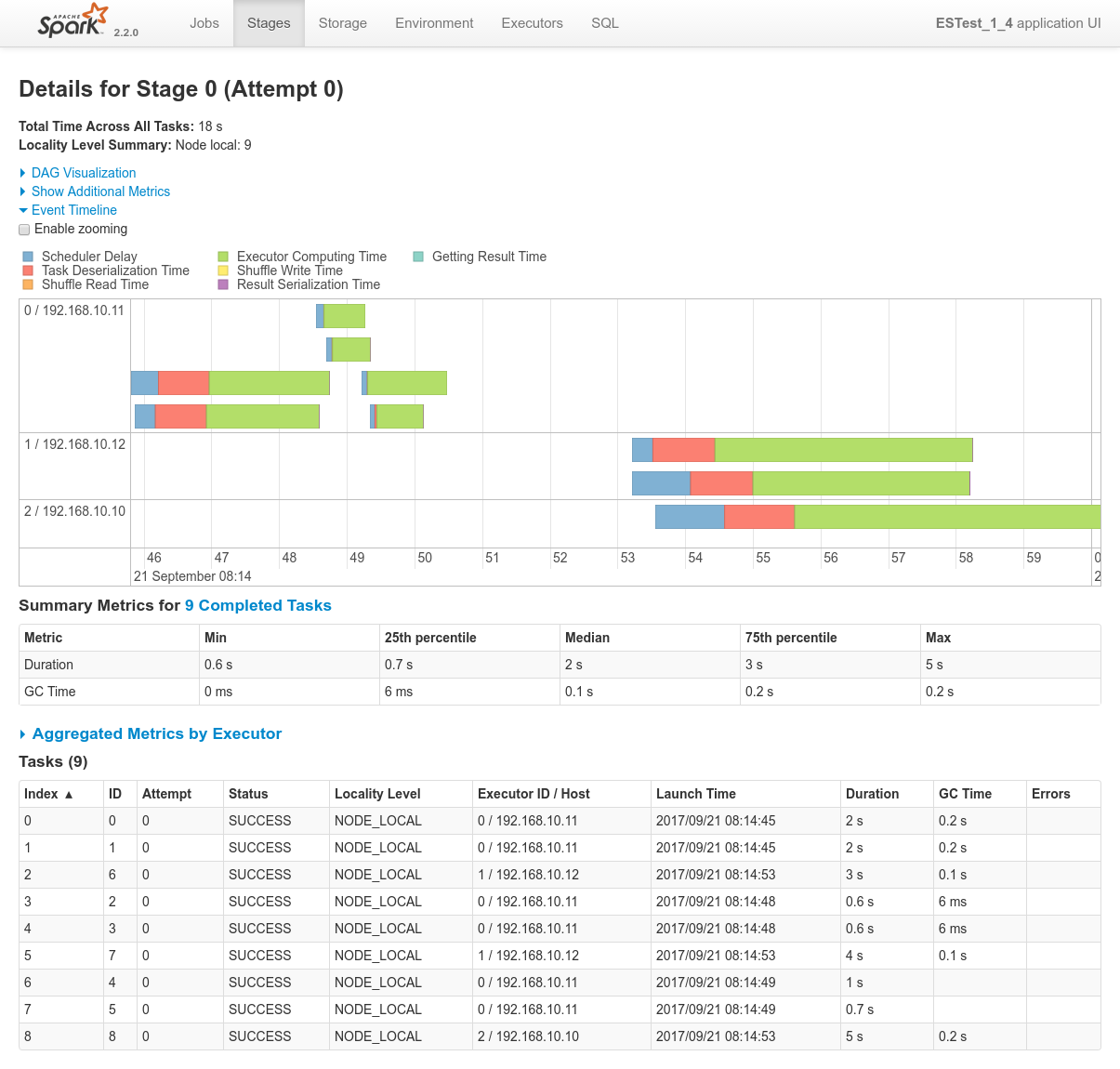
Conclusions
N.D (nothing to declare). Everything works as expected (see previous tests results from the 1 Nominal Tests family).
Interestingly here, the workload justifies the booking of the three nodes of te cluster, which is successfully achieved since the job runs alone on the cluster.
5.1.5 DataFrame API on Shakespeare dataset
Test details
- Test Script:
1_nominal_5_test_shakespeare.sh - Input Dataset: Shakespeare's Works Dataset from https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json
- Purpose: see how Spark's New (>= 2.0) DataFrame API can be used to fetch data from ElasticSearch from another dataset and how sharding in ES impacts executors layout on the cluster
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_1_5")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# Query configuration only (cannot pass any ES conf here :-( )
es_query_conf= {
"pushdown": True
}
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("shakespeare*")
# Collect result to the driver
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count : THIS IS FUNNY :
# it relaunches the whole Distributed Data Frame Processing
print ("Fetched %s logs (re-computed)") % es_df.count()
# Print count
print ("Fetched %s logs (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 1_nominal_5_test_shakespeare.log
- Screenshots from the various admin console after the test execution:
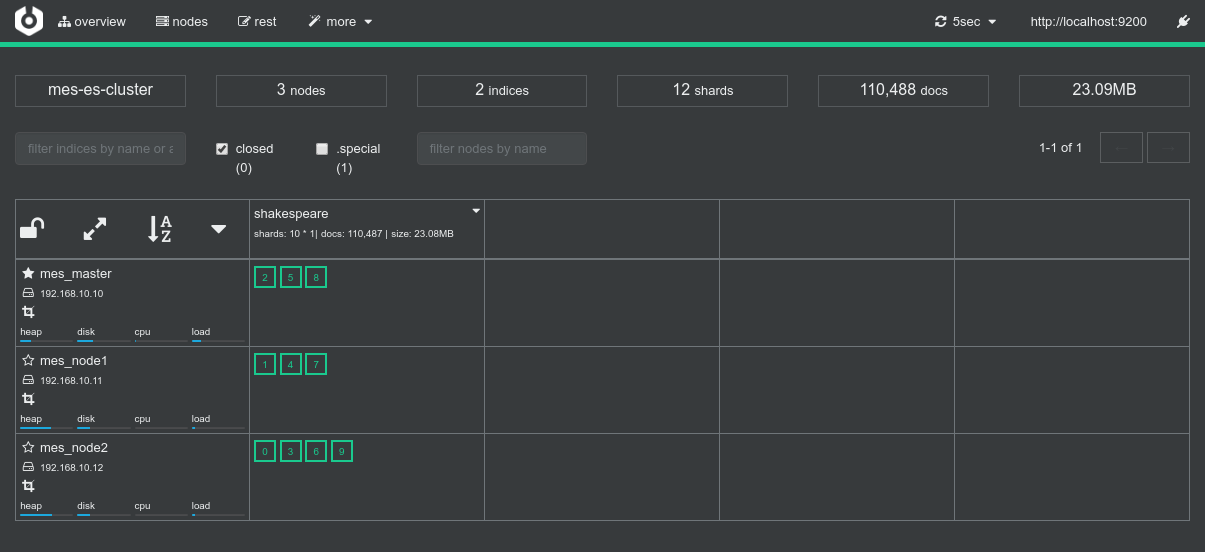
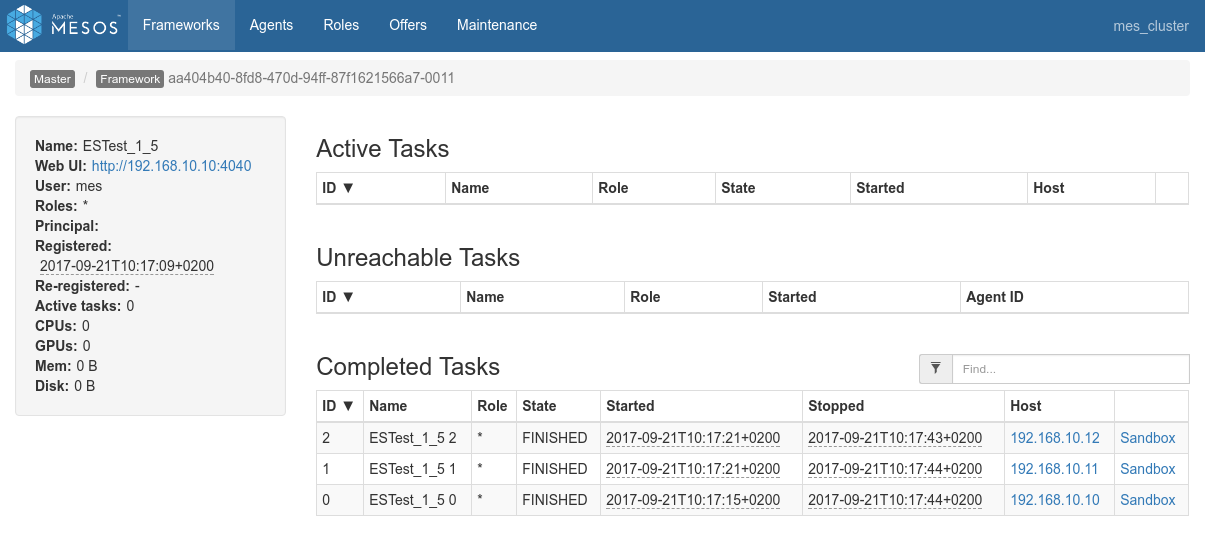
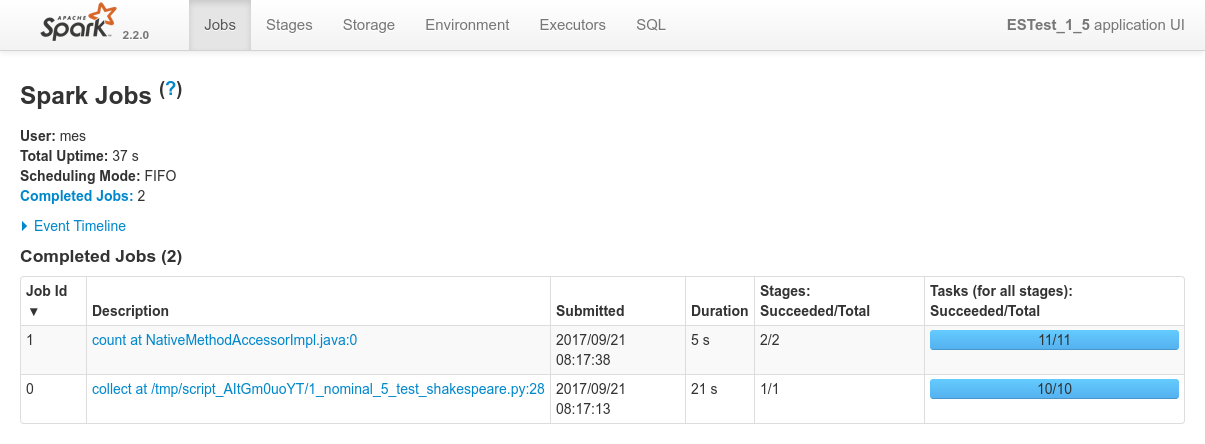
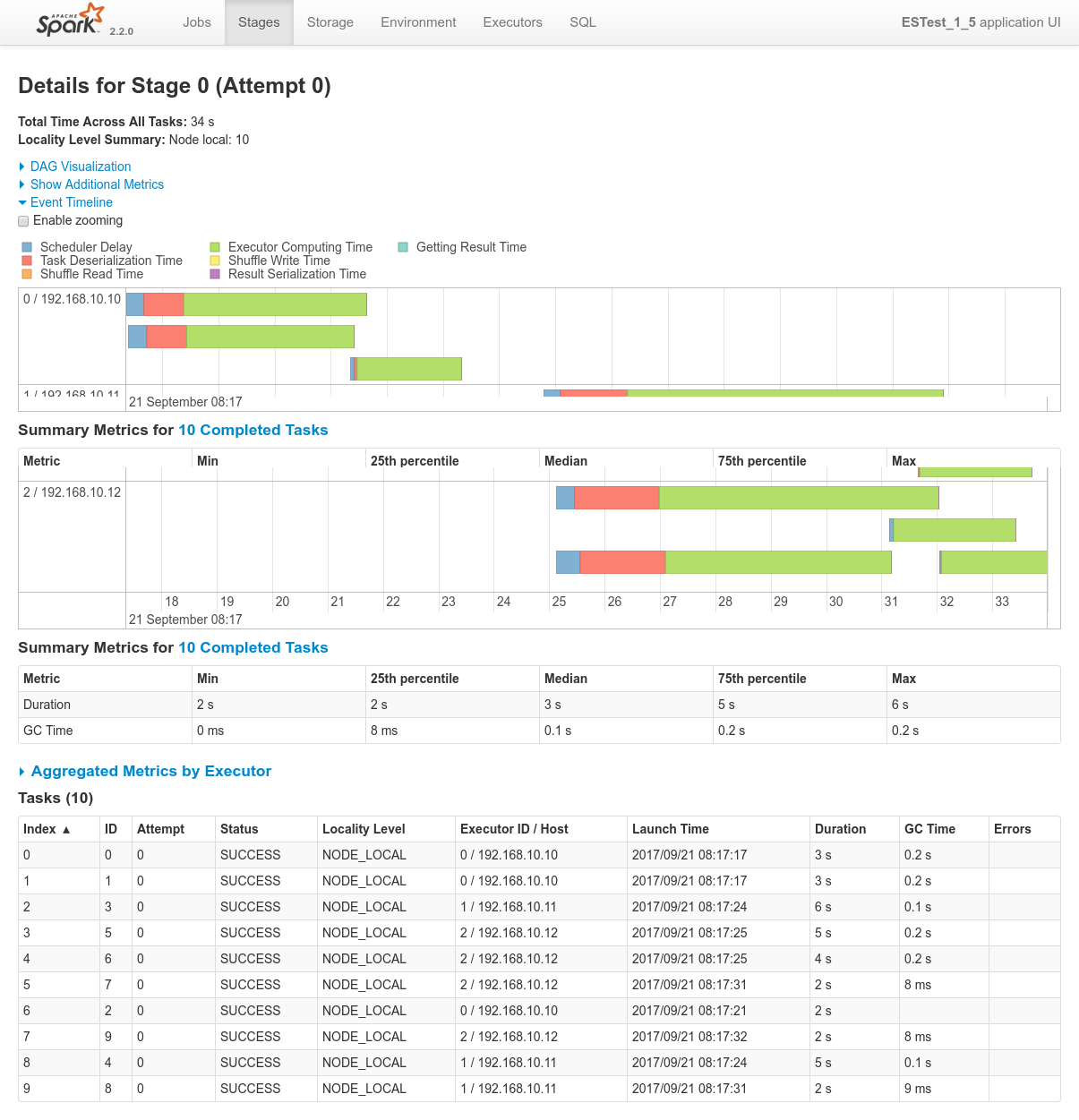
Conclusions
N.D (nothing to declare). Everything works as expected (see previous tests results from the 1 Nominal Tests family).
This time, however, due to the lack of replicas, the three nodes are actually required to satisfy data localiy optimization. The allocation of the 2 nodes to the job happens successfully again since the job runs alone.
5.2 Data-locality tests
Data-locality tests - assess how data-locality optimization between ES and Spark works and to what extent.
5.2.1 Bank dataset with 1 shard
Test details
- Test Script:
2_collocation_1_bank_one_shard.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: Assess how data-locality works when using a dataset with a single shard on a single node of the cluster, see what decisions will Mesos / Spark take from ES-Hadoop's requirements.
Expected Behaviour
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_2_1")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# (1)
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# (2) Print size of every partition on nodes
def f(iterable):
# need to convert iterable to list to have len()
print("Fetched % rows on node") % len(list(iterable))
es_df.foreachPartition(f)
# (3) I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 2_collocation_1_bank_one_shard.log
- Screenshots from the various admin console after the test execution:
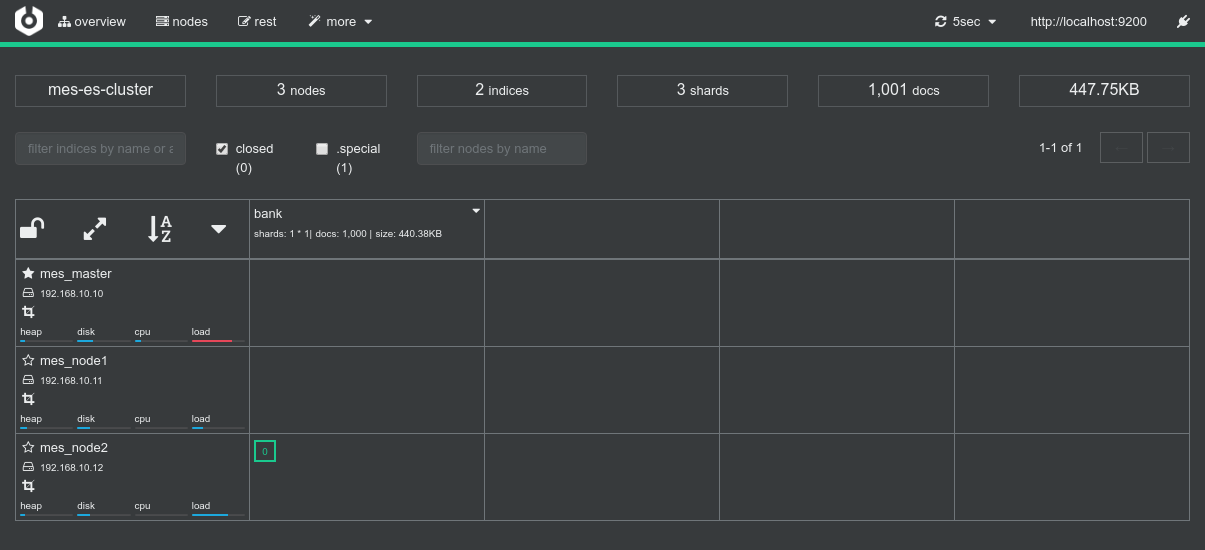
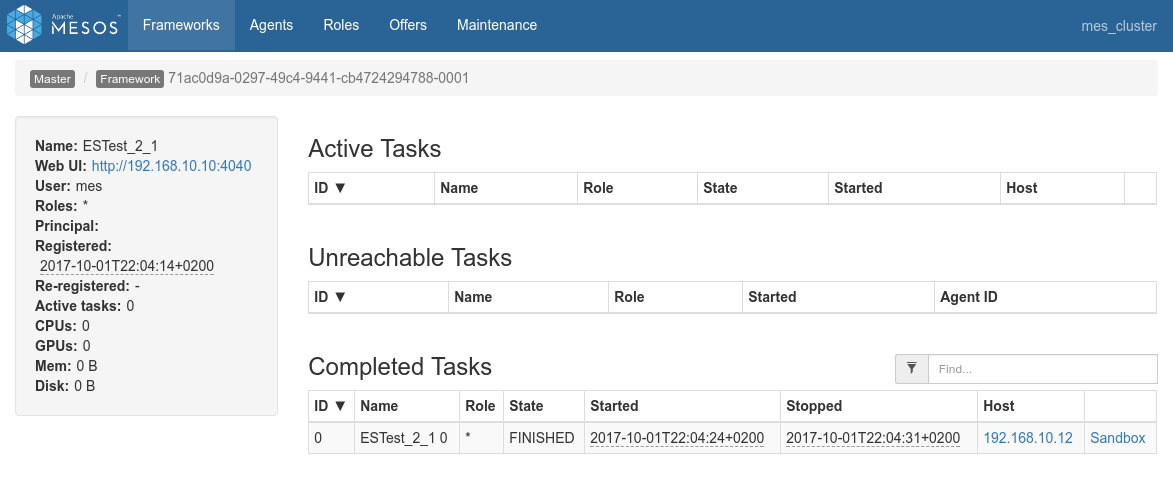
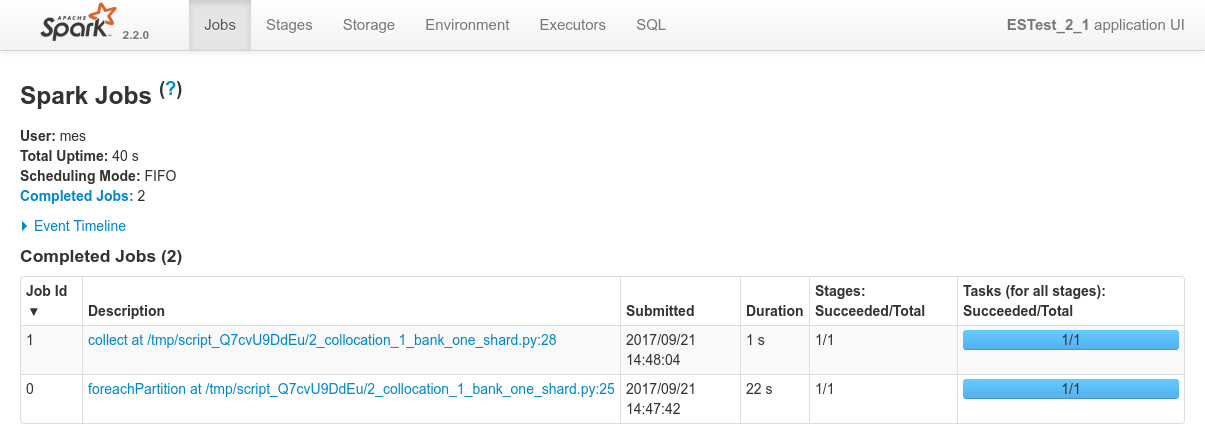
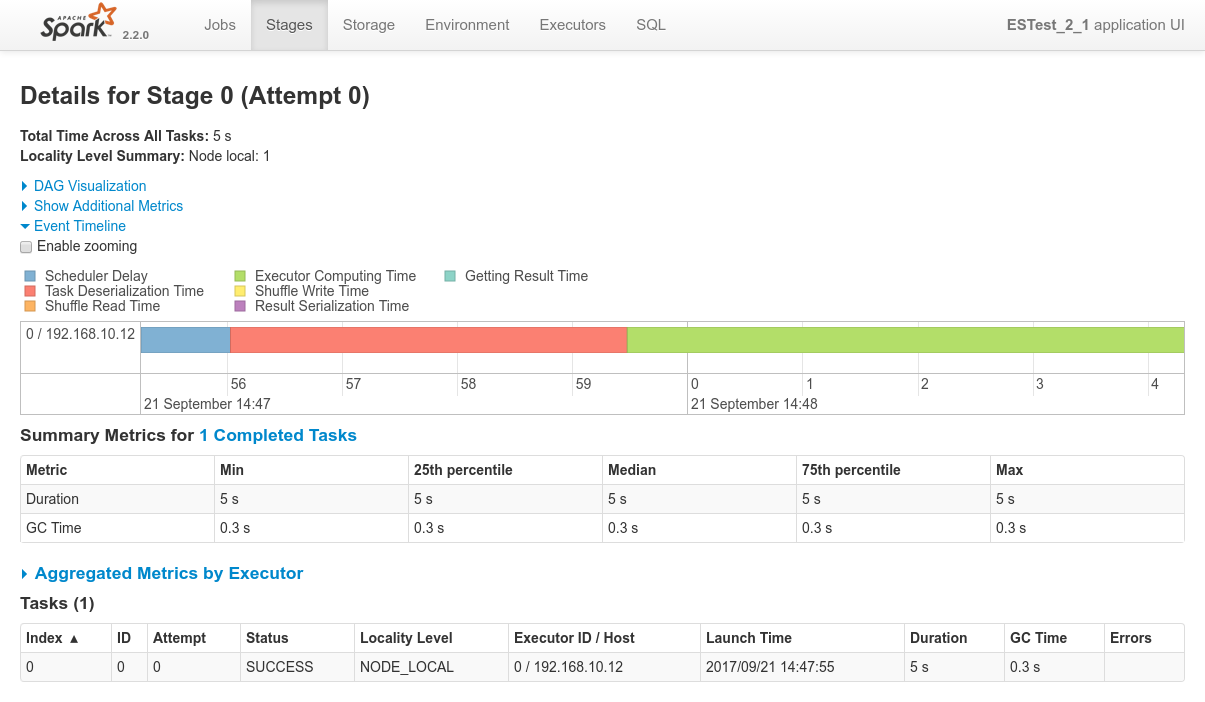
Conclusions
- In terms of workload distribution, this is where Dynamic Allocation is really cool. Since the single shard is on a single node, the Spark Dynamic Allocation System, with the help of Mesos, takes care of booking that single node as well for the Spark processing job
-
As a sidenote, using static allocation here, mesos Spark would have booked the whole cluster for the job, which would have been far from optimal in terms of workload distribution. Since the cluster is fully available, Mesos would have booked it all for the Job to come. But eventually 2 of the 3 spark executors won't be used at all.
That wouldn't have been a big deal since this test is running alone. But if some more jobs are added to the cluster and requests an executor, they will have to wait for that first job to be finished before they can share the cluster among them. - Data-locality works as expected. The single shard is located on
192.168.10.12and both the driver logs and the Spark Console for Job 0 / Stage 0 confirms that the co-located Spark executor has been the only one processing the data.
5.2.2 Bank dataset with 2 shards
Test details
- Test Script:
2_collocation_2_bank_two_shards.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: Assess how data-locality optimization works when using a dataset with a two shards on two nodes of the cluster, see what decisions will Mesos / Spark take from ES-Hadoop's requirements.
