
Entries tagged [spark]
Lambda Architecture with Kafka, ElasticSearch and Spark (Streaming)
by Jerome Kehrli
Posted on Friday May 04, 2018 at 12:32PM in Big Data
The Lambda Architecture, first proposed by Nathan Marz, attempts to provide a combination of technologies that together provide the characteristics of a web-scale system that satisfies requirements for availability, maintainability, fault-tolerance and low-latency.
Quoting Wikipedia: "Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods.
This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation.
The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce."
In my current company - NetGuardians - we detect banking fraud using several techniques, among which real-time scoring of transactions to compute a risk score.
The deployment of Lambda Architecture has been a key evolution to help us evolve towards real-time scoring on the large scale.
In this article, I intend to present how we do Lambda Architecture in my company using Apache Kafka, ElasticSearch and Apache Spark with its extension Spark-Streaming, and what it brings to us.
Read MoreTags: architecture big-data elasticsearch kafka lambda-architecture mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part III : so why is it cool ?
by Jerome Kehrli
Posted on Wednesday Aug 30, 2017 at 10:43PM in Big Data
So, finally the conclusion of this serie of three articles, the big conclusion, where I intend to present why this ELK-MS, ElasticSearch/LogStash/Kibana - Mesos/Spark, stack is cool.
Without any more waiting, let's give the big conclusion right away, using ElasticSearch, Mesos and Spark can really distribute and scale the processing the way we want and very easily scale the processing linearly with the amount of data to process.
And this, exactly this and nothing else, is very precisely what we want from a Big Data Processing cluster.