Expected Behaviour
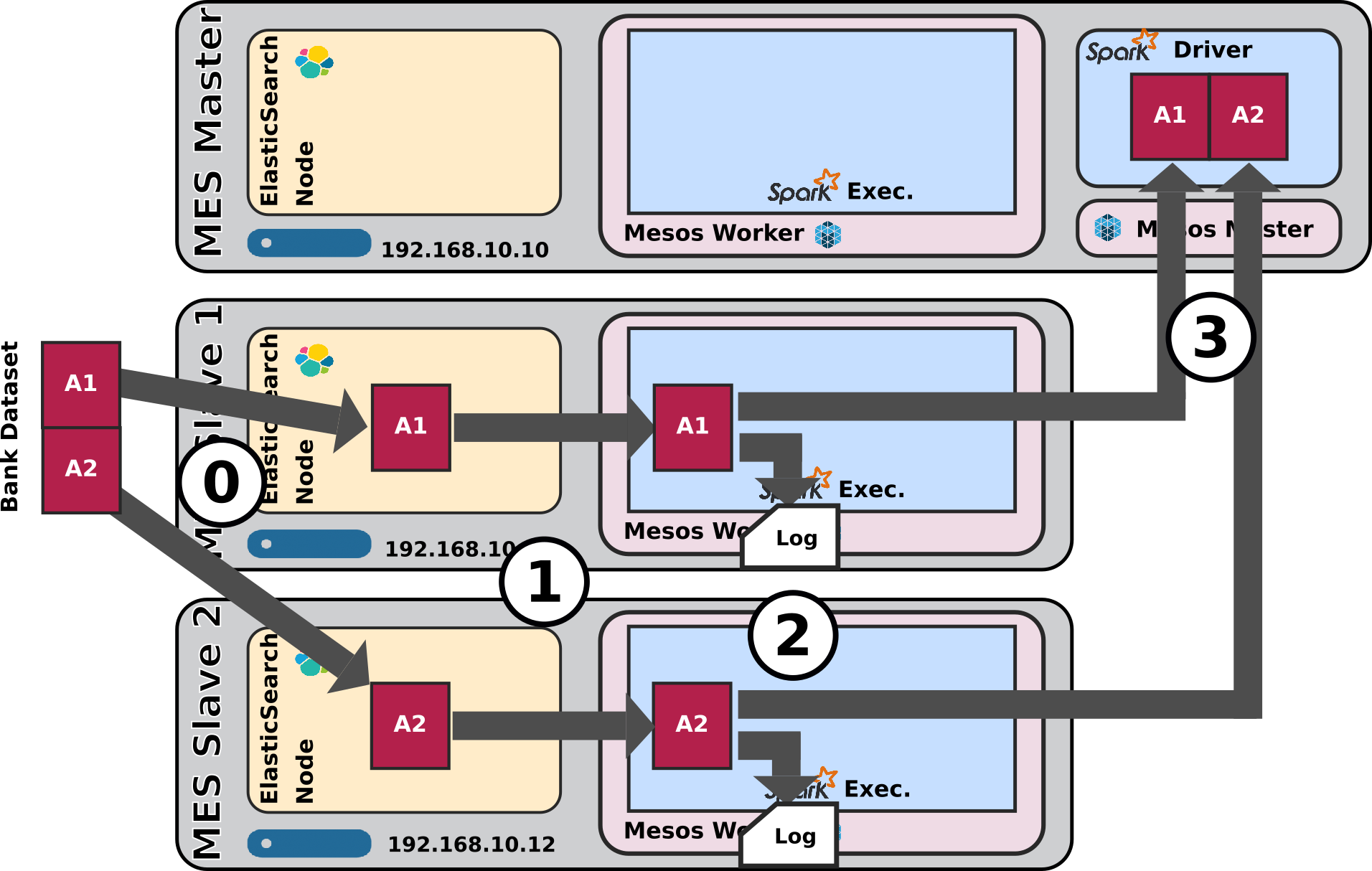
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_2_2")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# (1)
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# (2) Print size of every partition on nodes
def f(iterable):
# need to convert iterable to list to have len()
print("Fetched % rows on node") % len(list(iterable))
es_df.foreachPartition(f)
# (3) I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 2_collocation_2_bank_two_shards.log
- Screenshots from the various admin console after the test execution:
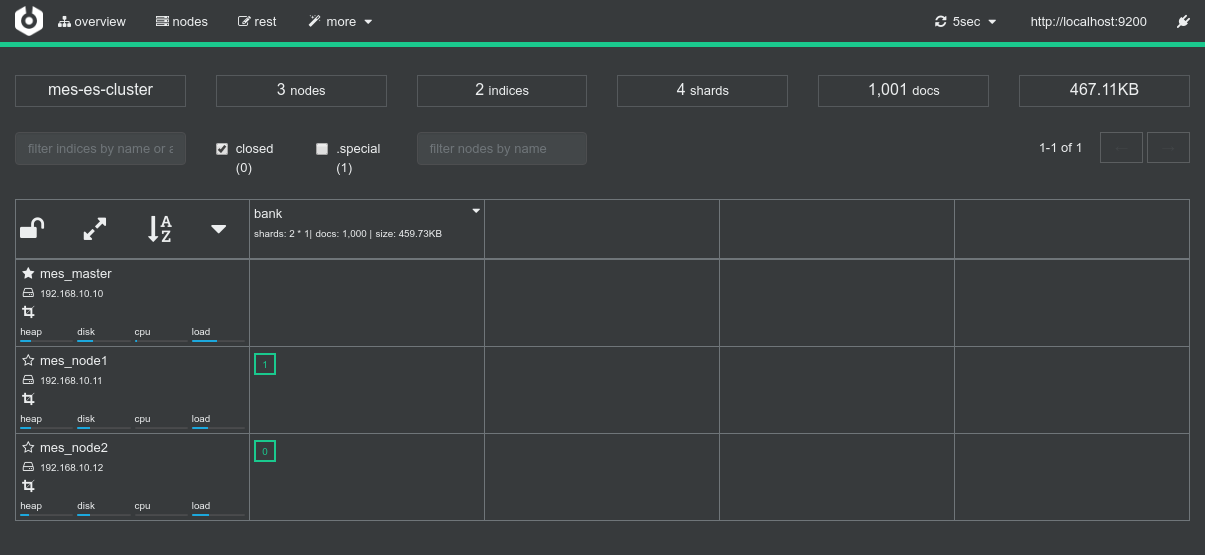
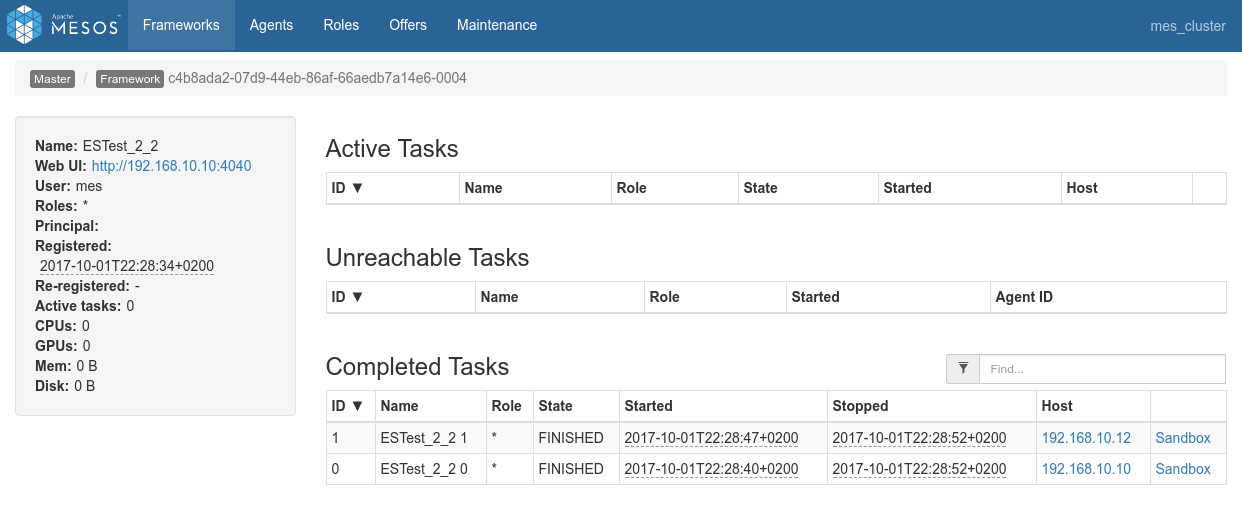
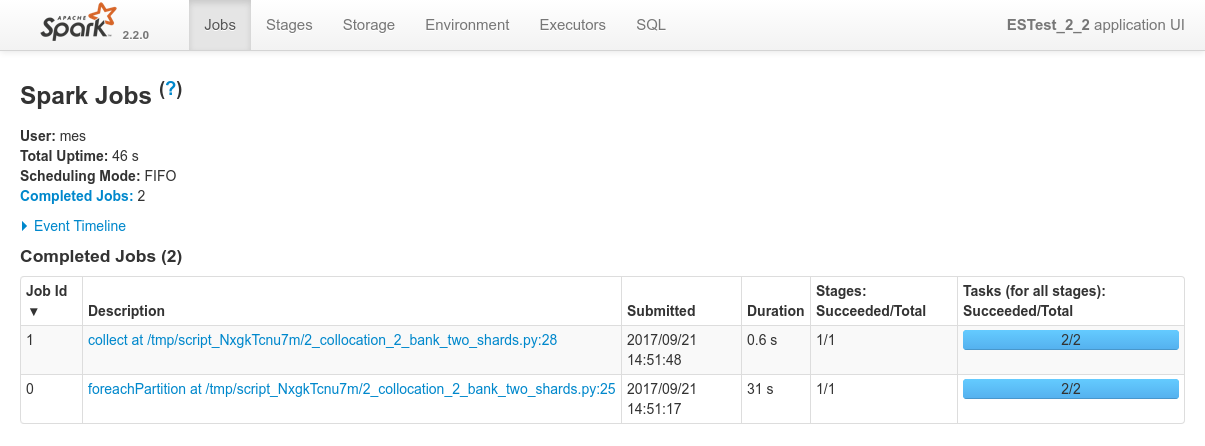
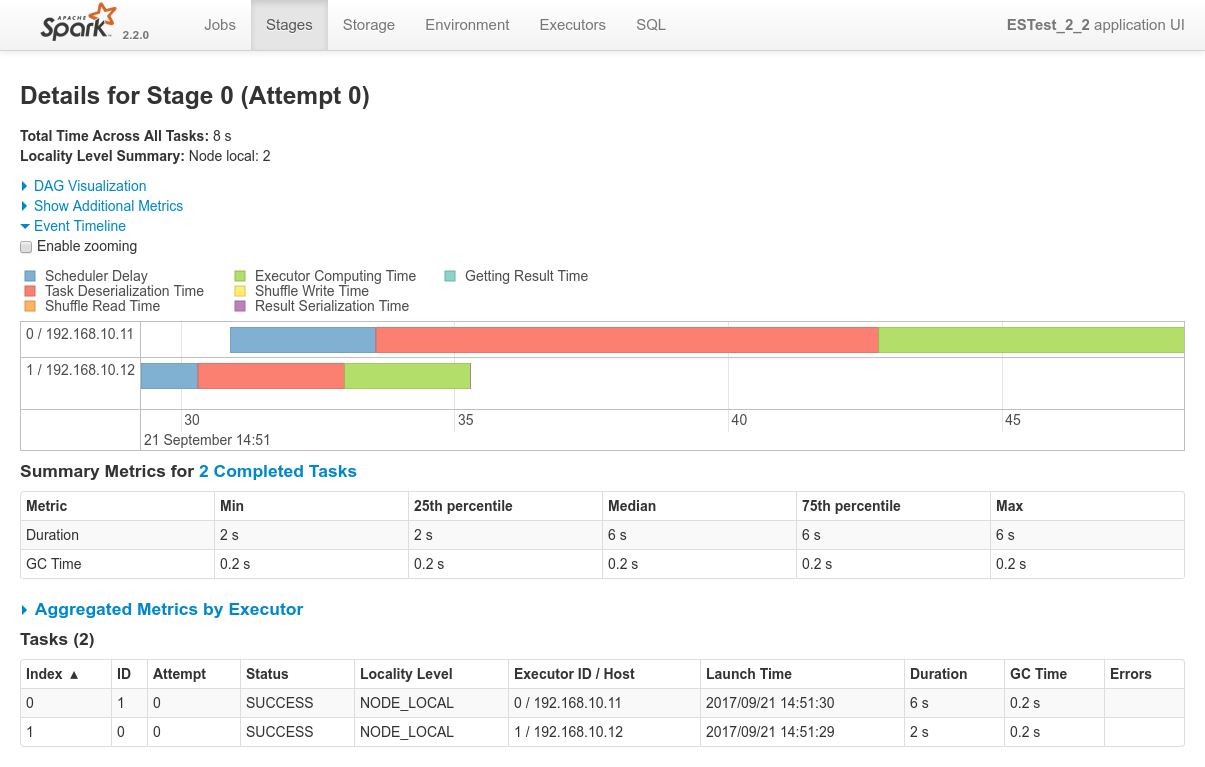
Conclusions
-
Same remark as above regarding workload distribution.
Dynamic Allocation is really cool. Since the two shards are on two nodes, the Spark Dynamic Allocation System, with the help of Mesos, takes care of booking the two corresponding nodes as well for the Spark processing job. - Data locality works as expected. The two shards are on
192.168.10.10and192.168.10.12and both the driver logs and the Spark Console for Job 0 / Stage 0 confirms that both co-located Spark executor have been used to process the 2 shards.
The tasks have been executed withNODE_LOCALlocality level.
5.2.3 Bank dataset with 3 shards
Test details
- Test Script:
2_collocation_3_bank_three_shards.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: Assess how data-locality optimization works when using a dataset with a three shards on three nodes of the cluster, see what decisions will Mesos / Spark take from ES-Hadoop's requirements.
Expected Behaviour
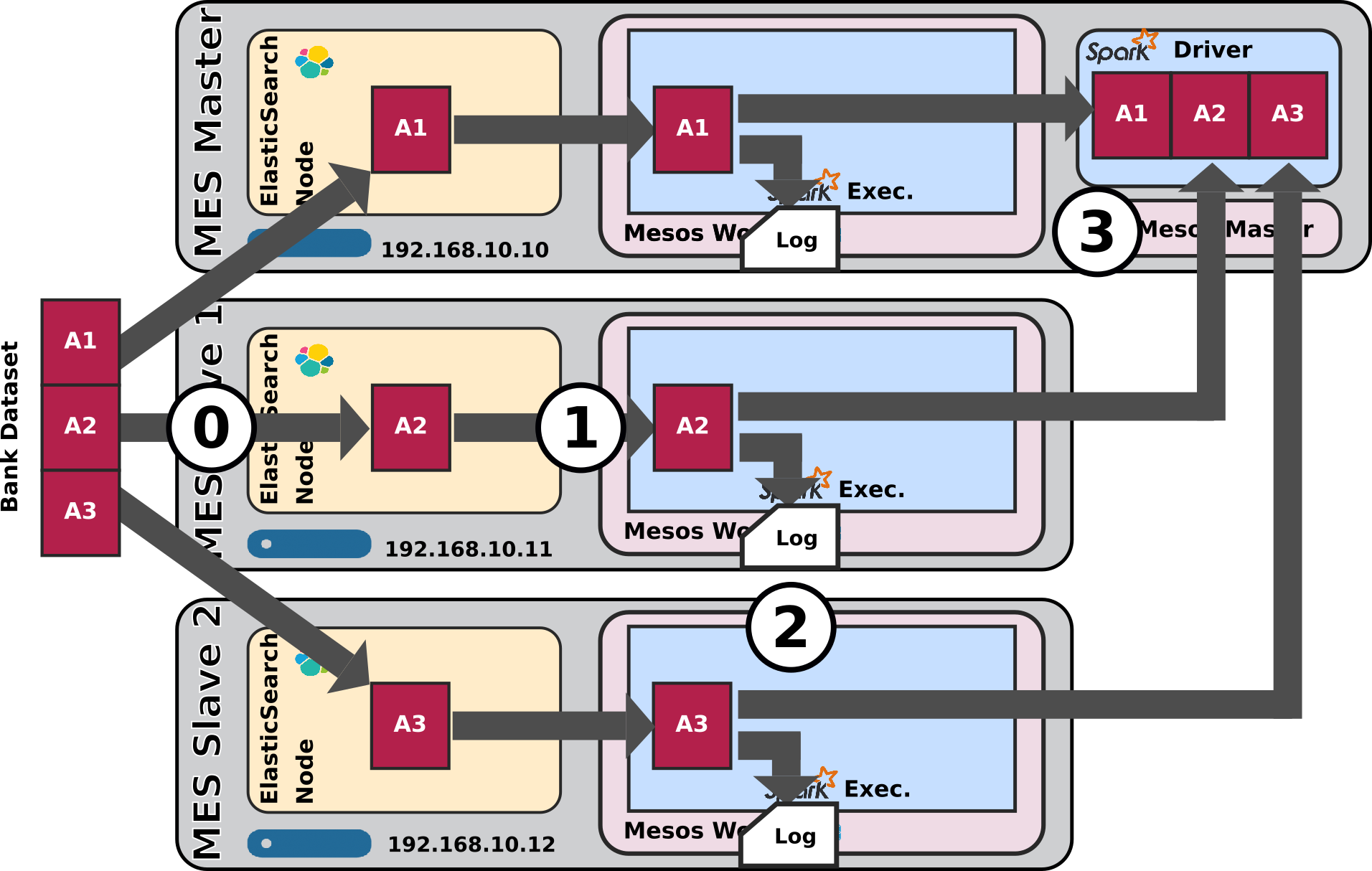
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_2_3")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# (1)
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# (2) Print size of every partition on nodes
def f(iterable):
# need to convert iterable to list to have len()
print("Fetched % rows on node") % len(list(iterable))
es_df.foreachPartition(f)
# (3) I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 2_collocation_3_bank_three_shards.log
- Screenshots from the various admin console after the test execution:
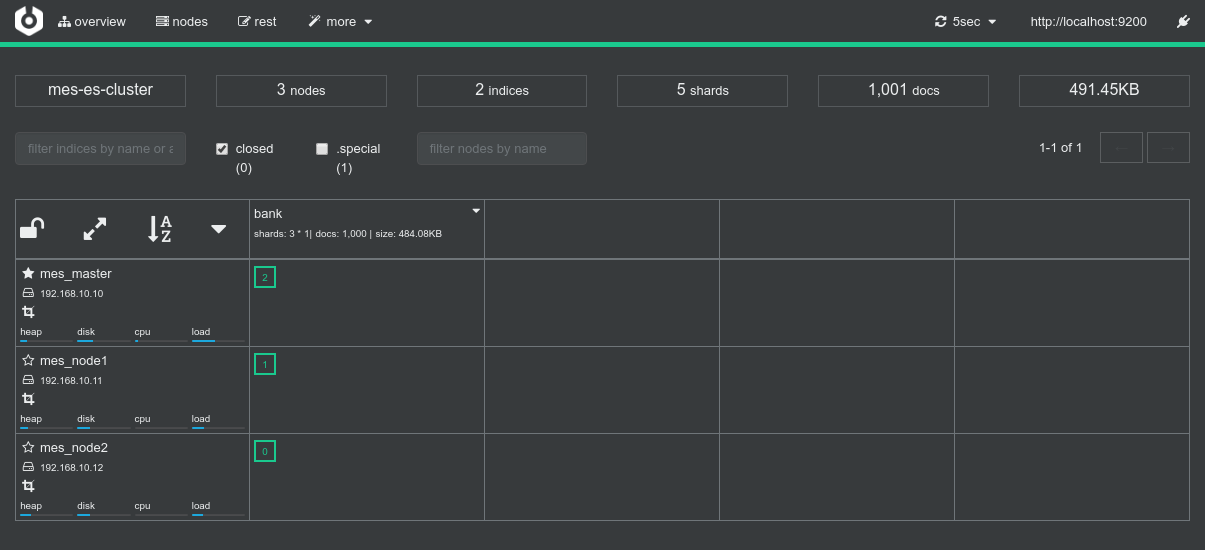
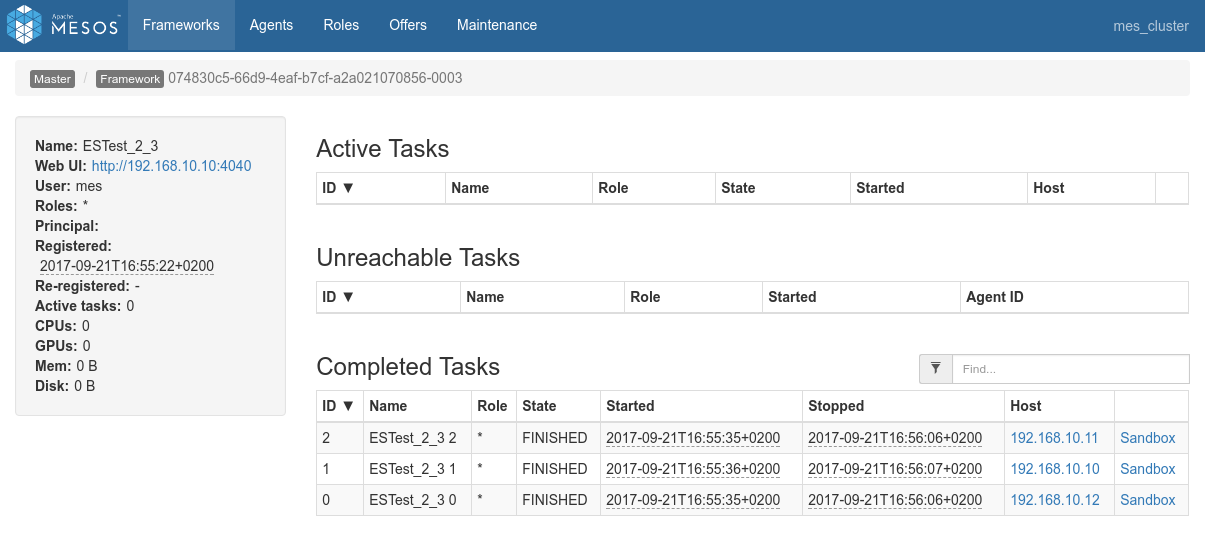
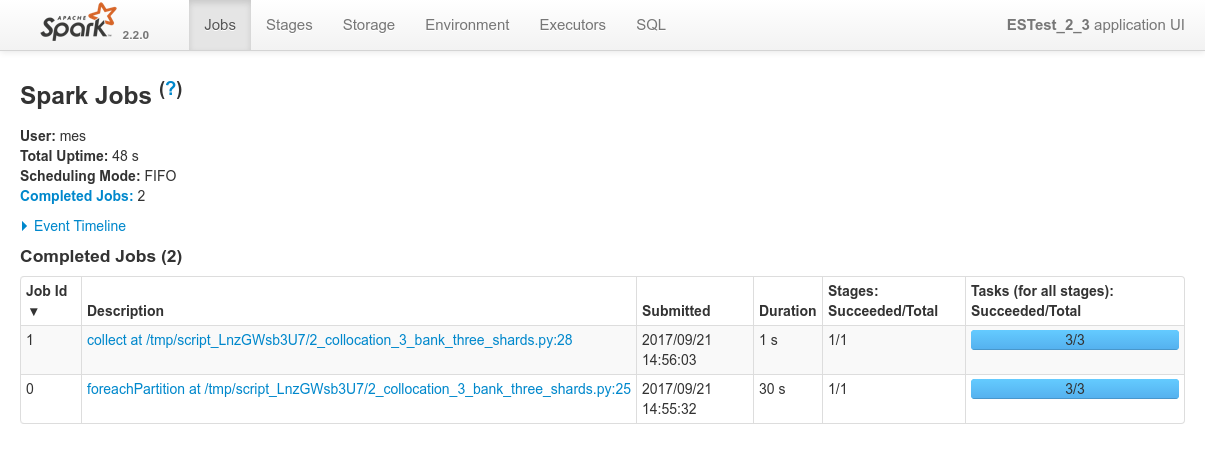
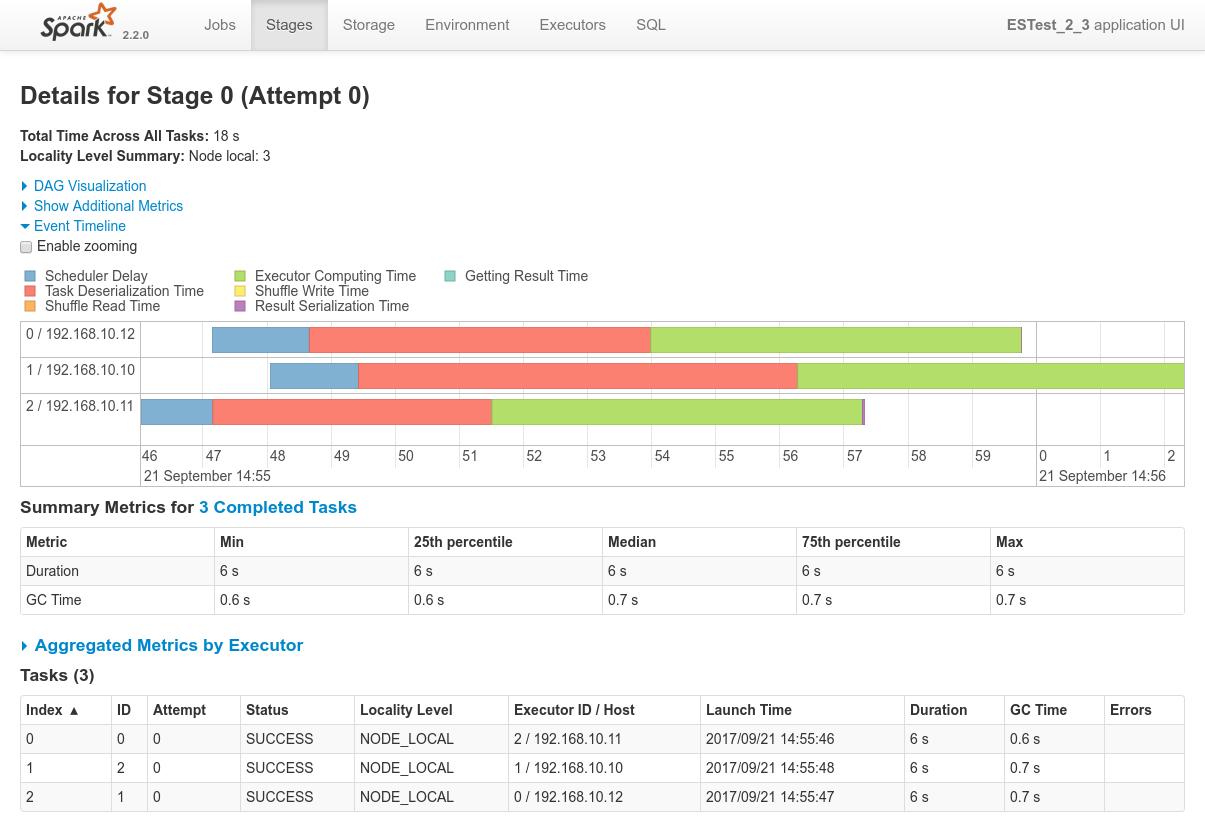
Conclusions
- Three shards on three nodes so three nodes booked for processing, everything works as expected.
- Data locality works as expected. The 3 spark executors consumes data from their co-located shards. This is confirmed by everything behaving as expected as can be seen in the driver logs or in the Spark Application UI.
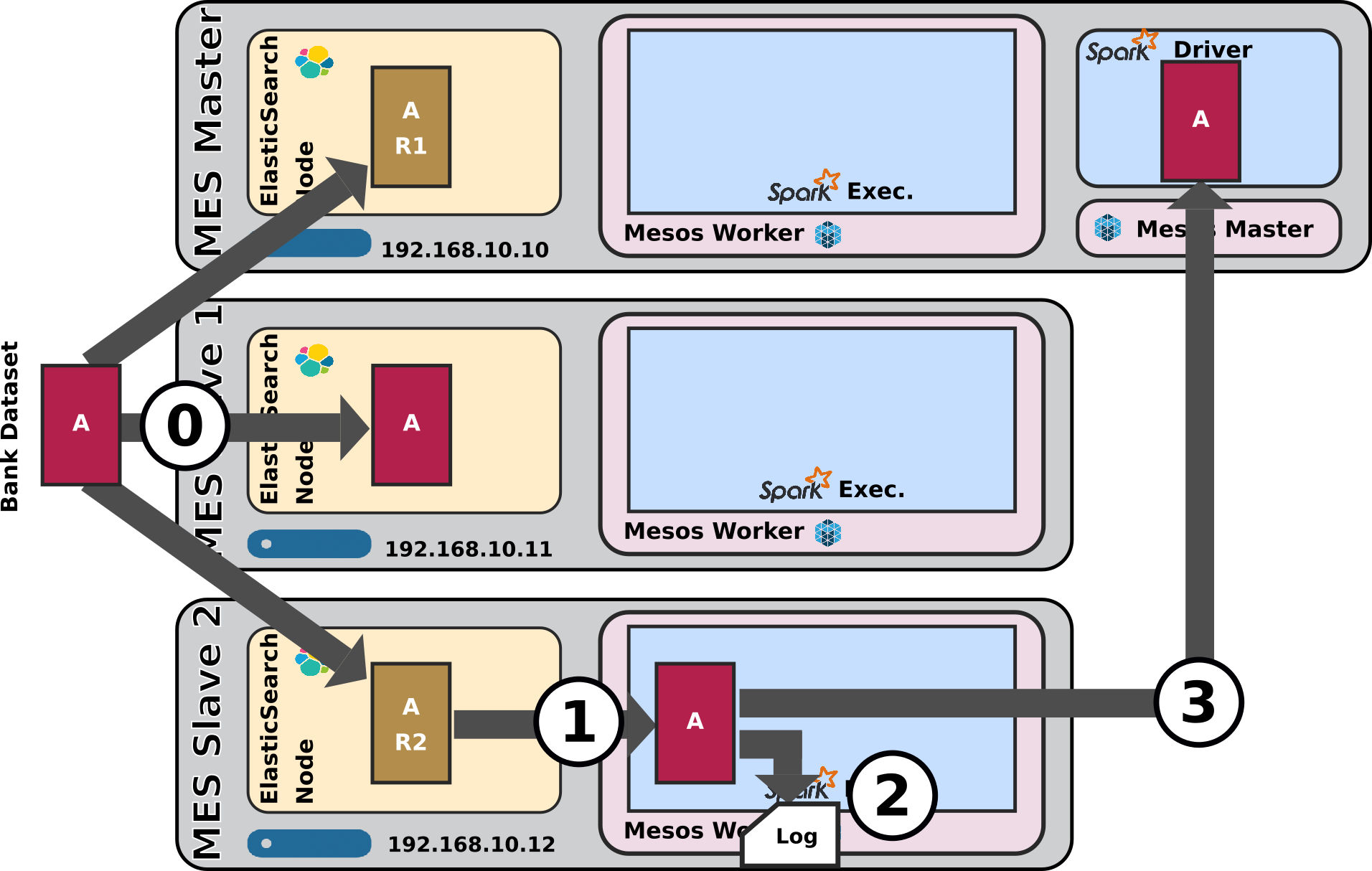
5.2.4 Bank dataset with 1 shard and replicas
Test details
- Test Script:
2_collocation_4_bank_one_shard_with_replicas.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: Assess how data-locality works when using a dataset with one shard and two replicas on three nodes of the cluster, see what decisions will Mesos / Spark take from ES-Hadoop's requirements.
Expected Behaviour
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_2_4")
# FIXME GET RID OF THESE TESTS
# Trying some ES settings
# conf.set ("spark.es.input.max.docs.per.partition", 100)
# That doesn't really help => it split the dataframe on several nodes indeed
# but it doesn't impact the fetching
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# (1)
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# (2) Print size of every partition on nodes
def f(iterable):
# need to convert iterable to list to have len()
print("Fetched % rows on node") % len(list(iterable))
es_df.foreachPartition(f)
# (3) I need to collect the result to show them on the console
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 2_collocation_4_bank_one_shard_with_replicas.log
- Screenshots from the various admin console after the test execution:
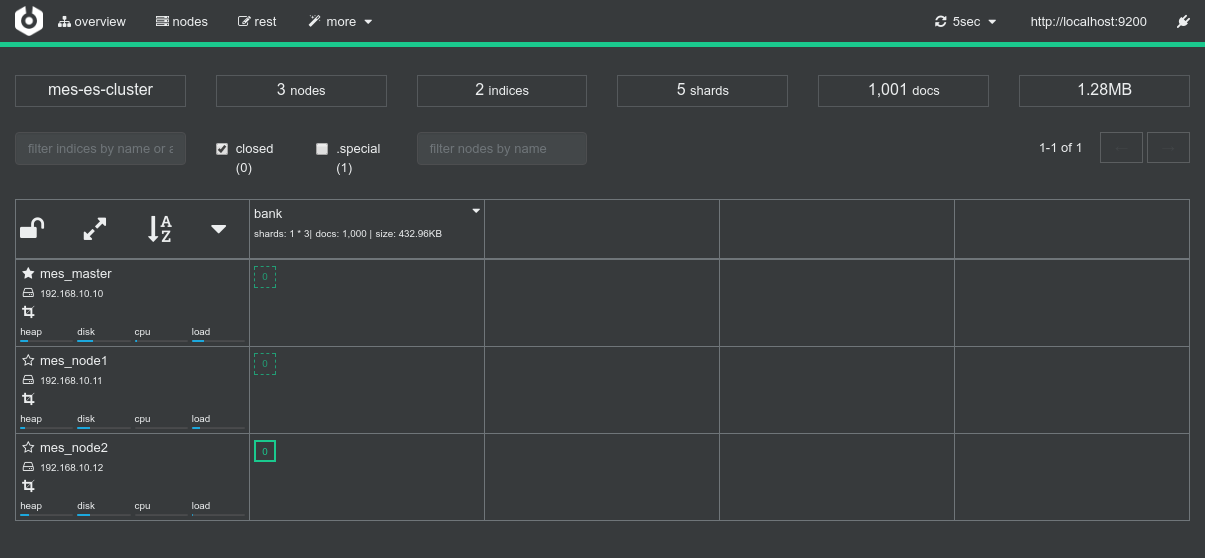
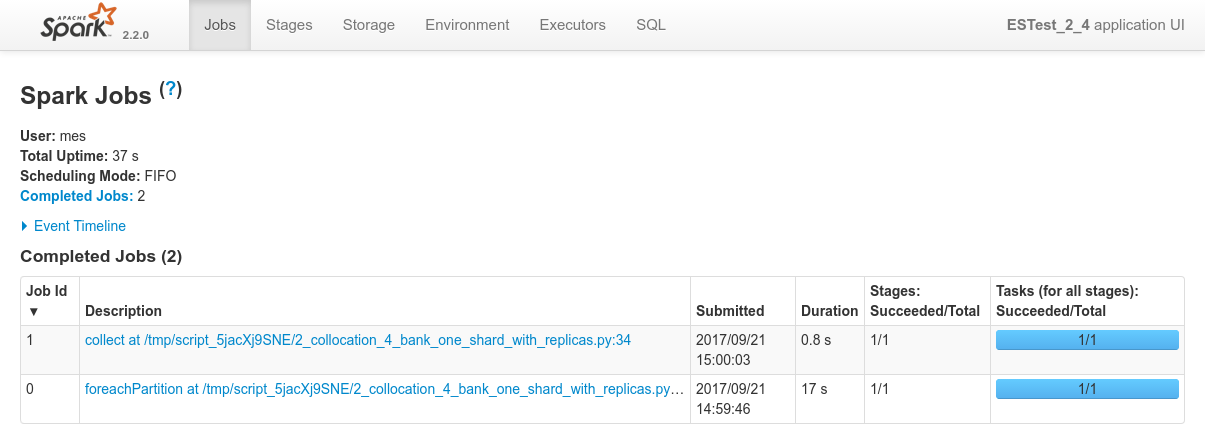
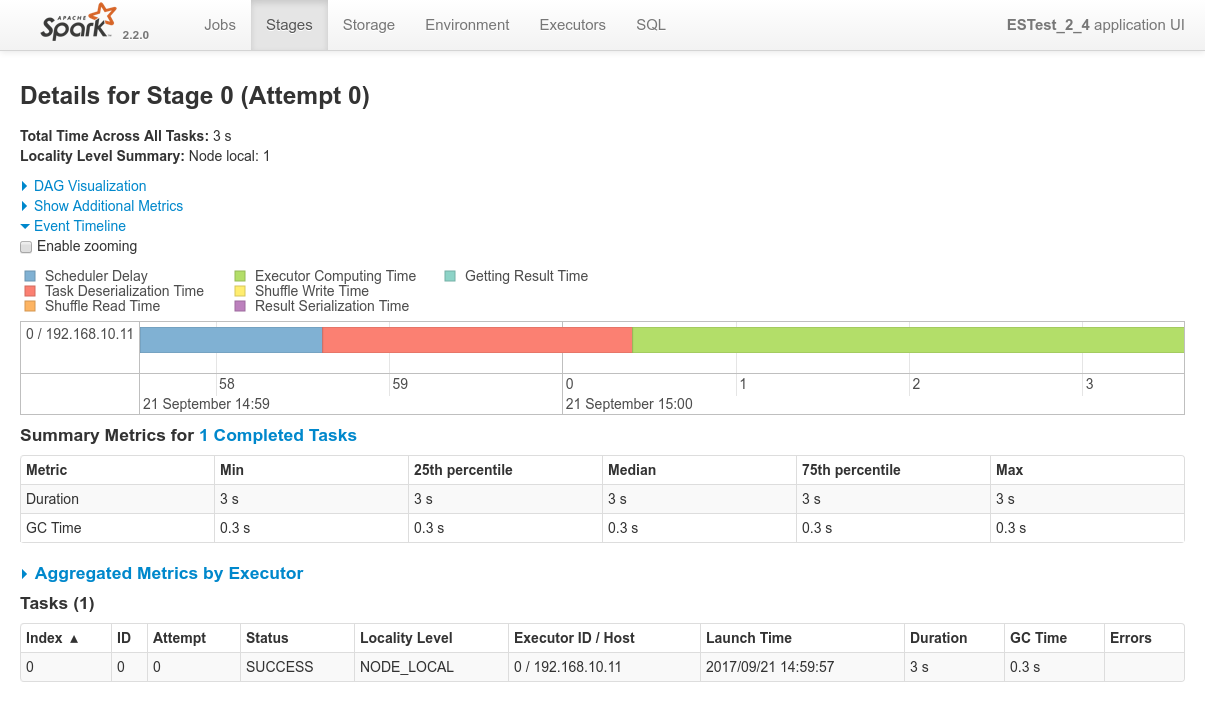
Conclusions
- In this case, it's really as if each and every ES node of the cluster has a copy of the data. ElasticSearch makes no distinction when it comes to serve requests between primary shards and secondary shards (replicas).
- Which node will finally execute the processing is really random. Out of several executions I always ended up having a different Spark node executing the whole processing. Data co-locality still kicks in and one single node still does the whole processing every time
-
Important note: All of the above works under normal behaviour. Under a heavily loaded cluster, the results can be significantly different.
By running different scenarii under different conditions, I have been able to determine 2 different situations in addition to the nominal one (the one on a free cluster):-
First, It can happen that Mesos tries to distribute a specific spark processing part to the Spark executor co-located to the ES shard.
But then, when the Spark processing finally queries that local node to get the shard, it can well happen that this ES node is busy answering a different request from a different client application.
In this case, that local ES node will report itself as busy and will ask another node from the ES cluster to server the request.
So even though initially Mesos / Spark distributed the workload to the local node to the shard in ES, eventually the request will be served by another distant node from te cluster. -
Second, it can also happen that all nodes co-located to the ES node owning all shards (primary and replicas) are busy.
In this case, Mesos / Spark will only wait a few seconds expecting of this node to become free, and if that fails to happen, eventually a different Mesos node will run the processing, indifferently for data locality.
-
First, It can happen that Mesos tries to distribute a specific spark processing part to the Spark executor co-located to the ES shard.
-
The difference here is that the existence of replicas suddenly gives ElasticSearch the choice
ElasticSearch has the choice to answer and serve the data from another node than the local node if suddenly the local node is busy! -
In addition, Mesos / Spark will only wait
spark.locality.wait=10sto try to make the specific processing part local to the ES node owning a shard (or a replica BTW). If none of these nodes (owning one of the primary shard or replicas) becomes free and available for that amount of time, then Mesos will distribute the workload to another available node from the Mesos cluster.
5.2.5 Testing repartitioning
Test details
- Test Script:
2_collocation_5_bank_one_shard_repartition_NOT_WORKING.sh - Input Dataset: Bank Dataset from https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
- Purpose: Assess how one can redistribute the data on the cluster after loading data from a sub-set of the cluster nodes such as, for instance, only one node, see how Spark can redistribute the data evenly on the cluster after having loaded an unbalanced data.
Expected Behaviour
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_2_5")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# (1)
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(pushdown=True) \
.load("bank") \
.where("gender='F'")
# Print size of every partition on nodes
def f(iterable):
# need to convert iterable to list to have len()
print("A - % rows stored on node") % len(list(iterable))
es_df.foreachPartition(f)
# Doesn't help
#es_df2 = es_df.coalesce(1)
## Print size of every partition on nodes
#es_df2.foreachPartition(f)
# (2)
es_df3 = es_df.repartition(4 * 3)
# Print size of every partition on nodes
es_df3.foreachPartition(f)
# (3) I need to collect the result to show them on the console
data_list = es_df3.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s women accounts (from collected list)") % len (data_list)
# Print
print (ss._jsc.sc().getExecutorMemoryStatus().size())
Results
- Logs of the Spark Driver: 2_collocation_5_bank_one_shard_repartition.log
- Screenshots from the various admin console after the test execution:
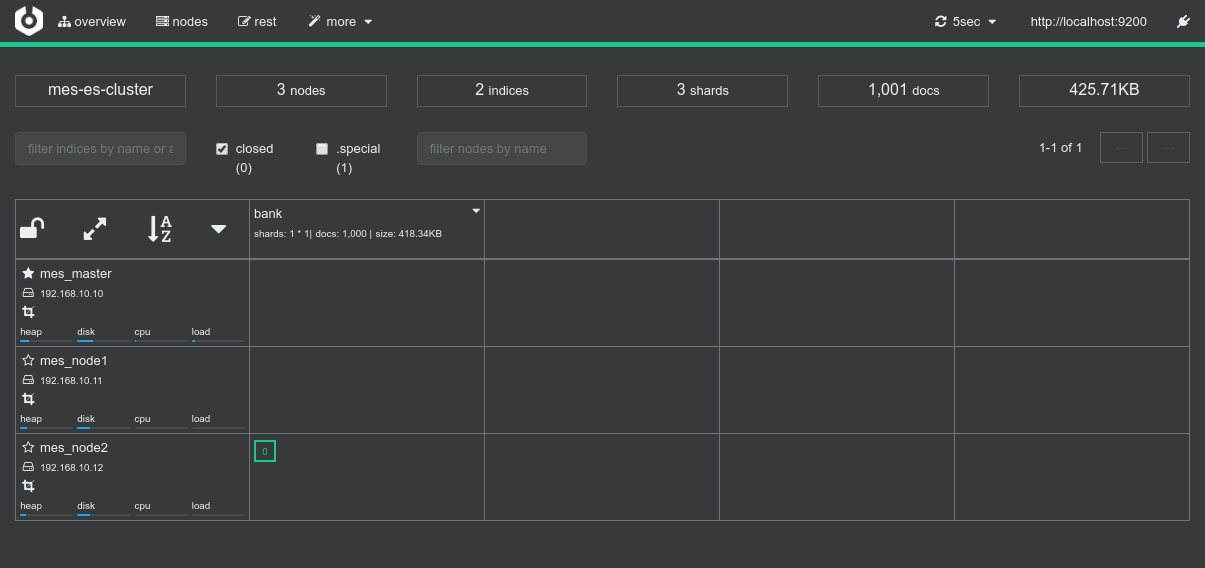
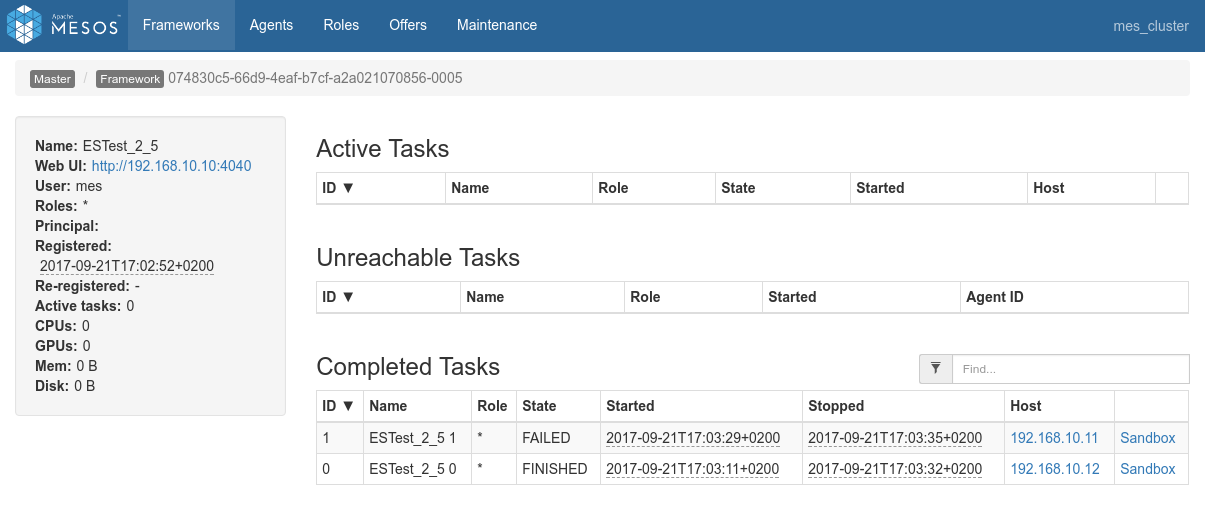
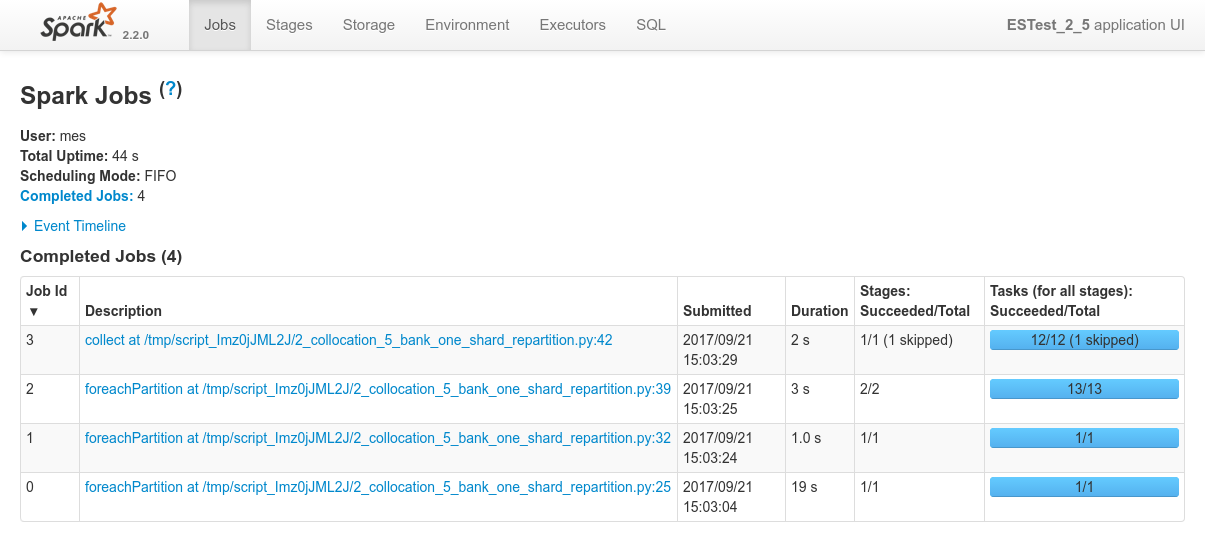
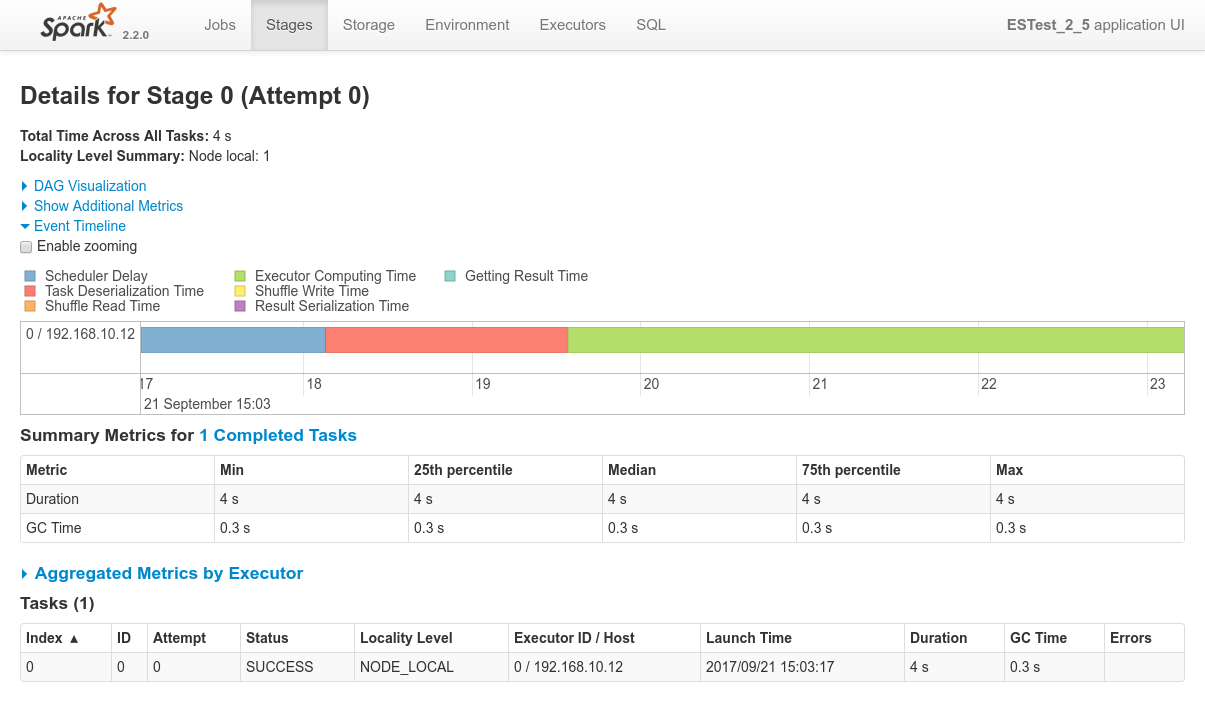
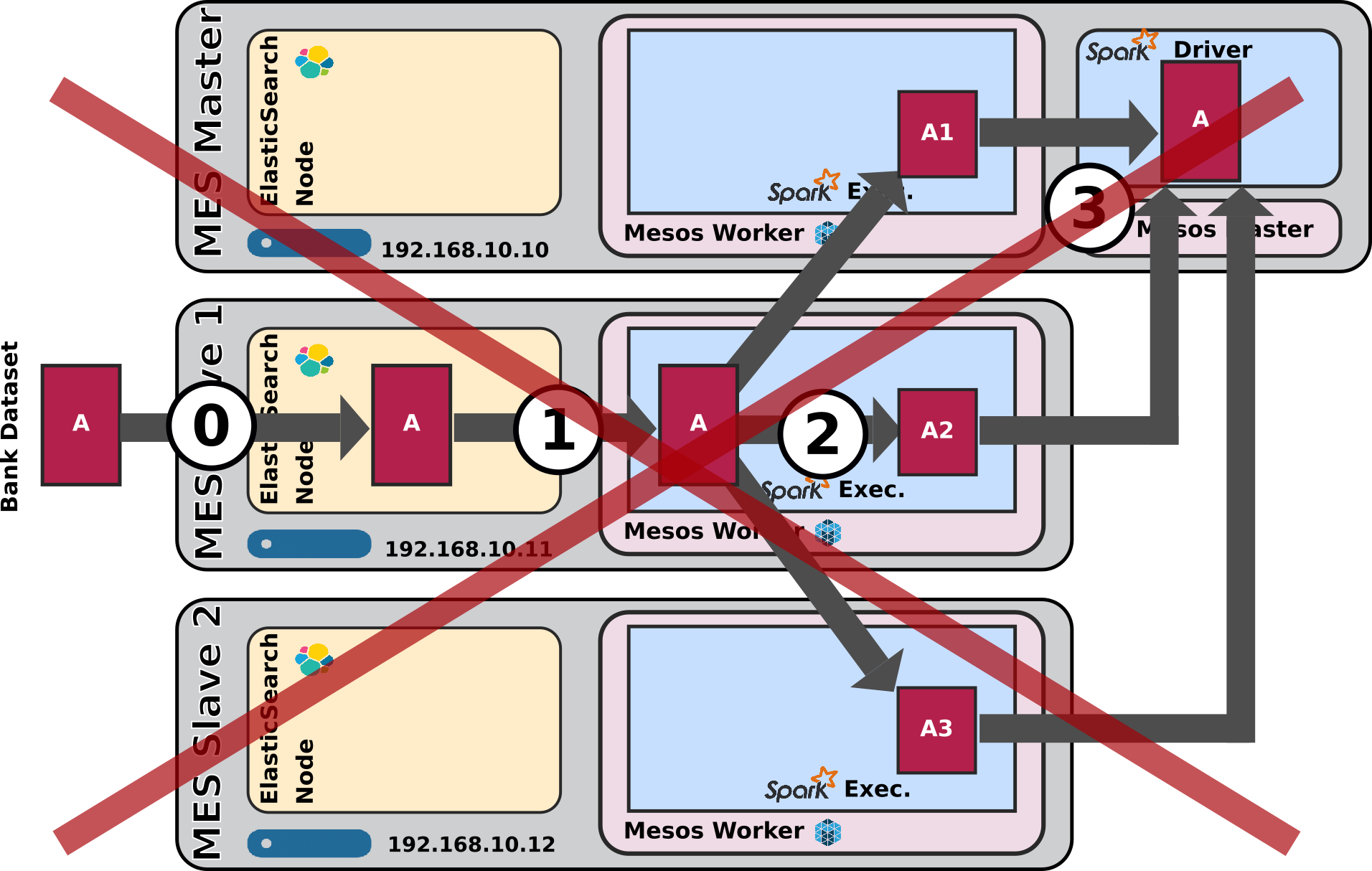
Conclusions
- I haven't been able to make repartitioning work the way I intended it to work.
- Eventually all of my tests led to the underlying RDD being repartitioned, but all the partitions remain local to the initially owning node
- I never managed to find a way to make the Spark cluster redistribute the different partitions to the various Spark executors from the cluster
- I don't know if that comes from Spark somehow knowing that it doesn't need to do that for the post-processing to be done efficiently.
- Long story short, I have no real conclusions in this regards, reason why the above schema is crossed by an X.
5.3 Aggregation tests
Aggregation tests - assess how aggregation on ES data works.
5.3.1 ES-side Aggregations
Test details
- Test Script:
3_aggregation_1_es_shakespeare_rdd_legacy_NOT_WORKING.sh - Input Dataset: Shakespeare's Works Dataset from https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json
- Purpose: see how Spark can exploit native ElasticSearch features such as ES-side aggregations instead of performing aggregations on its own.
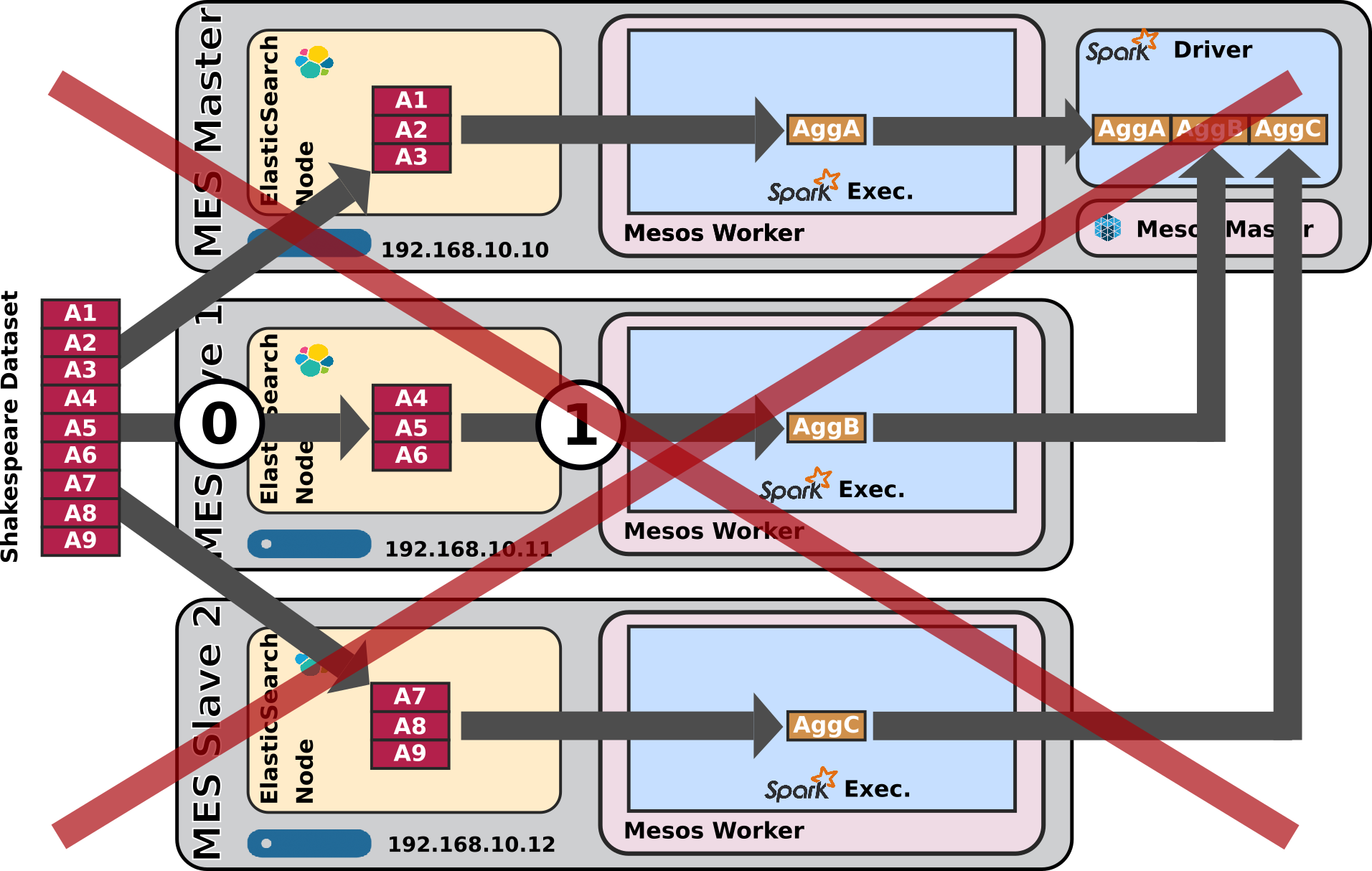
Expected Behaviour
Relevant portion of spark Script
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext
# Spark configuration
conf = SparkConf().setAppName("ESTest_3_1")
# SparkContext and SQLContext
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
# -> query dsl
es_aggregations_query = '''
{
"query" : { "match_all": {} },
"size" : 0,
"aggregations" : {
"play_name": {
"terms": {
"field" : "play_name"
}
}
}
}
'''
es_read_conf = {
"es.resource" : "shakespeare",
"es.endpoint" : "_search",
"es.query" : es_aggregations_query
}
# (1)
es_rdd = sc.newAPIHadoopRDD(
inputFormatClass="org.elasticsearch.hadoop.mr.EsInputFormat",
keyClass="org.apache.hadoop.io.NullWritable",
valueClass="org.elasticsearch.hadoop.mr.LinkedMapWritable",
conf=es_read_conf)
es_df = sqlContext.createDataFrame(es_rdd)
# I need to collect the result
data_list = es_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s rows (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 3_aggregation_1_es_shakespeare_rdd_legacy.log
- Screenshots from the various admin console after the test execution:
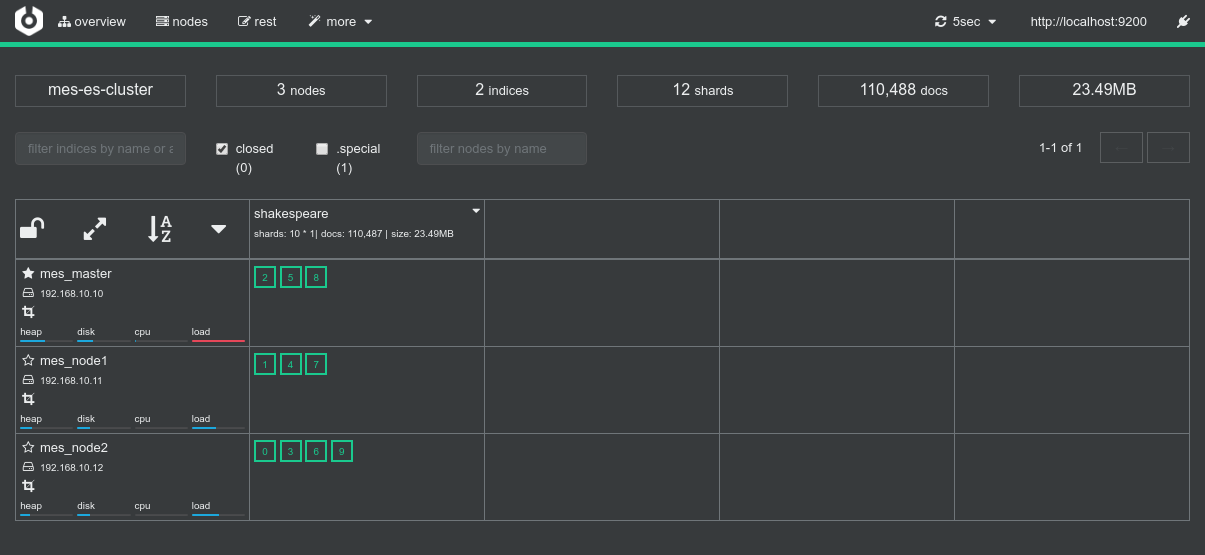
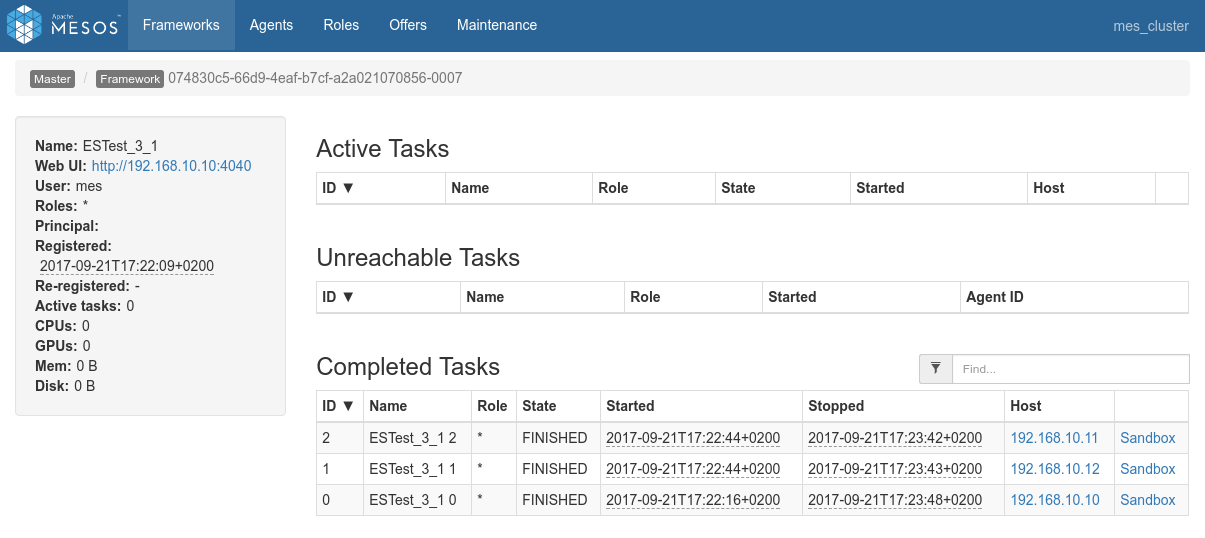
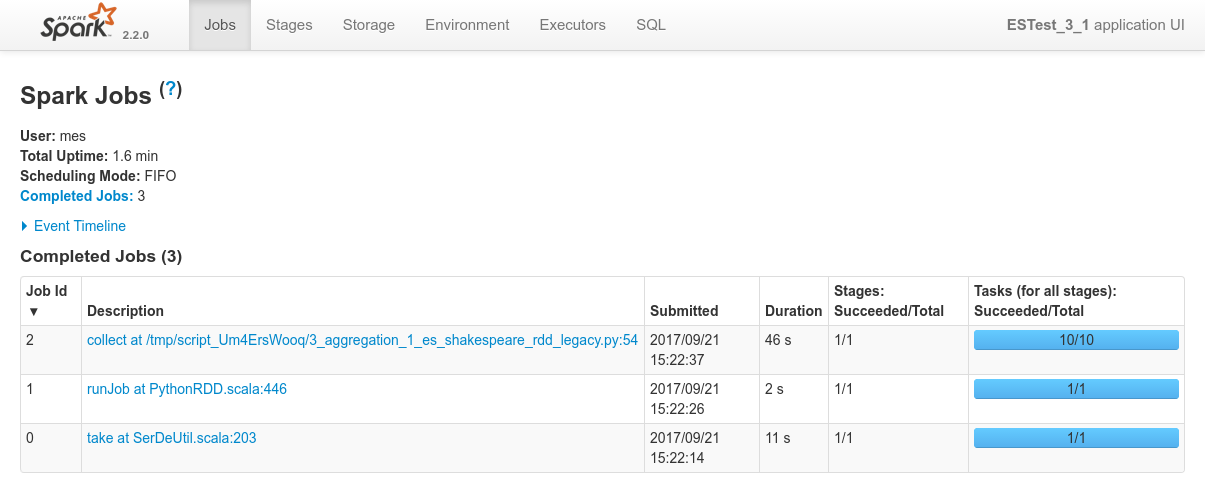
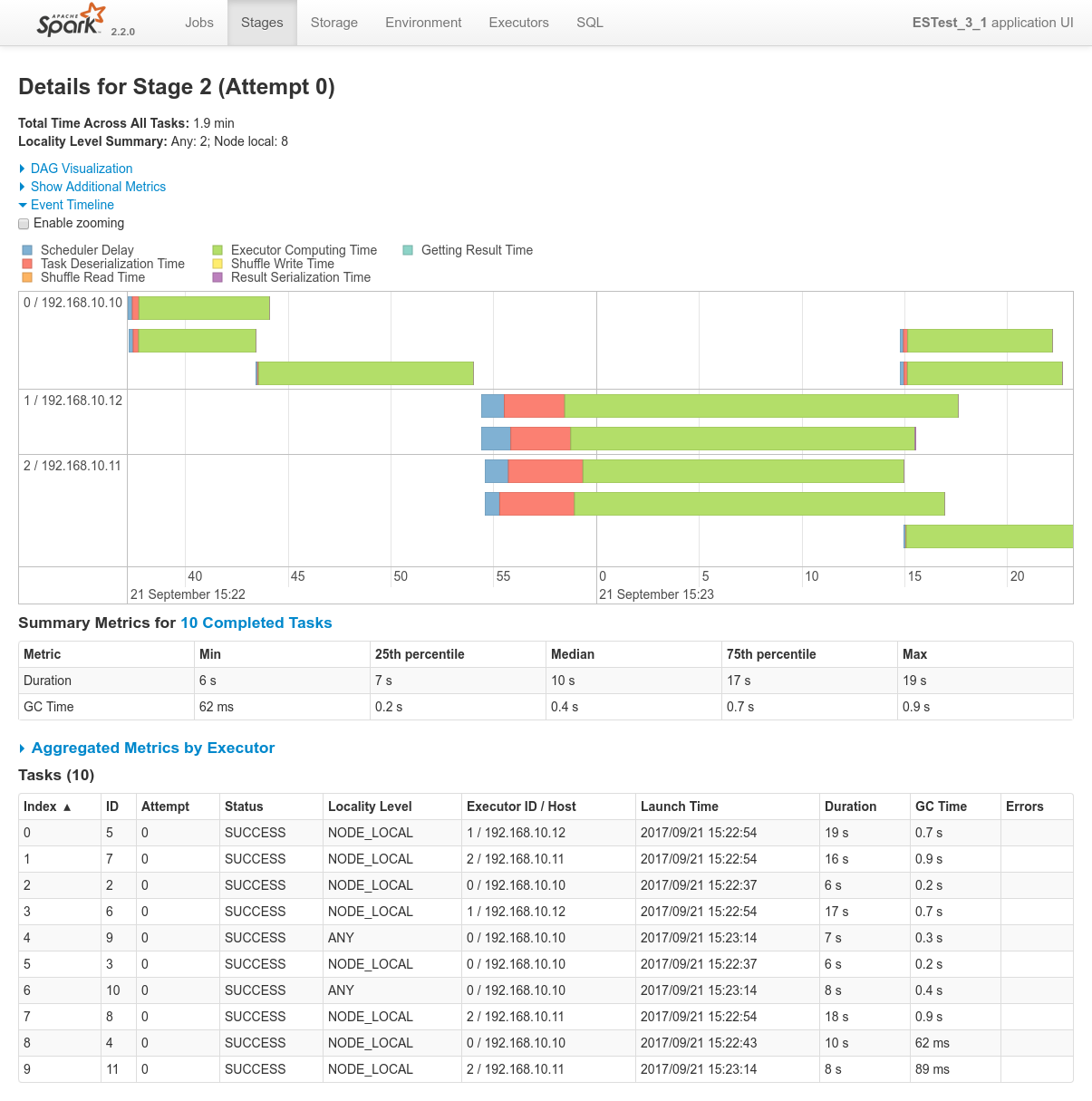
Conclusions
- There is simply no way at the moment to submit specific requests, such as aggregation requests, from spark to ElasticSearch using the ES-Hadoop connector.
- The need is well identified but the solution is still work in progress: https://github.com/elastic/elasticsearch-hadoop/issues/276
- Since it's impossible to make this work as expected, the schematic above is crossed with an X.
5.3.2 Spark-side Aggregations
Test details
- Test Script:
3_aggregation_2_spark_shakespeare.sh - Input Dataset: Shakespeare's Works Dataset from https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json
- Purpose: see how Spark performs aggregations on its own.
Expected Behaviour
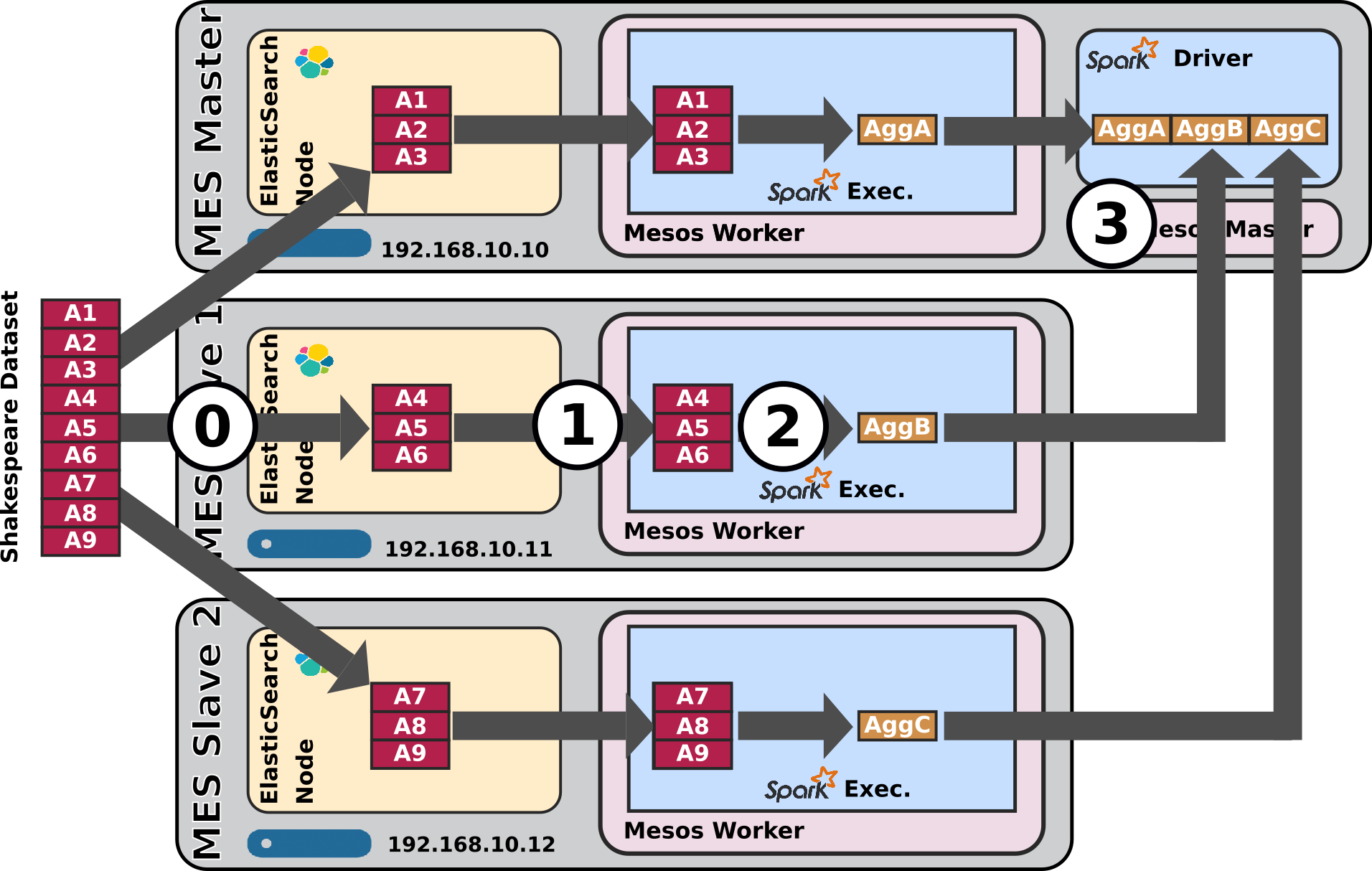
Relevant portion of spark Script
from pyspark.conf import SparkConf
from pyspark.sql import SQLContext, SparkSession
# Spark configuration
conf = SparkConf().setAppName("ESTest_3_2")
# Every time there is a shuffle, Spark needs to decide how many partitions will
# the shuffle RDD have.
# 2 times the amount of CPUS on the cluster is a good value (default is 200)
conf.set("spark.sql.shuffle.partitions", "12")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# Query configuration only (cannot pass any ES conf here :-( )
es_query_conf= {
"pushdown": True
}
# (1)
es_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("shakespeare*")
# (2) Compute aggregates : I want the count of lines per book
agg_df = es_df.groupBy(es_df.play_name).count()
# (3) Collect result to the driver
data_list = agg_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Fetched %s rows (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 3_aggregation_2_spark_shakespeare.log
- Screenshots from the various admin console after the test execution:
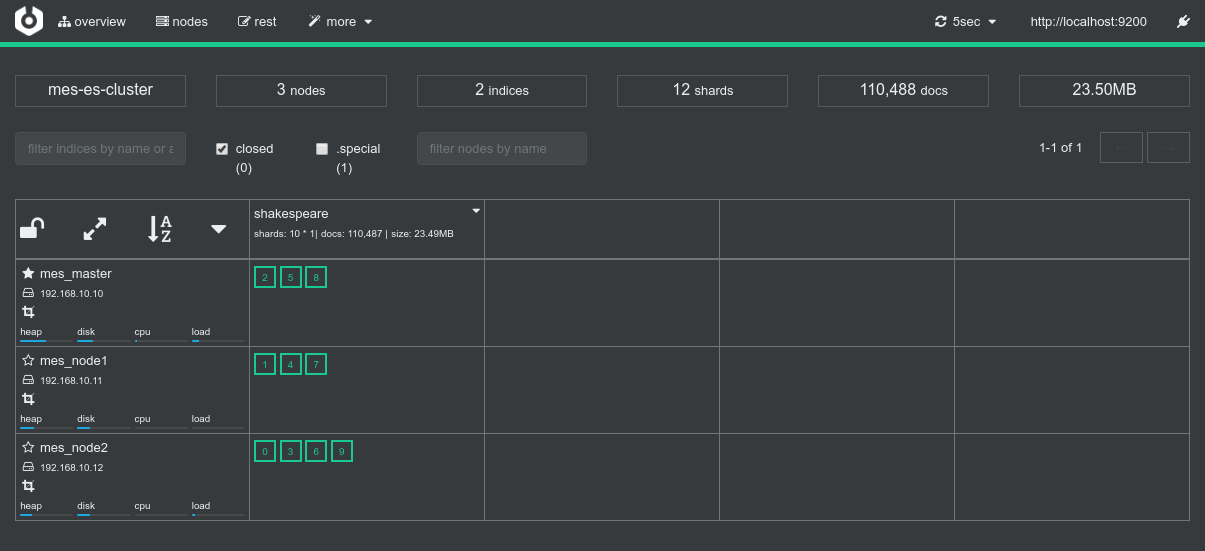
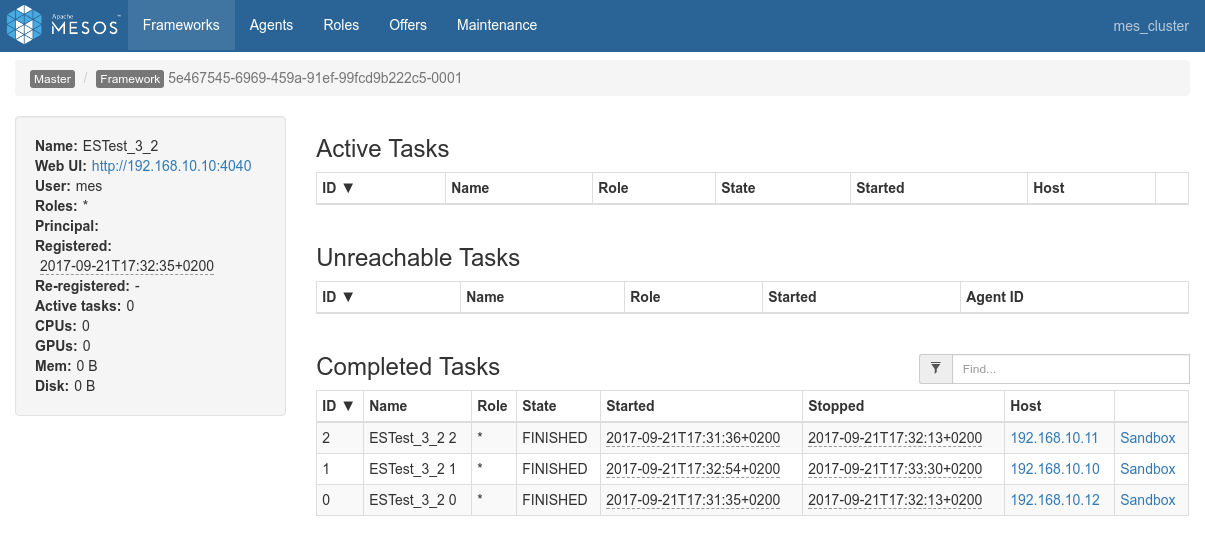
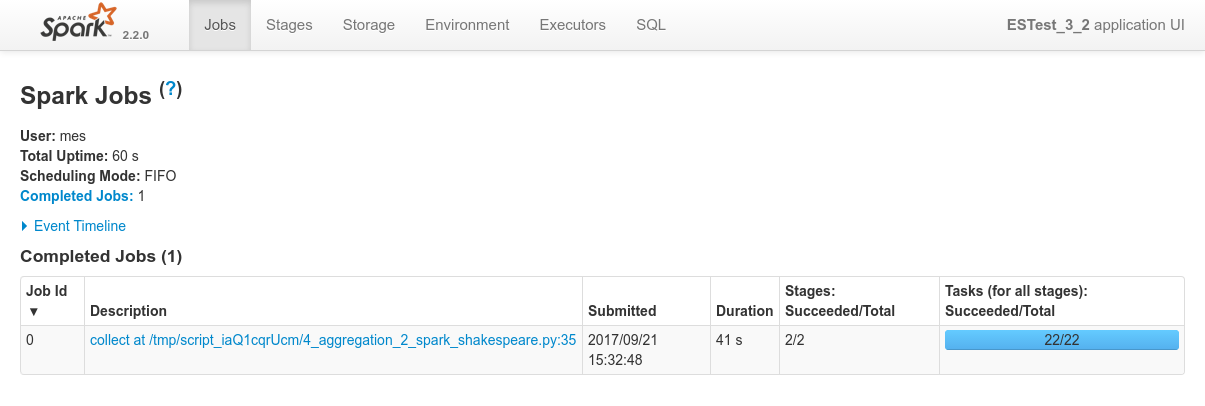
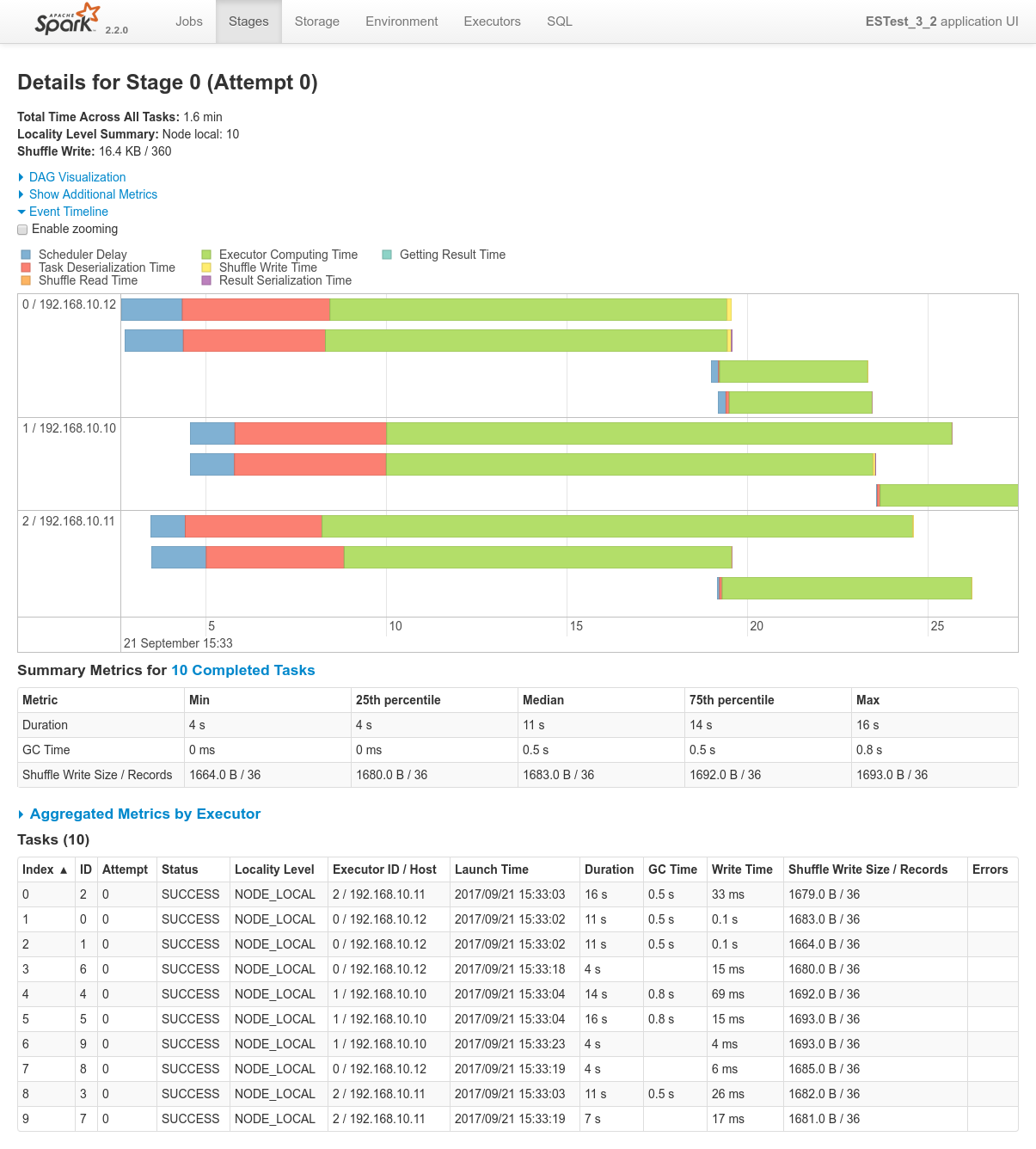
Conclusions
- There aren't a lof of things to conclude here. We can just mention that everything works as expected and return the user to the Data Flow schematic above.
- Data locality kicks-in, etc.
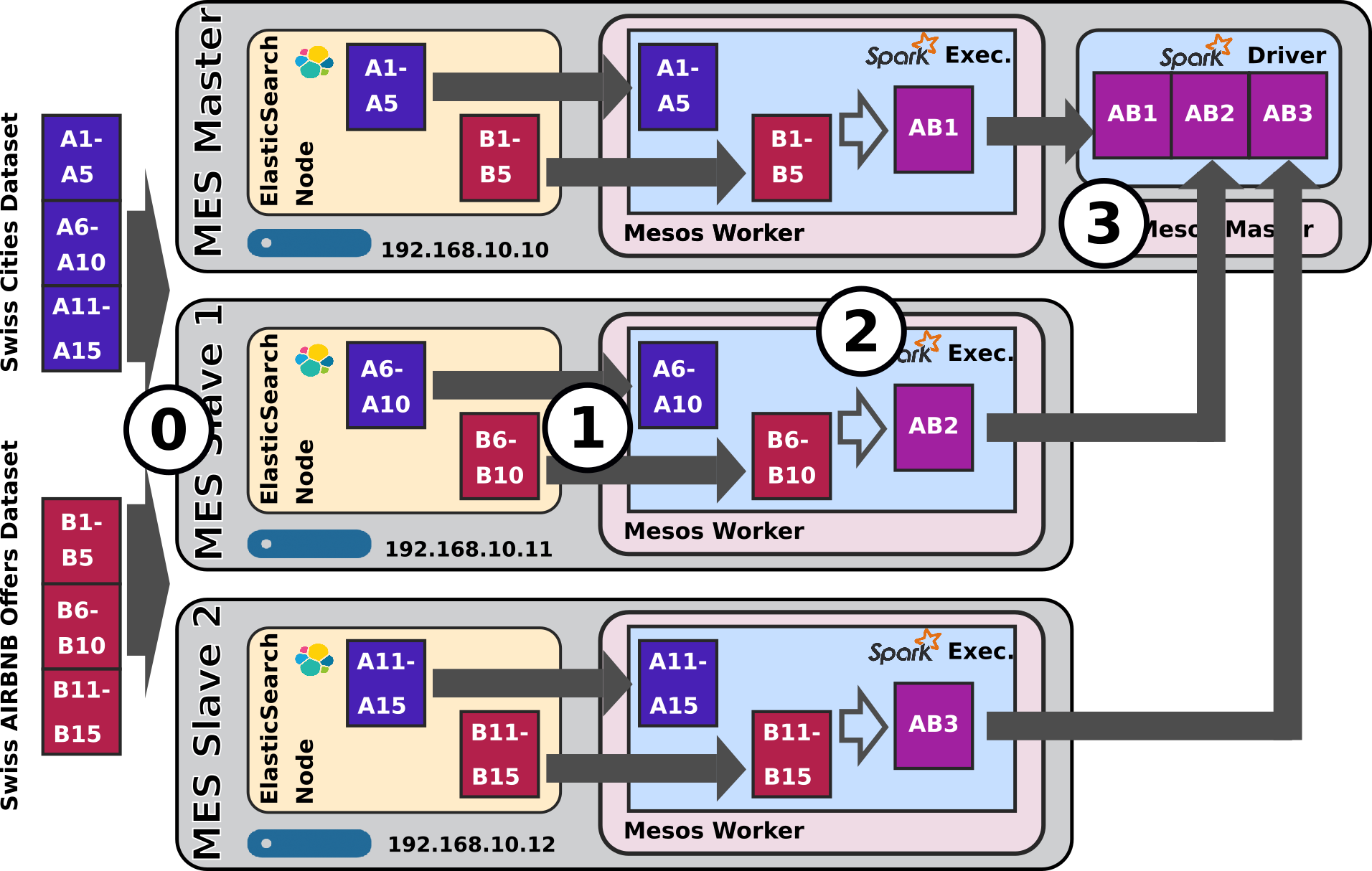
5.4 Join test
Test details
- Test Script:
4_join_1_swissdata_df.sh - Input Dataset: two datasets in fact:
- from http://niceideas.ch/mes/swissairbnb/tomslee_airbnb_switzerland_1451_2017-07-11.csv : the list of AirBnB offers in Switzerland as of July 2017.
- from http://niceideas.ch/mes/swissairbnb/swisscitiespop.txt : the list of swiss cities with population and geoloc information.
- Purpose: see how the ELK-MS stack behaves when its has several datasets to load from ES into Spark and then join.
Expected Behaviour
Relevant portion of spark Script
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext, SparkSession
import pyspark.sql.functions as F
# Spark configuration
# all these options can be given to the command line to spark-submit
# (they would need to be prefixed by "spark.")
conf = SparkConf().setAppName("ESTest_4_1")
# Every time there is a shuffle, Spark needs to decide how many partitions will
# the shuffle RDD have.
# 2 times the amount of CPUS oi nthe cluster is a good value (default is 200)
conf.set("spark.sql.shuffle.partitions", "12")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# Query configuration only (cannot pass any ES conf here :-( )
es_query_conf= {
"pushdown": True
}
# (1).1 Read city and population
citypop_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("swiss-citypop") \
.alias("citypop_df")
# (1).2. Read airbnb offers
airbnb_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("swiss-airbnb") \
.alias("airbnb_df")
# (2) Join on city
joint_df = airbnb_df \
.join( \
citypop_df, \
(F.lower(airbnb_df.city) == F.lower(citypop_df.accent_city)), \
"left_outer" \
) \
.select( \
'room_id', 'airbnb_df.country', 'airbnb_df.city', \
'room_type', 'bedrooms', 'bathrooms', 'price', 'reviews', \
'overall_satisfaction', \
'airbnb_df.latitude', 'airbnb_df.longitude', \
'citypop_df.latitude', 'citypop_df.longitude', 'population', \
'region' \
)
# (3) Collect result to the driver
data_list = joint_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Computed %s positions (from collected list)") % len (data_list)
Results
- Logs of the Spark Driver: 4_join_1_swissdata_df.log
- Screenshots from the various admin console after the test execution:
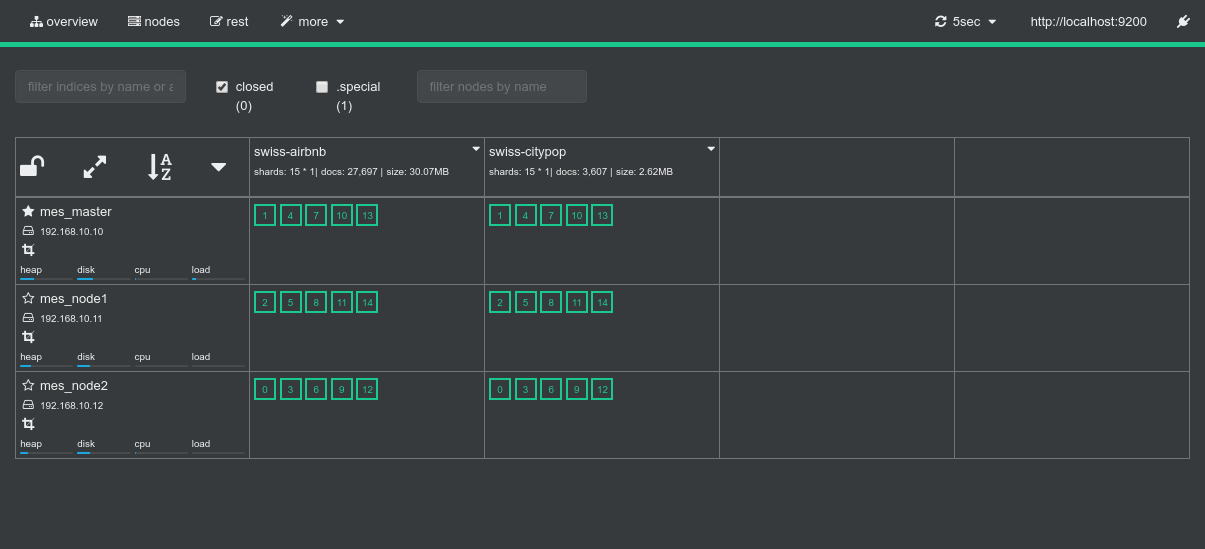
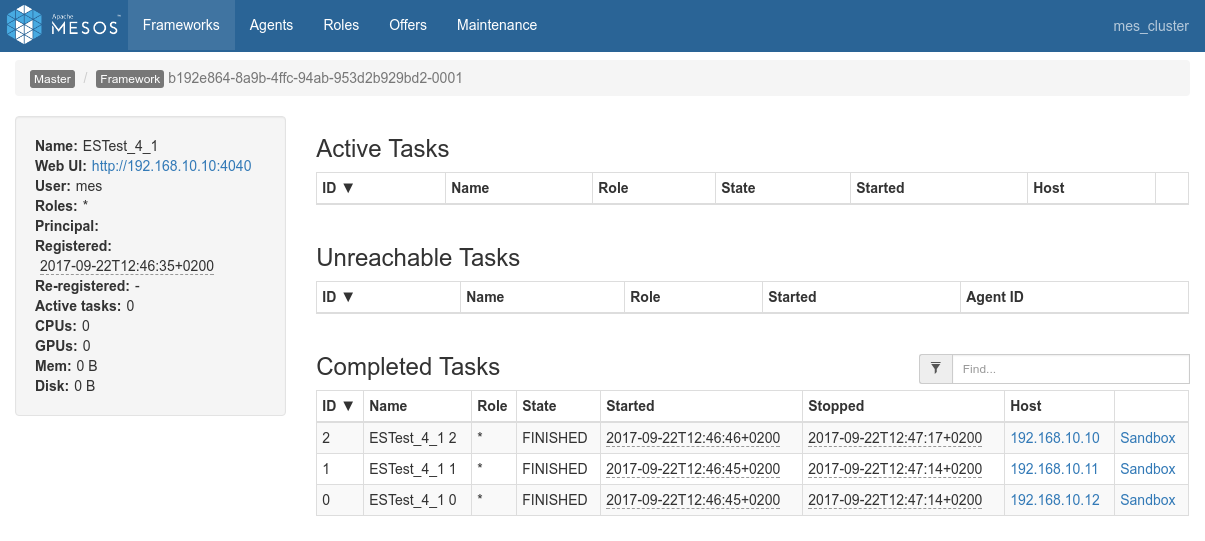
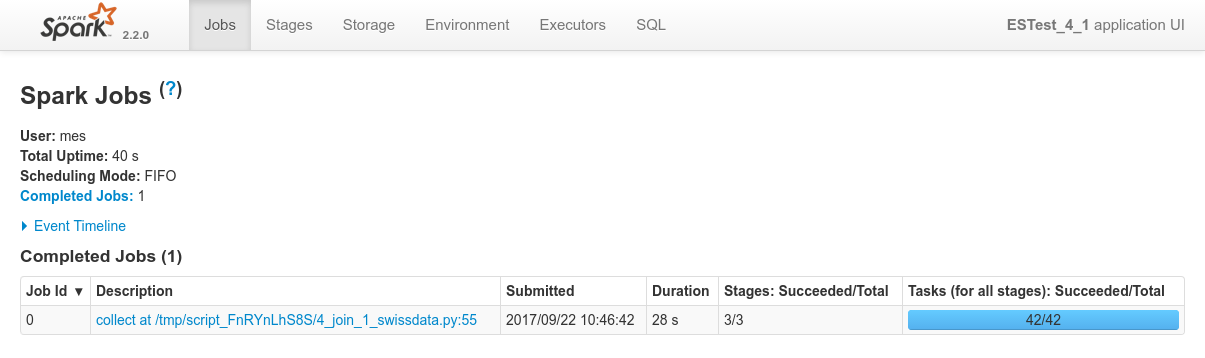
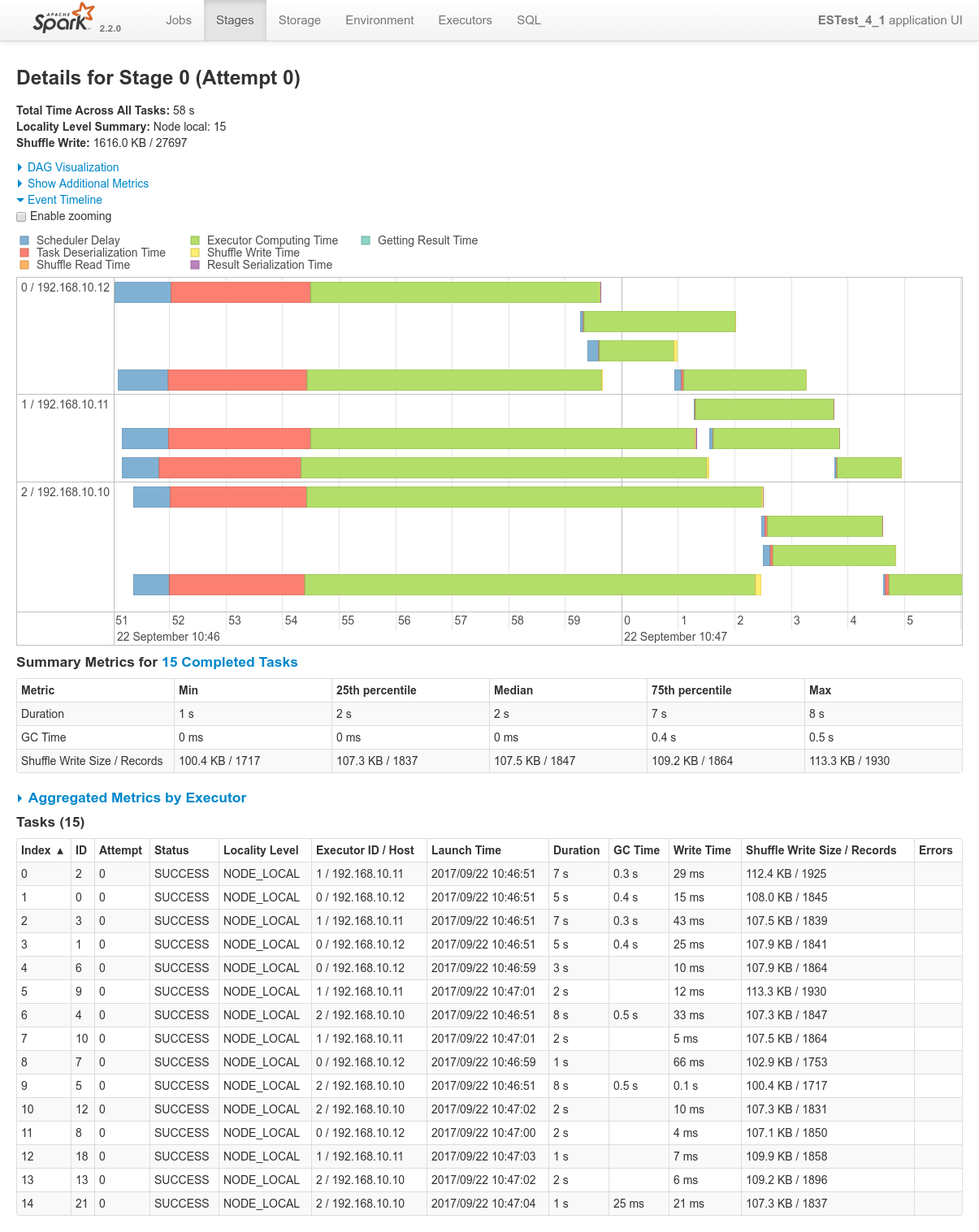
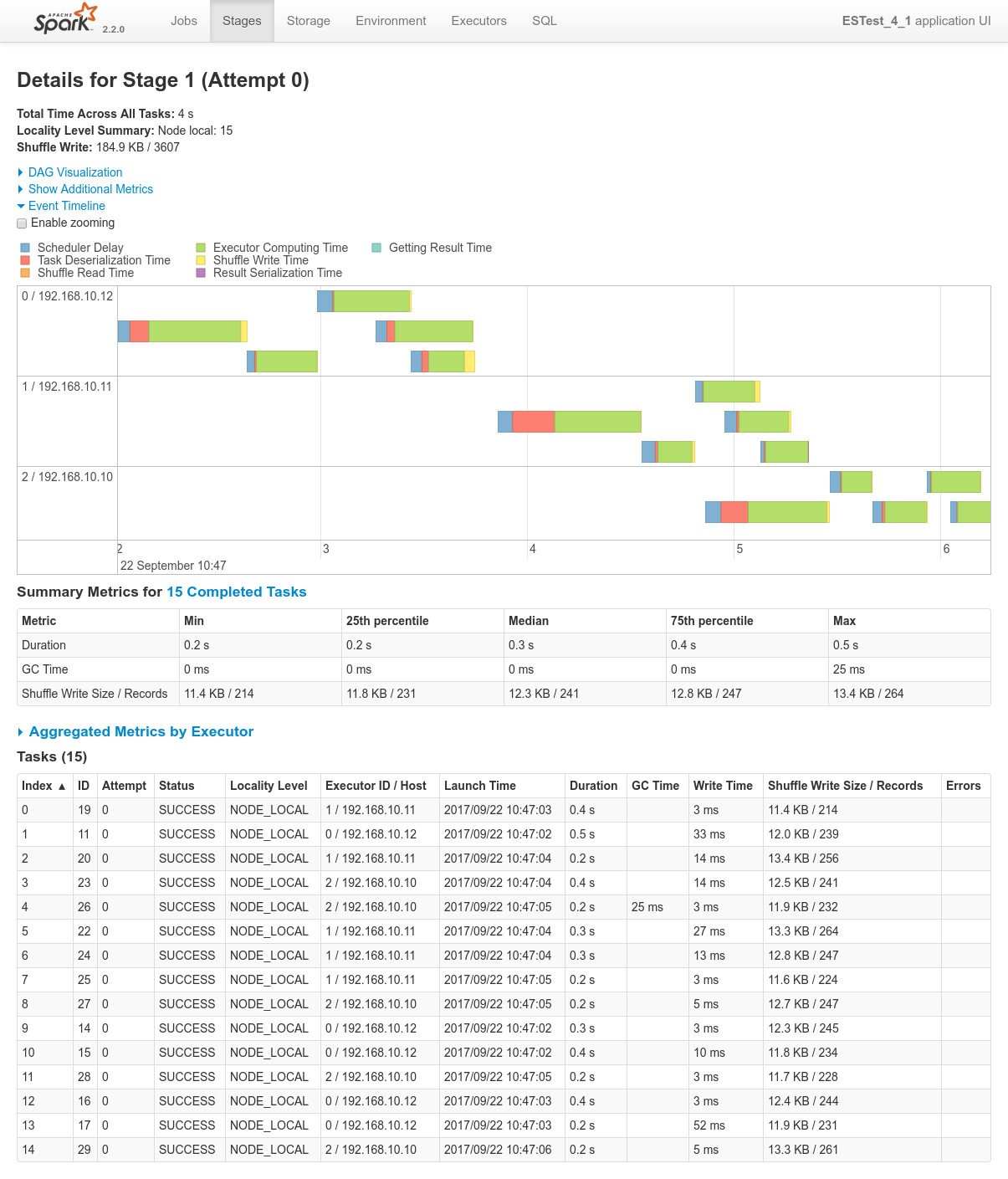
Conclusions
- Here as well there aren't a log of things to conclude. Everything works just as expected.
- Data locality kicks-in both at the ES data fetching side and on the private Spark Side for the join.
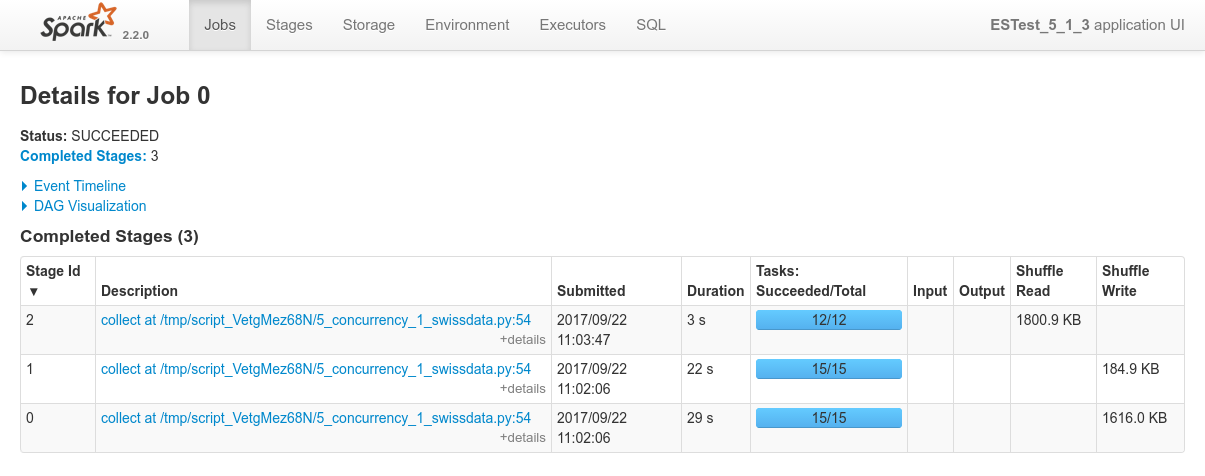
5.5 Concurrency test
Test details
- Test Script:
5_concurrency_1_swissdata_df.sh - Input Dataset: two datasets in fact:
- from http://niceideas.ch/mes/swissairbnb/tomslee_airbnb_switzerland_1451_2017-07-11.csv : the list of AirBnB offers in Switzerland as of July 2017.
- from http://niceideas.ch/mes/swissairbnb/swisscitiespop.txt : the list of swiss cities with population and geoloc information.
- Purpose: see how the ELK-MS stack behaves when submitting several jobs at the same time to the cluster and what happens in terms of concurrency.
The Spark Script
The concurrency tests simply executes four times in parallel the scenario inspired from 5.3.2 Spark-side Aggregations as follows:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SQLContext, SparkSession
import pyspark.sql.functions as F
# Spark configuration
conf = SparkConf()
# Every time there is a shuffle, Spark needs to decide how many partitions will
# the shuffle RDD have.
# 2 times the amount of CPUS on the cluster is a good value (default is 200)
conf.set("spark.sql.shuffle.partitions", "12")
# Spark SQL Session
ss = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()
# Query configuration only (cannot pass any ES conf here :-( )
es_query_conf= {
"pushdown": True
}
# 1. Read city and population
citypop_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("swiss-citypop") \
.alias("citypop_df")
# 2. Read airbnb offers
airbnb_df = ss.read \
.format("org.elasticsearch.spark.sql") \
.options(conf=es_query_conf) \
.load("swiss-airbnb") \
.alias("airbnb_df")
# 3. Join on city
joint_df = airbnb_df \
.join( \
citypop_df, \
(F.lower(airbnb_df.city) == F.lower(citypop_df.accent_city)), \
"left_outer" \
) \
.select( \
'room_id', 'airbnb_df.country', 'airbnb_df.city', \
'room_type', 'bedrooms', 'bathrooms', 'price', 'reviews', \
'overall_satisfaction', \
'airbnb_df.latitude', 'airbnb_df.longitude', \
'citypop_df.latitude', 'citypop_df.longitude', 'population', \
'region' \
)
# Collect result to the driver
data_list = joint_df.collect()
print ("Printing 10 first results")
for x in data_list[0:10]:
print x
# Print count
print ("Computed %s positions (from collected list)") % len (data_list)
Results
- The various logs:
- Logs of the script : 5_concurrency_1_swissdata_df.log
- Process P1 logs : log_5_concurrency_1_swissdata_1.log
- Process P2 logs : log_5_concurrency_1_swissdata_2.log
- Process P3 logs : log_5_concurrency_1_swissdata_3.log
- Process P4 logs : log_5_concurrency_1_swissdata_4.log
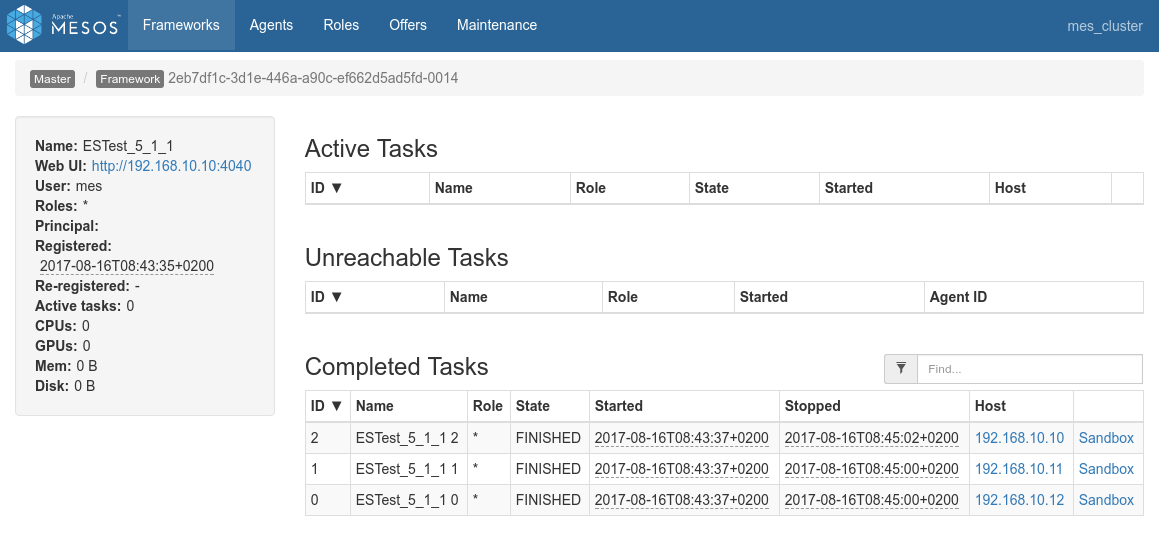
- Screenshots from the various admin console after the test execution:
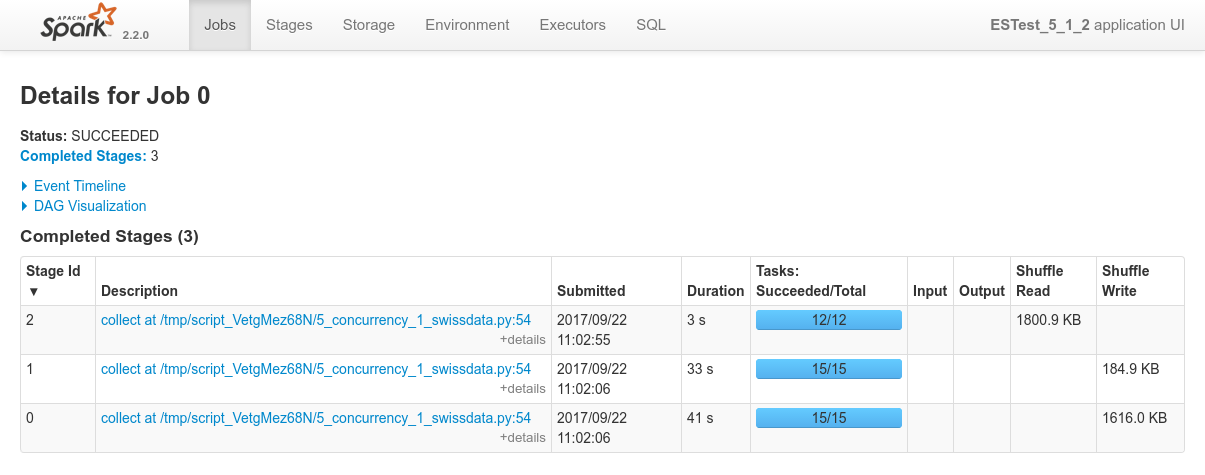
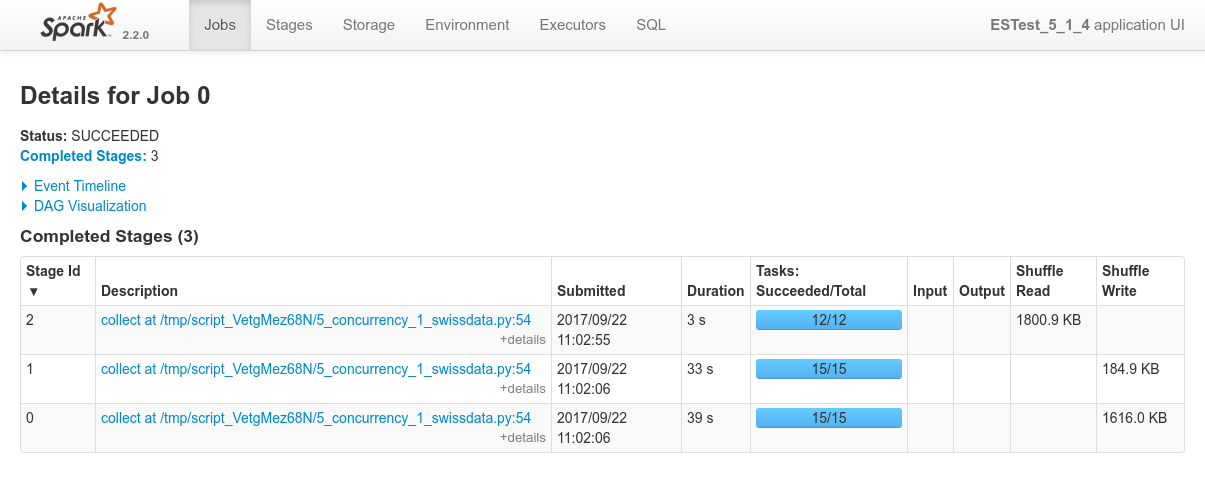
First the mesos console showing the completion of the 4 jobs:
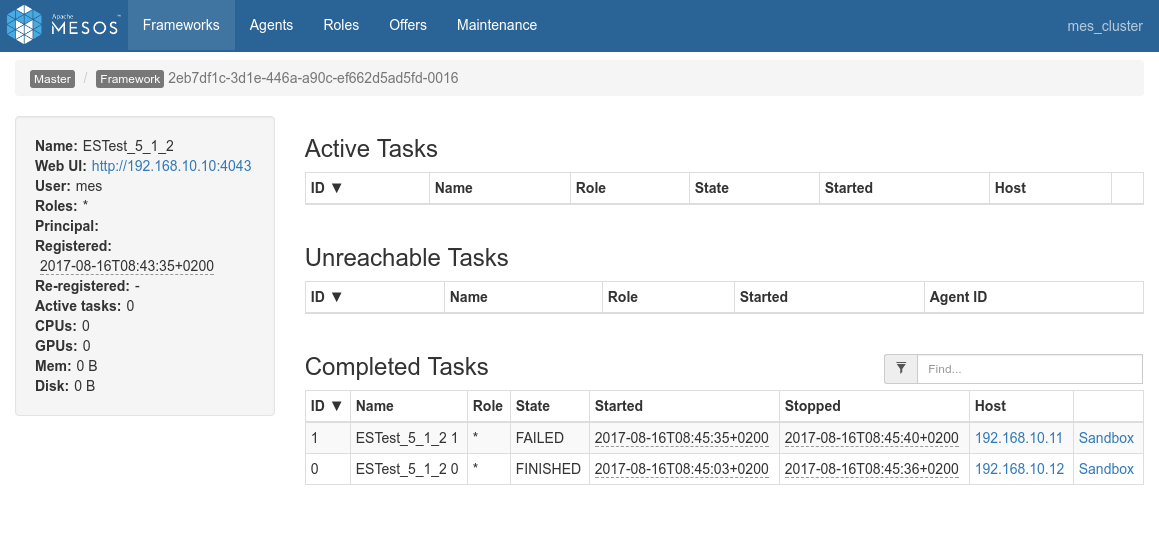
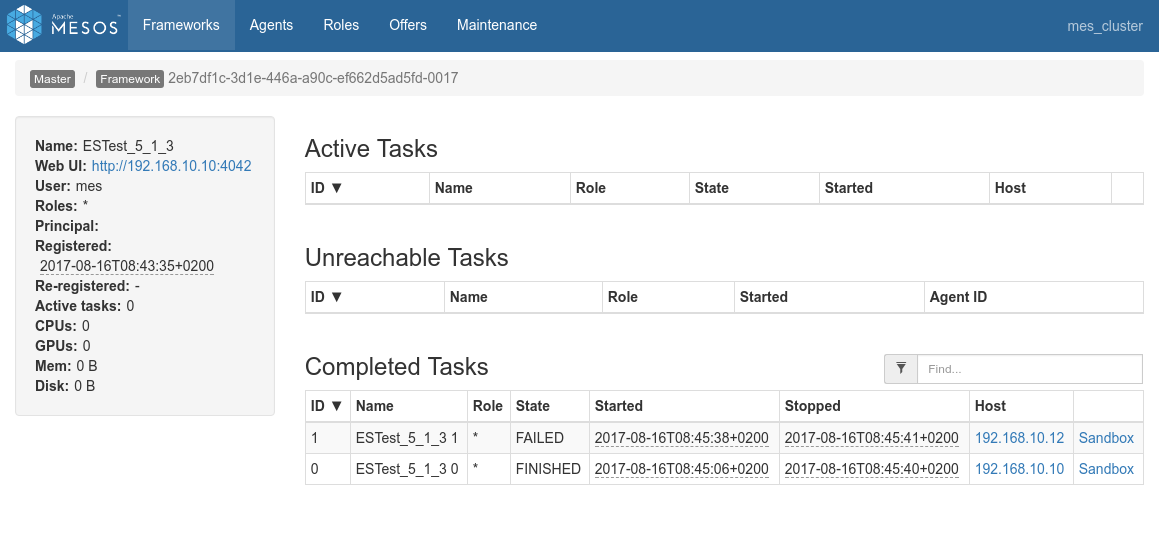
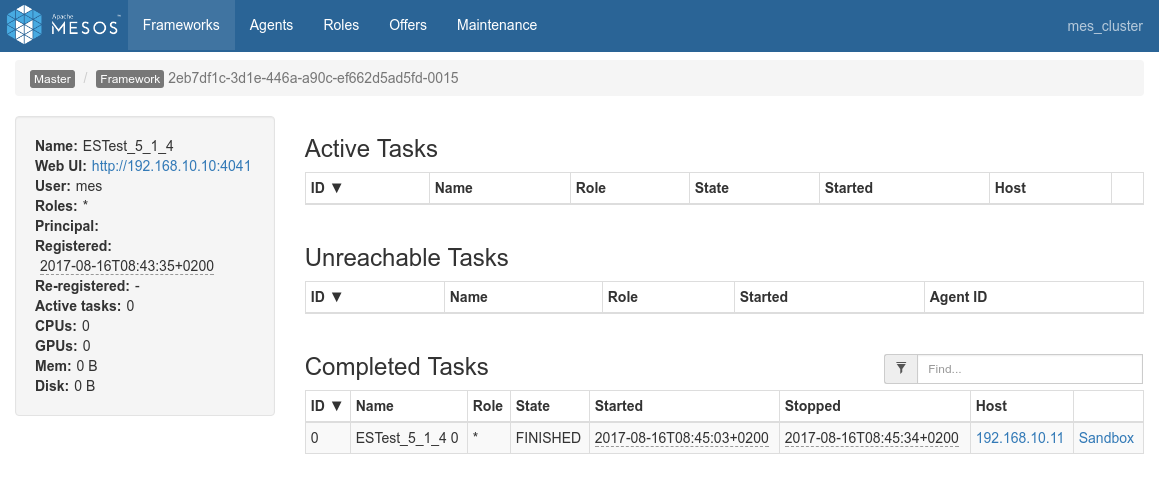
Overview of the 4 processes in Spark console, the specific view of each of the process:
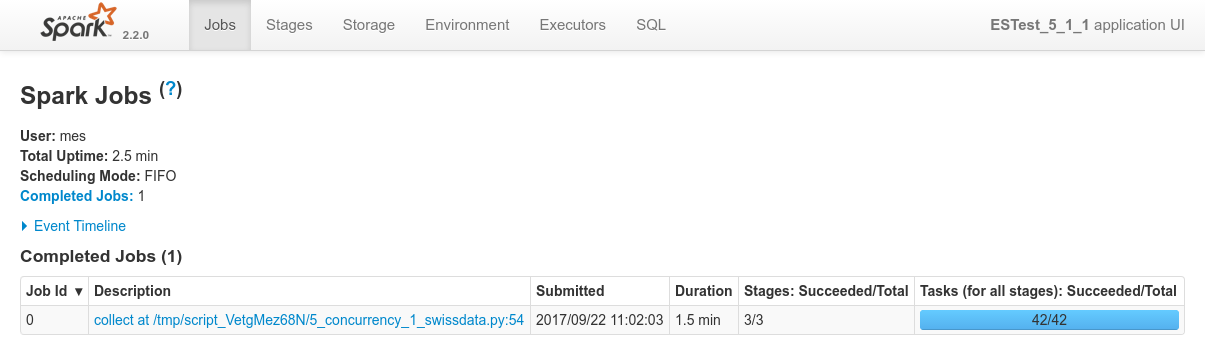
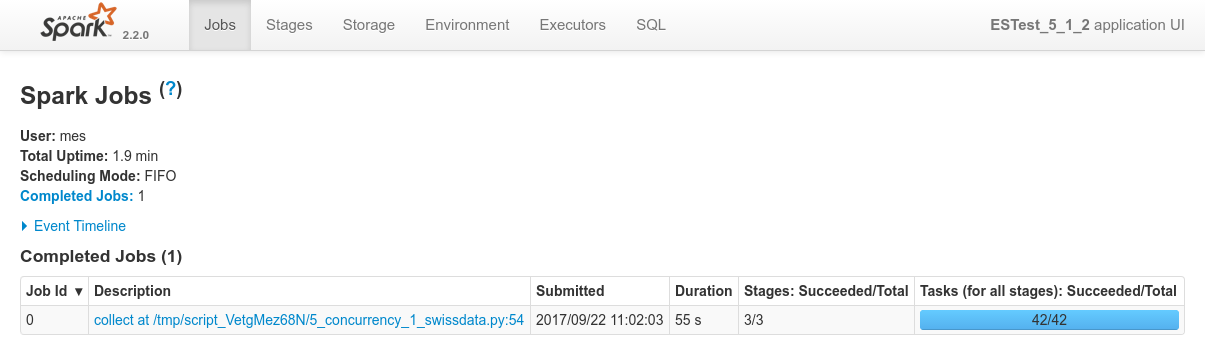
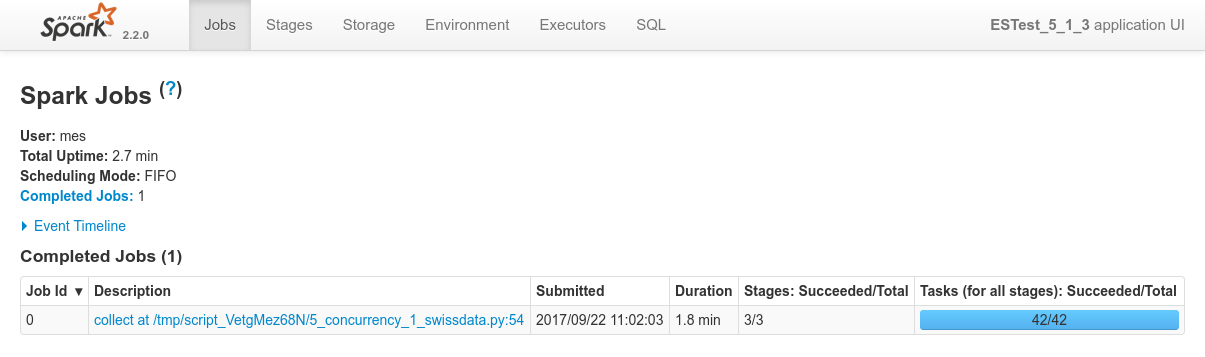
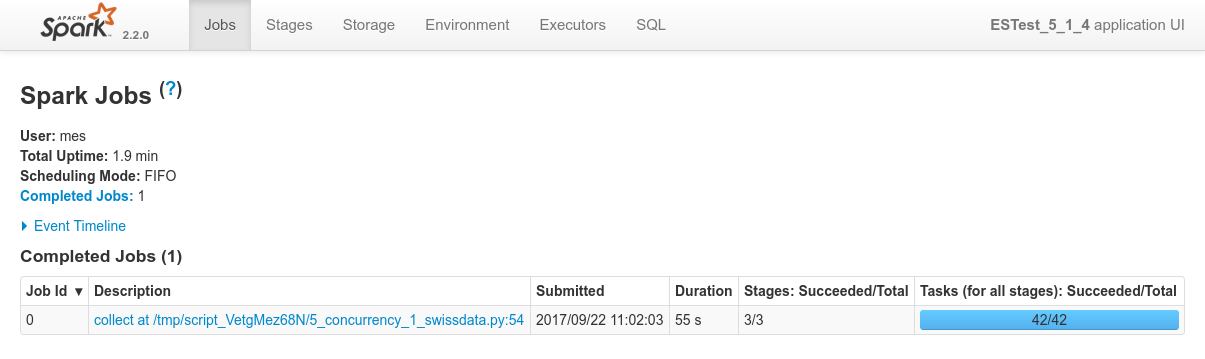
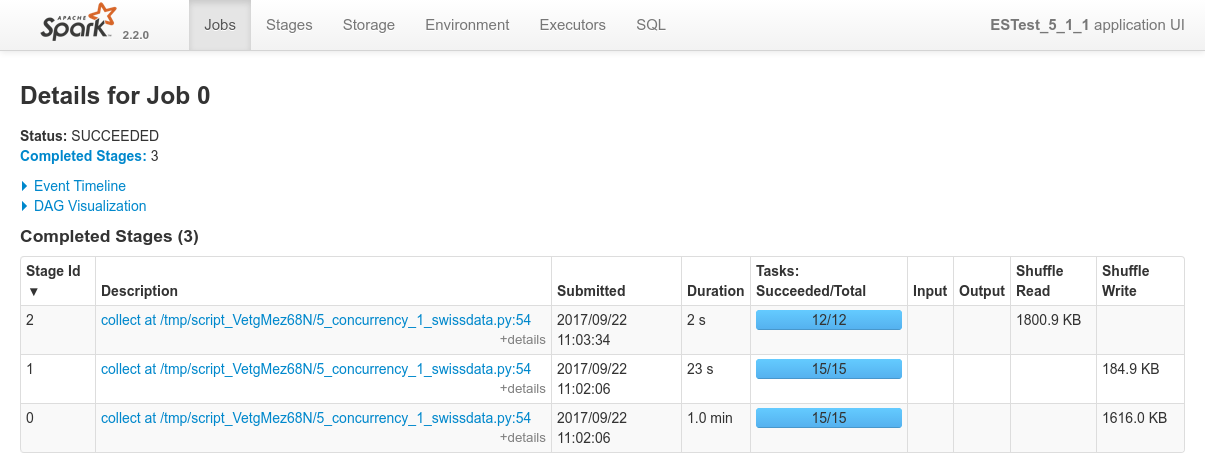
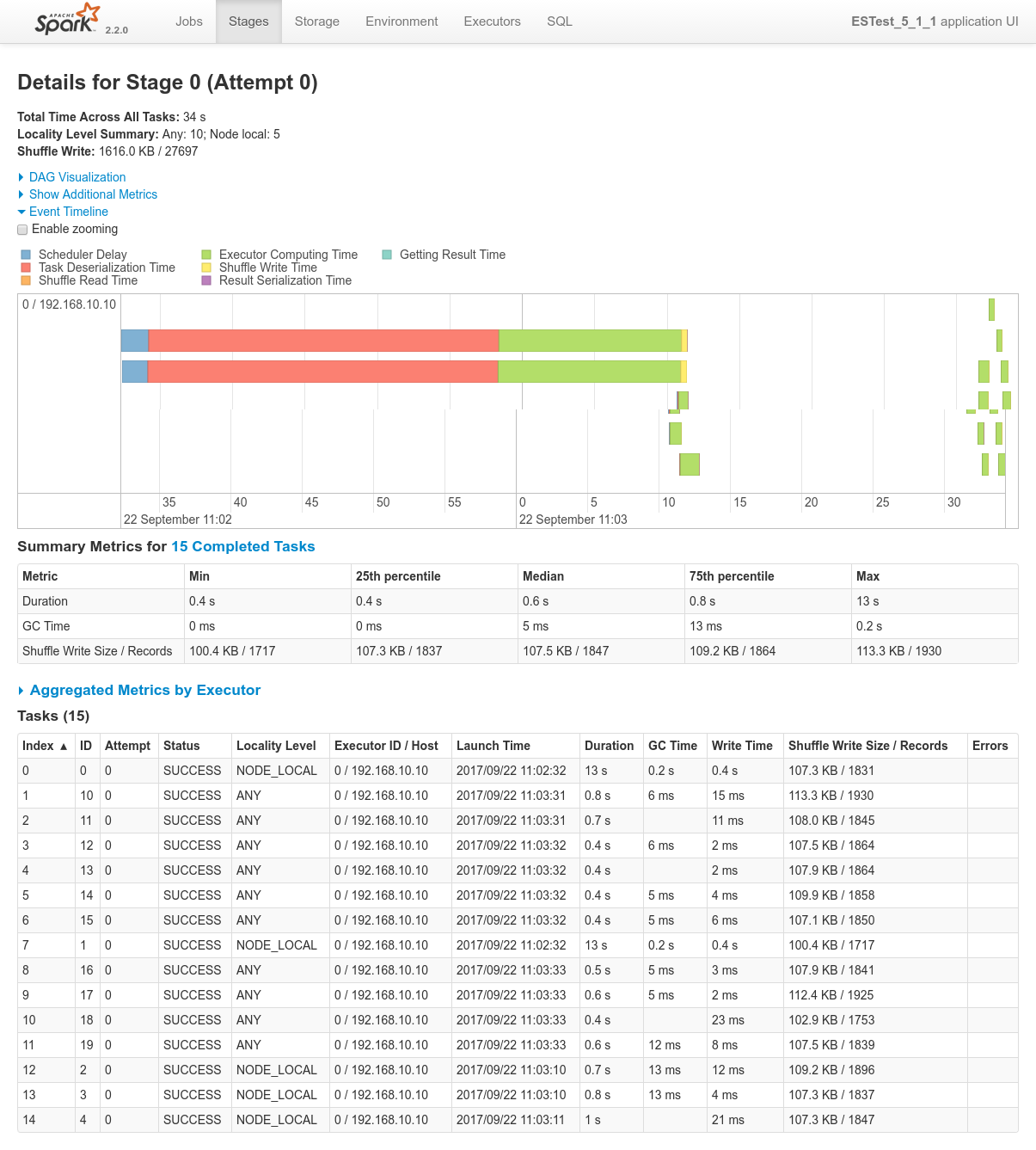
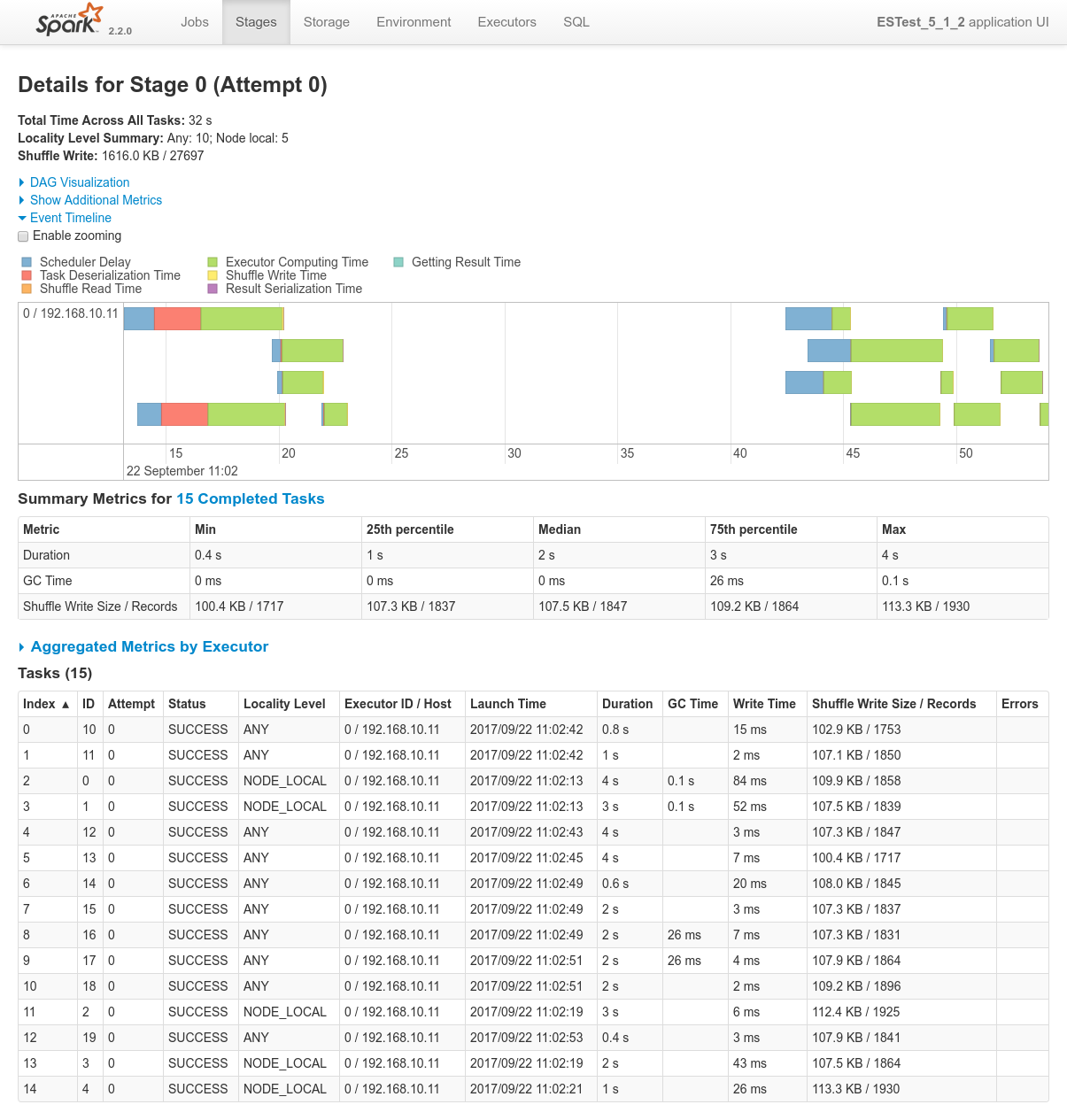
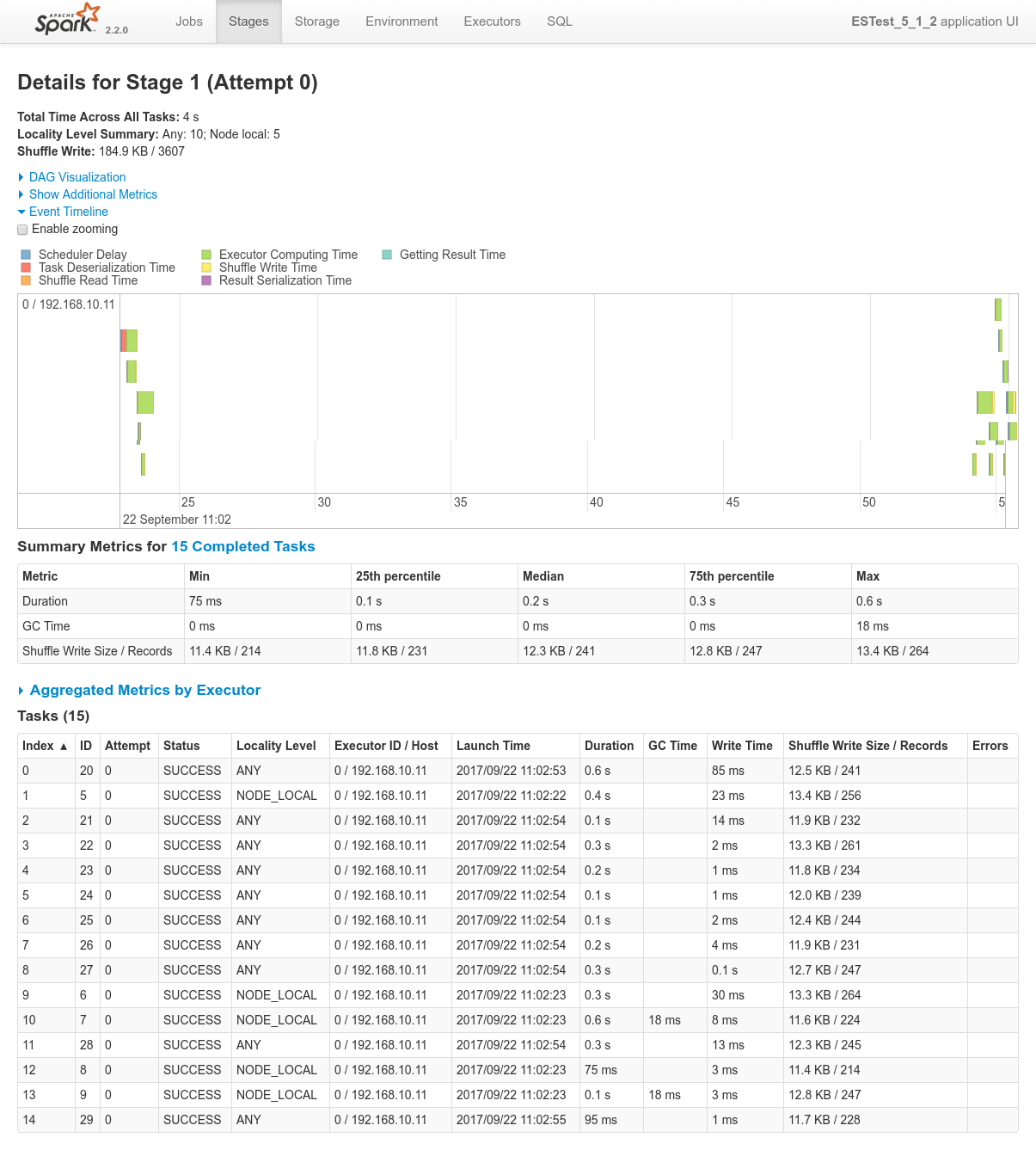
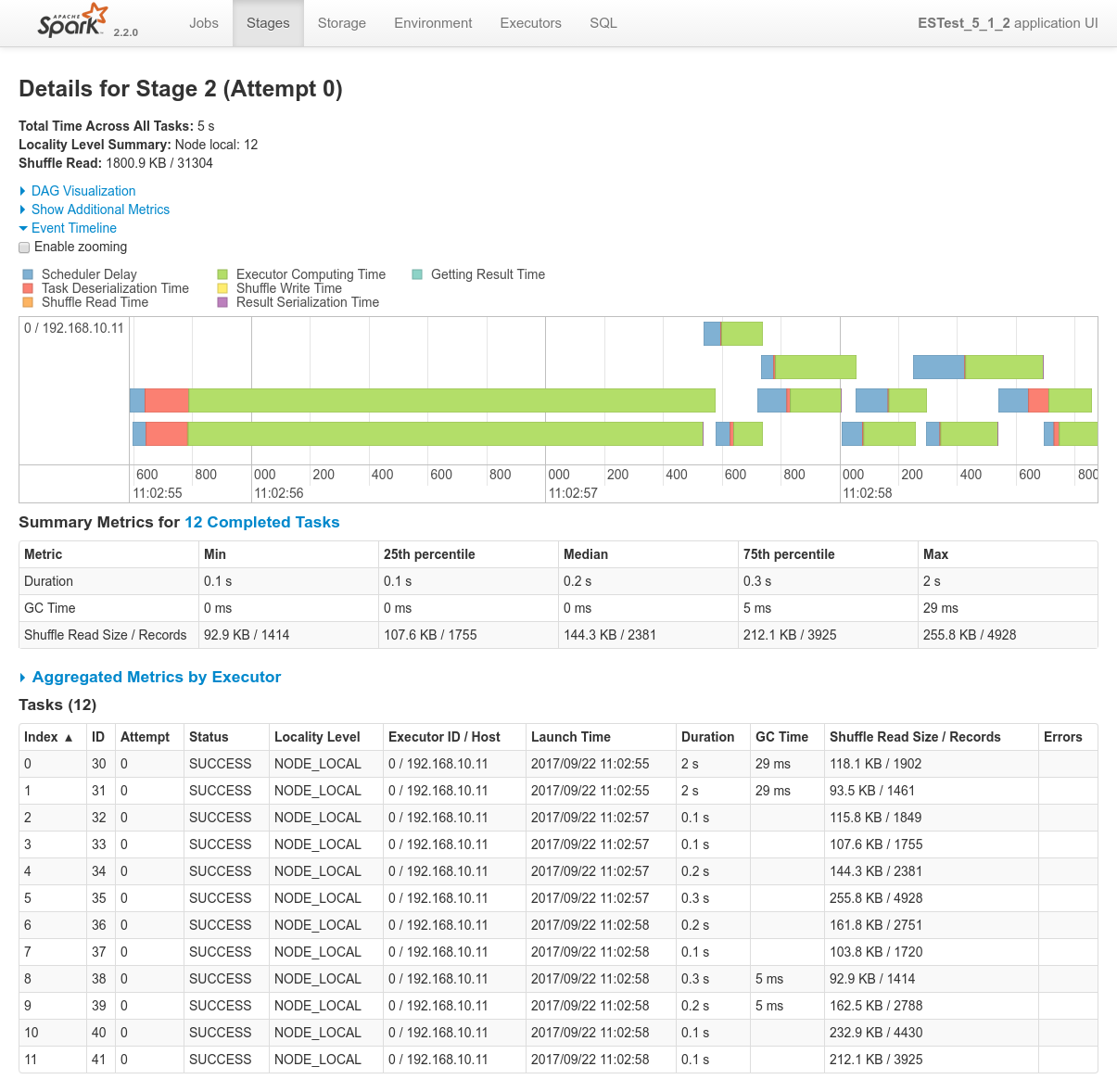
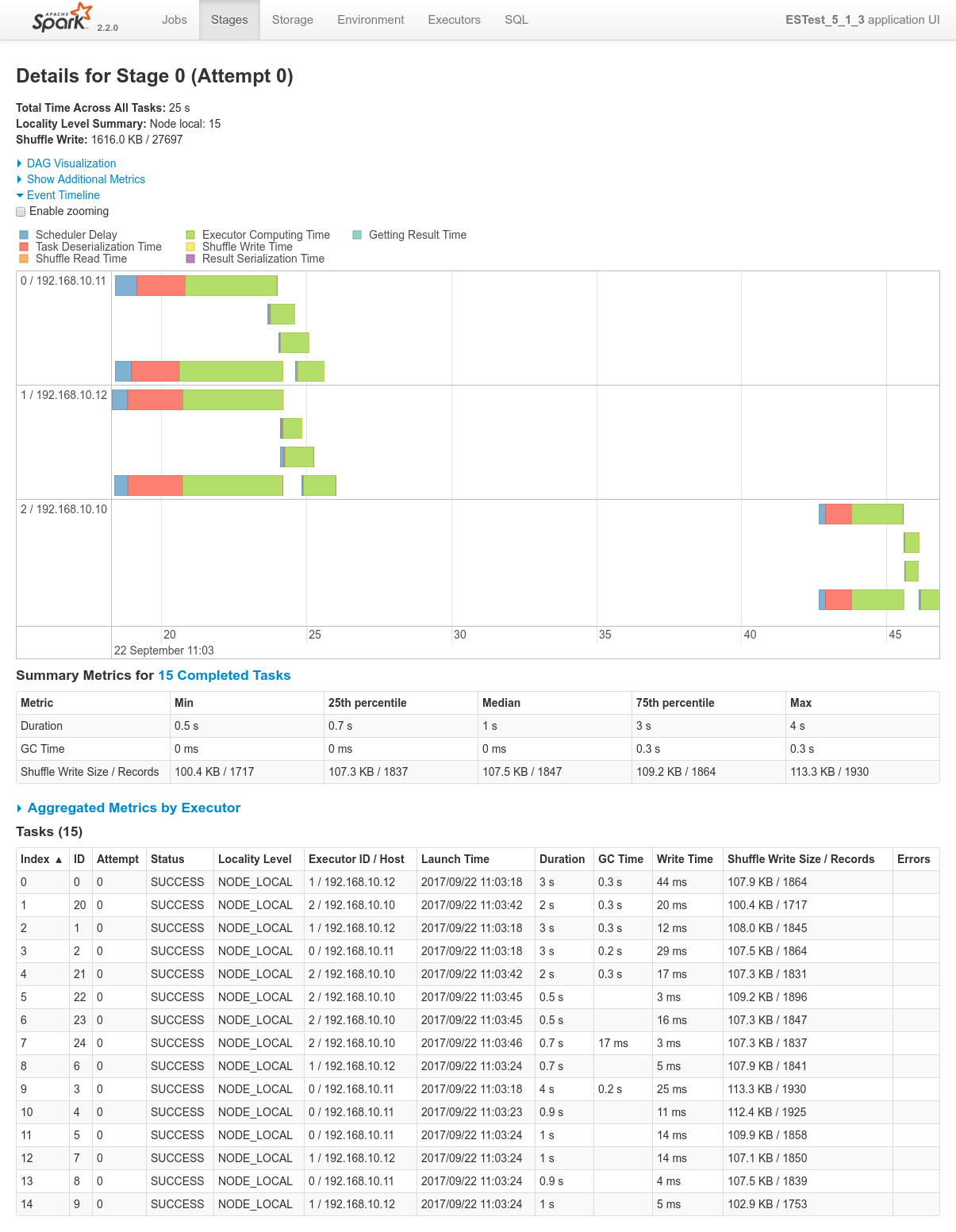
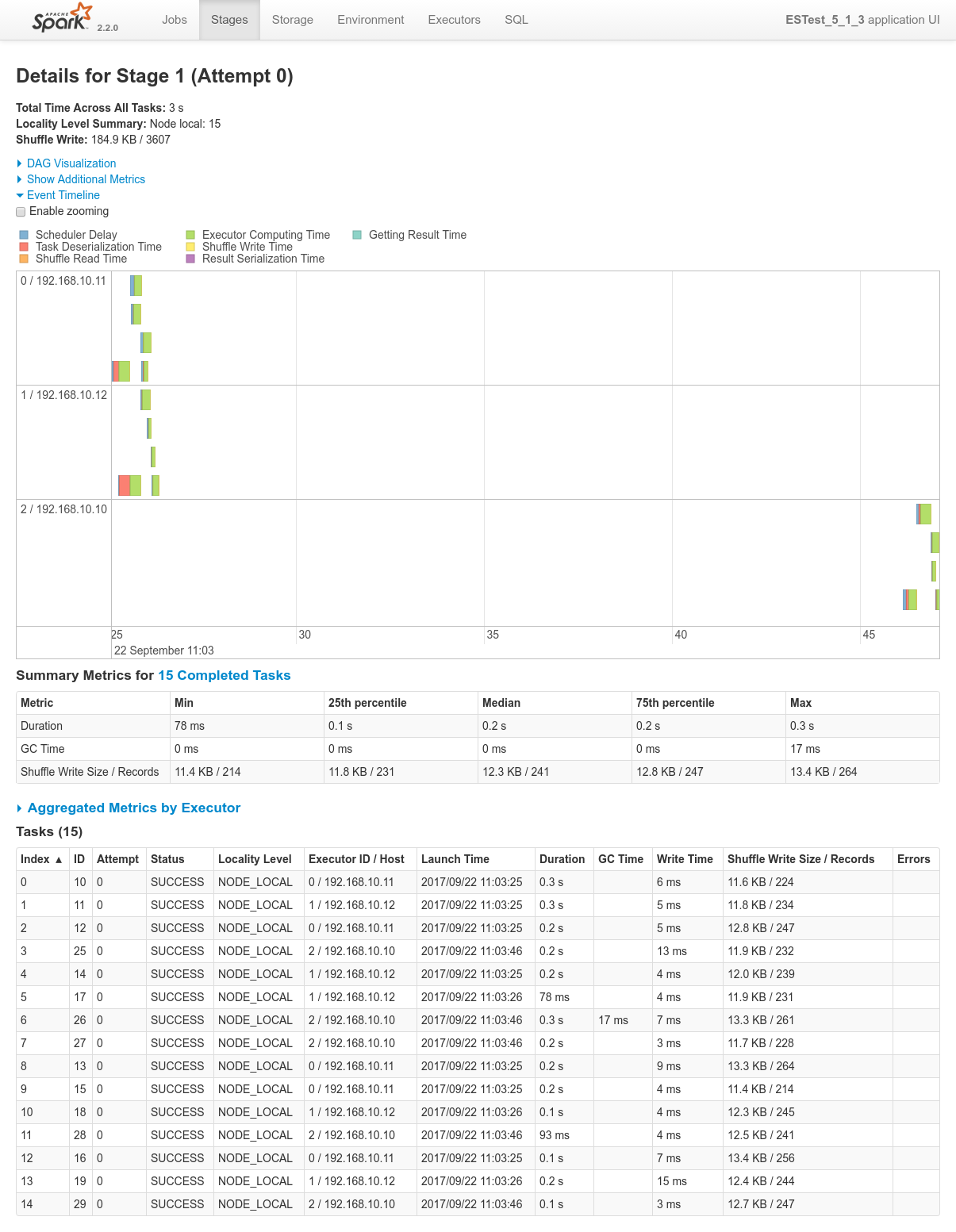
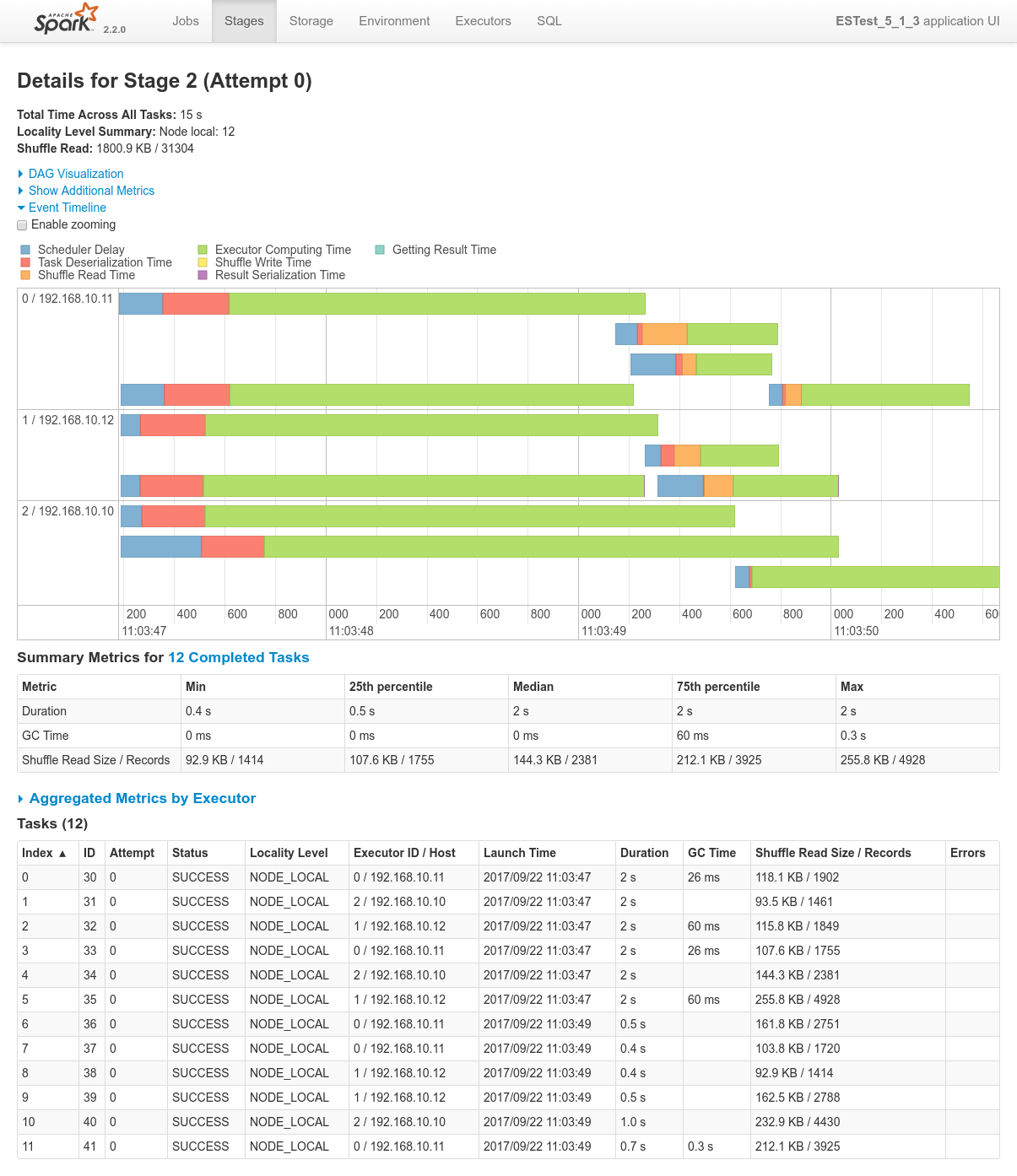
Focusing on Job 1 (P1), each and every relevant views from the Spark Application UI:
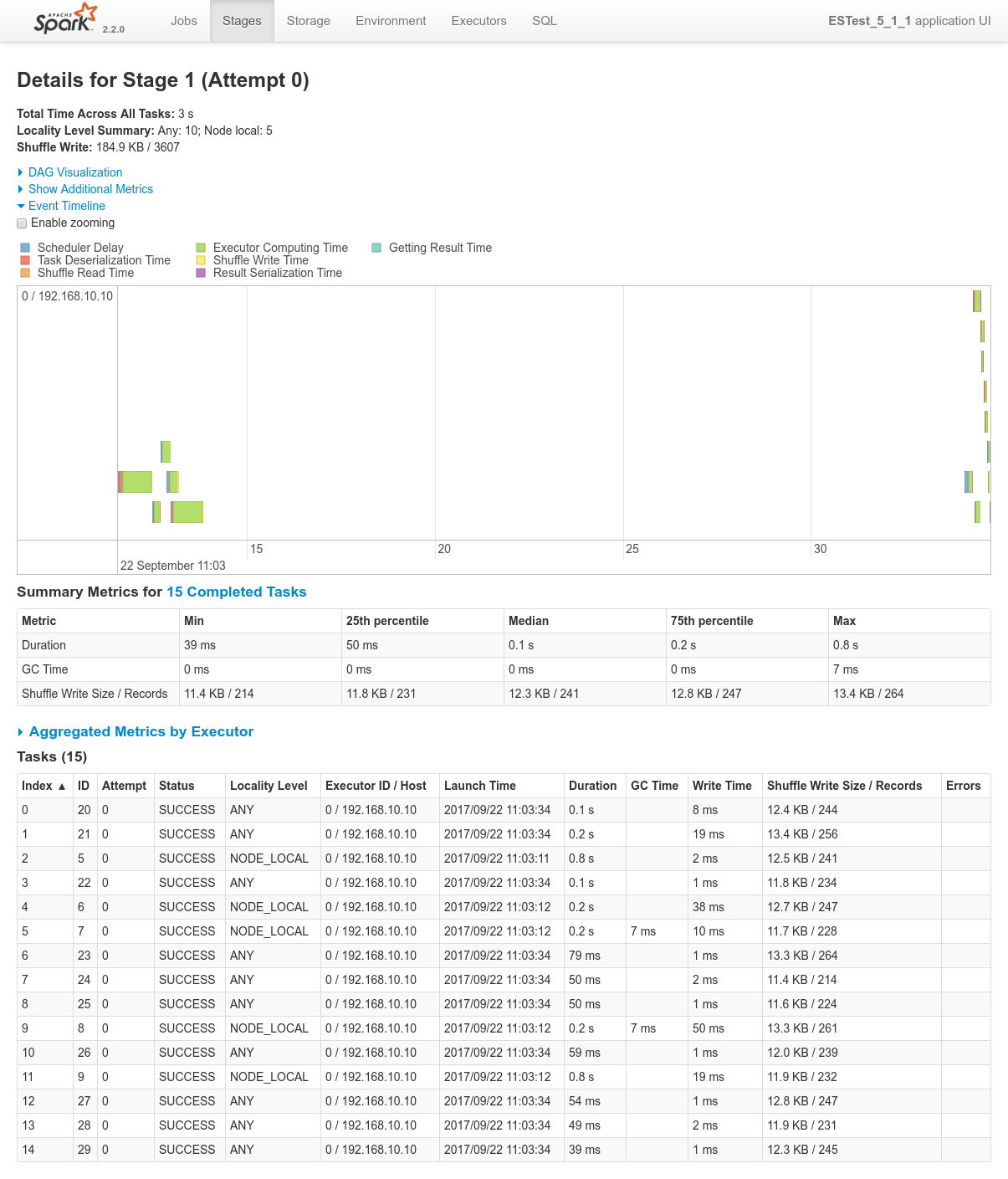
Focusing on Job 2 (P2), each and every relevant views from the Spark Application UI:
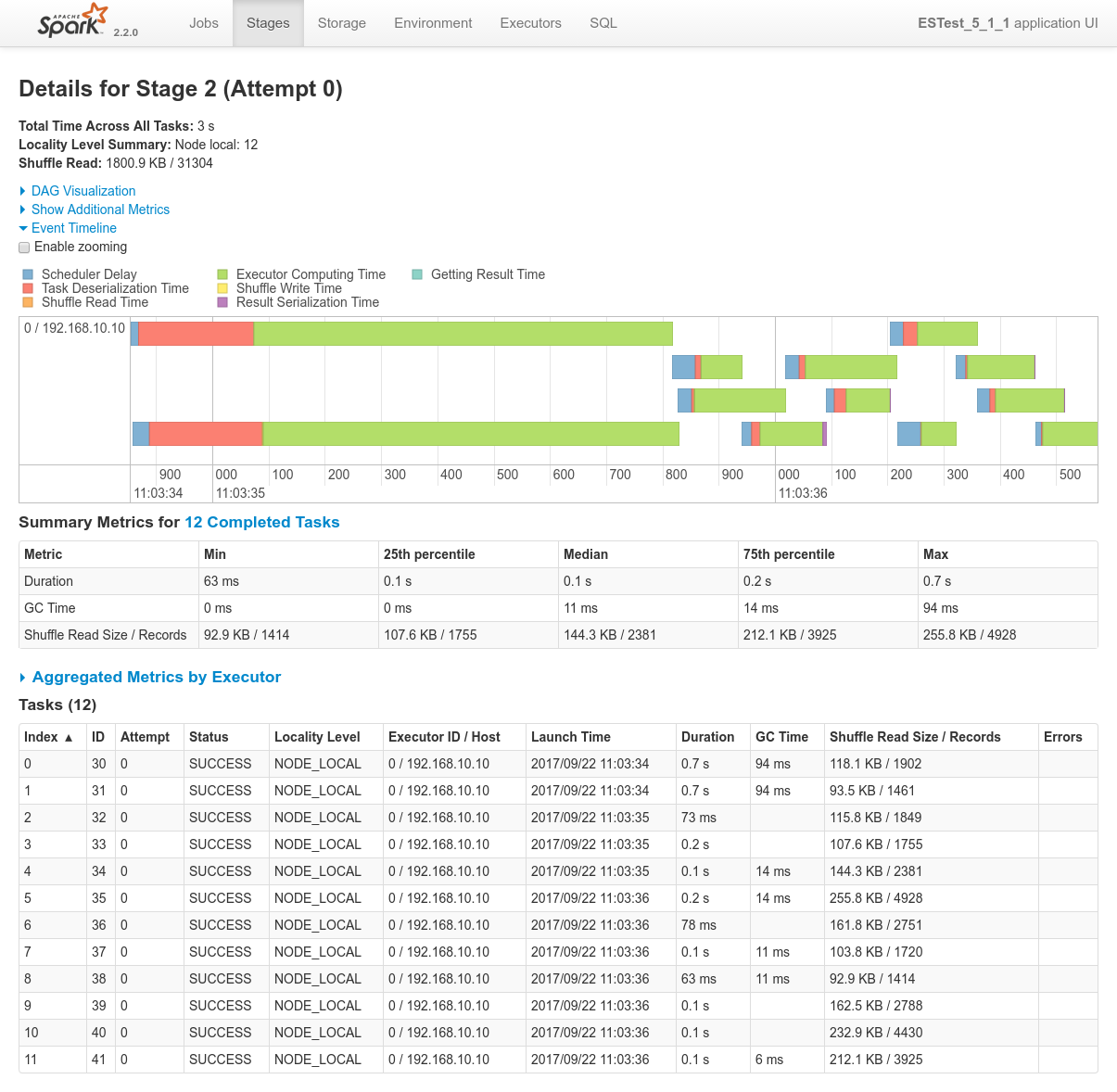
Focusing on Job 3 (P3), each and every relevant views from the Spark Application UI:
Focusing on Job 4 (P4), each and every relevant views from the Spark Application UI:
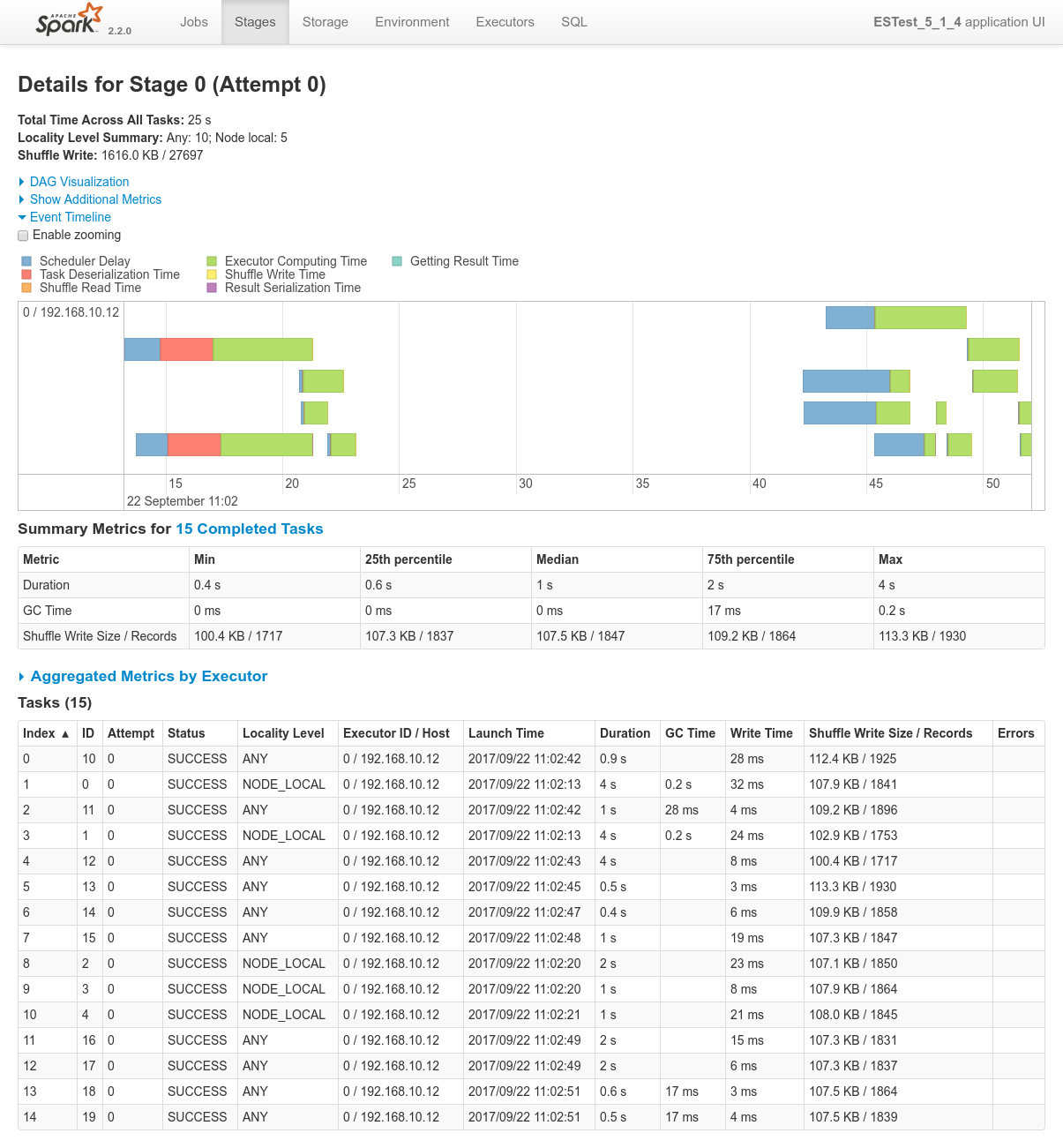
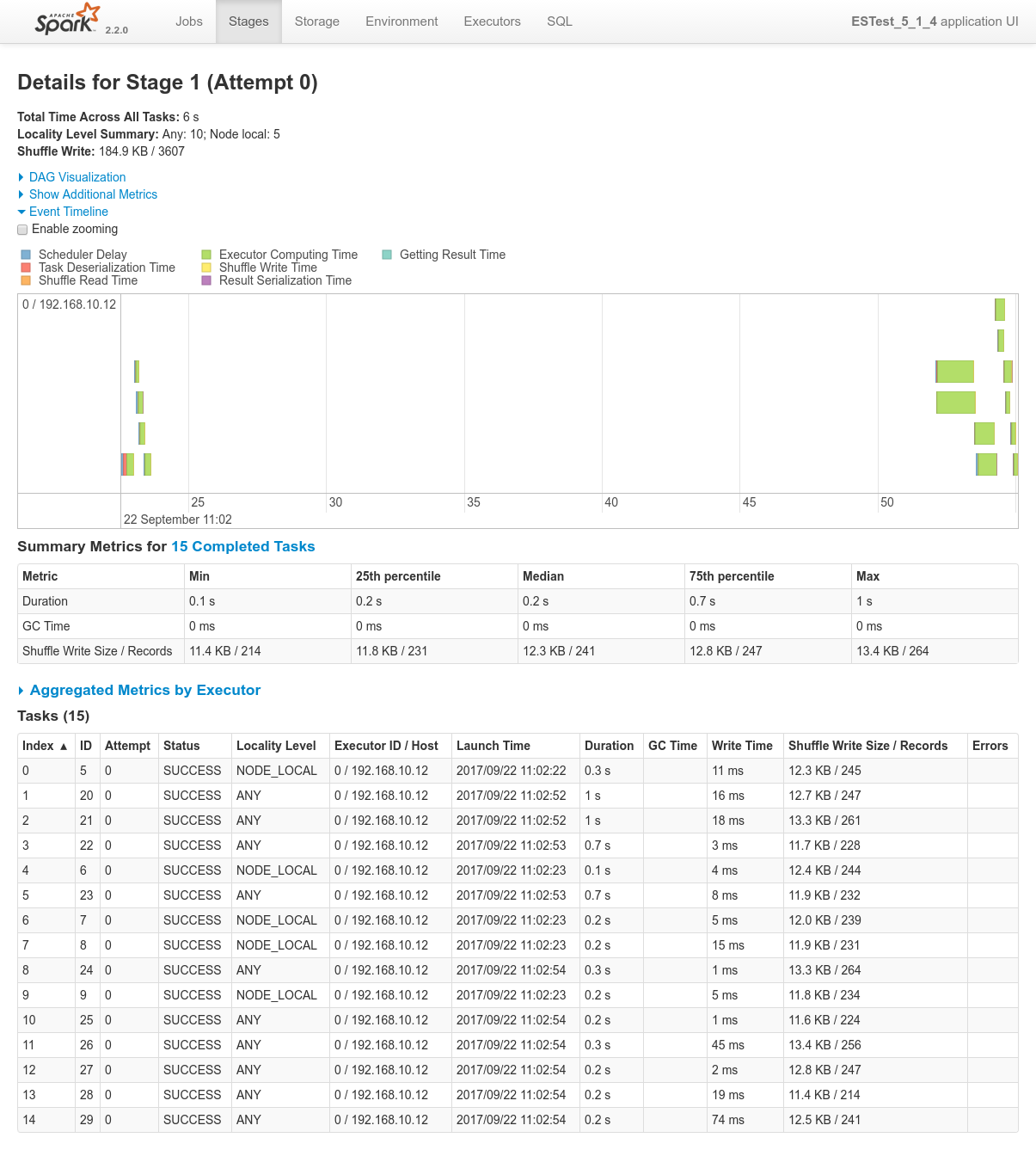
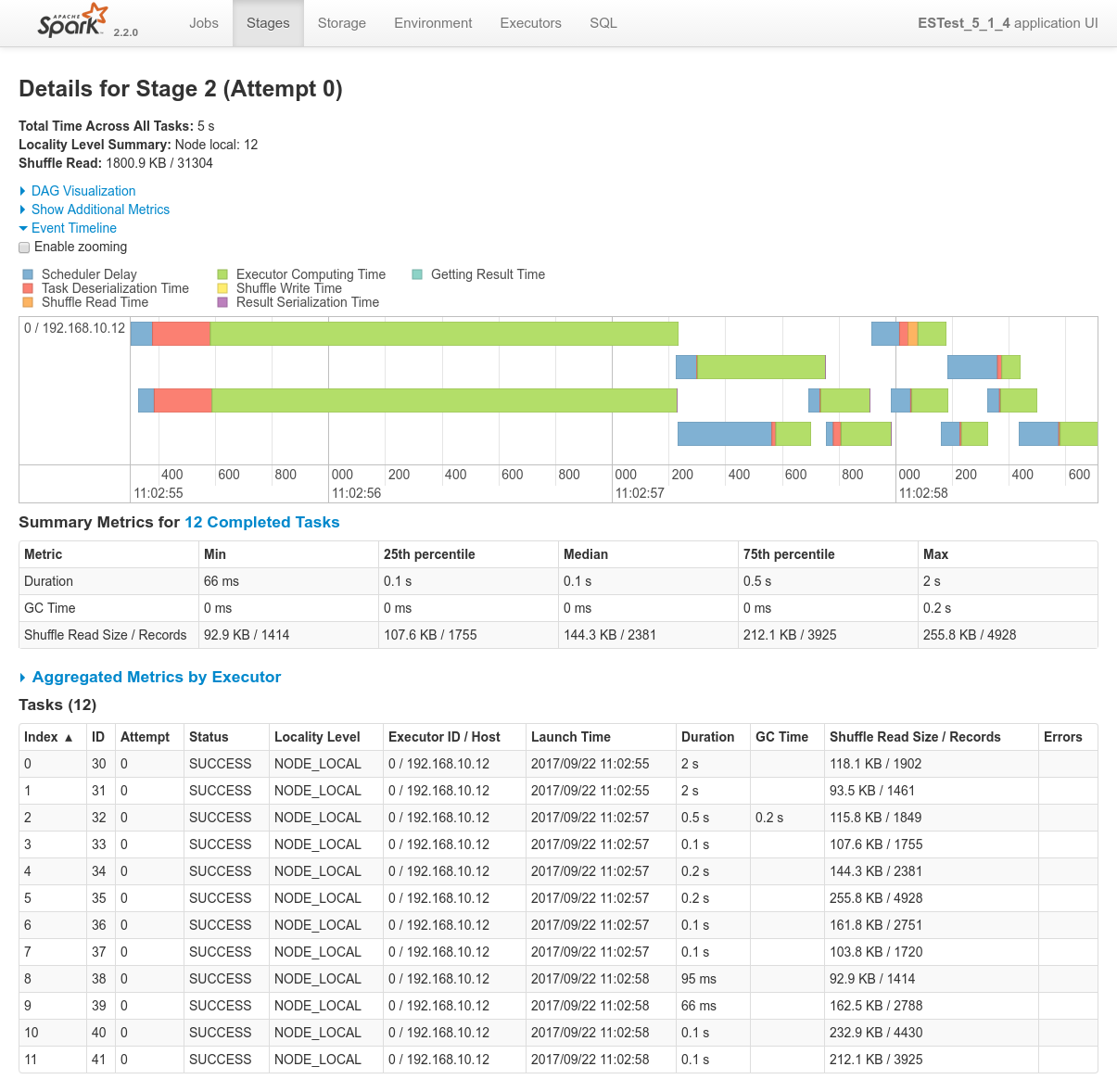
Conclusions
-
Before everything else let's mention that this test has been executed, first, using the FIFO scheduler (
spark.scheduler.mode=FIFO) and second, using the Dynamic allocation system - Dynamic allocation seems to work a little slower that static allocation in this case.
- With static allocation (only actual way on ES-Hadoop 5.x), what happens is that the first job that is prepared by the drivre a tiny little bit before the 3 others will get the shole cluster, and only whenever that first job is done, the three next sones will get an even share of the cluster, i.e one node each and complete almost at the same time.
- With dynamic allocation, the cluster is well shares among jobs. Once in a while a job may get an additional executor and another job will need to wait but all in all the 4 jobs really run together on the three nodes.
-
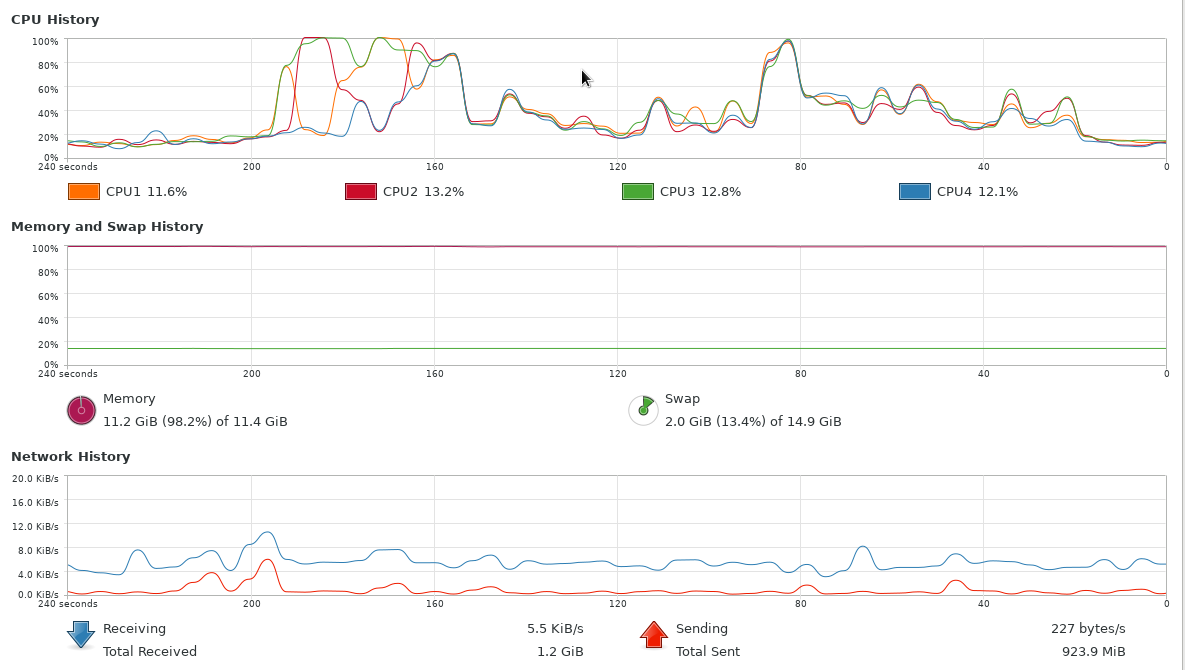
In terms of concurrency, we can see on the following image that the cluster is used quite effectively, looking at the CPU consumption on the host machine:
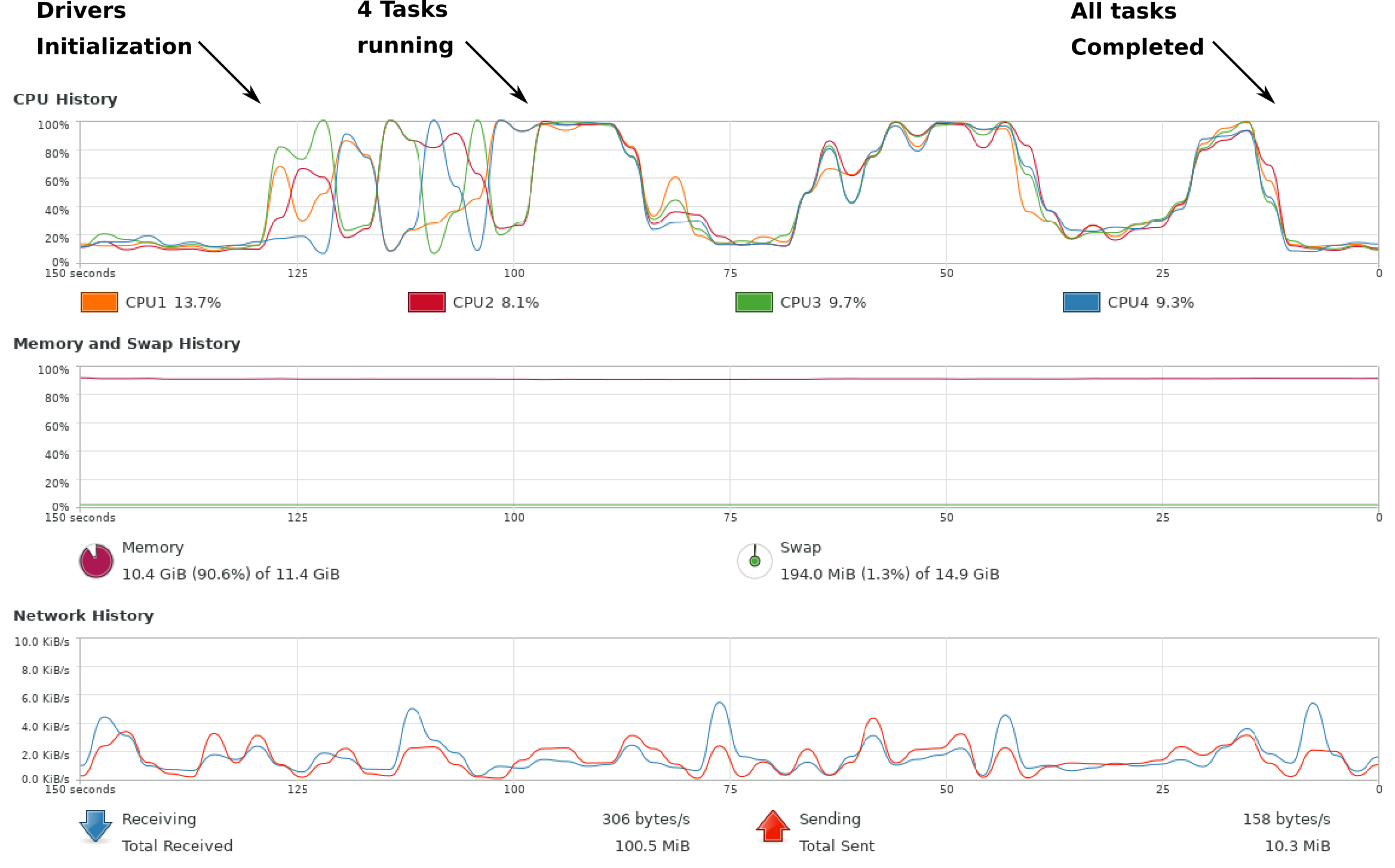 (Note : each and every of the 3 VMs can use up to 2 CPUS of the host which has 4 CPUs in total)
(Note : each and every of the 3 VMs can use up to 2 CPUS of the host which has 4 CPUs in total)
-
Also, all my tests, including this one has been executed using Coarse Grained Scheduling Mode (
spark.mesos.coarse=true).- One might think that using Fine Grained Mode, things would be more efficient since each and ever task would be distributed on the cluster at will and we wouldn't end up in the static topology described above.
-
But unfortunately, Mesos latency when it comes to negotiating resources really messes up performances. The dynamic dispatching of tasks works well, but the overall processes performances are screwed by the time Mesos requires for negotiation.
In the ends, Fine Grained Scheduling mode kills performance of the whole cluster down. -
I have executed this very same test using
spark.mesos.coarse=falseand the dropdown in terms of cluster usage efficiency is seen by looking at the CPU consumption on the host machine for test 5 - 1 using Fine Grained Mode
-
In regards to data locality, since the 3 last processes get one single node of the cluster each, only one third of the tasks will execute with locality level
NODE_LOCAL. Two thirds of them will require to fetch data from the network.
{kind=link}
6. References
Spark and mesos
ES Hadoop doc
- Spark : https://www.elastic.co/guide/en/elasticsearch/hadoop/current/spark.html
- Configuration : https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html#_querying
Pyspark.sql doc
- 2.2 : https://spark.apache.org/docs/2.2.0/api/python/pyspark.sql.html
- 1.6 : https://spark.apache.org/docs/1.6.2/api/python/pyspark.sql.html
Spark Doc
- Configuration : https://spark.apache.org/docs/latest/configuration.html
- Spark history server : https://spark.apache.org/docs/latest/monitoring.html
- Dynamic resource allocation : https://spark.apache.org/docs/latest/job-scheduling.html#dynamic-resource-allocation
Other Pyspark specificities
- Pyspark RDD API : https://spark.apache.org/docs/2.2.0/api/python/pyspark.html#pyspark.RDD
- Pyspark performance : https://fr.slideshare.net/SparkSummit/getting-the-best-performance-with-pyspark
Tags: big-data elasticsearch elk elk-ms kibana logstash mesos spark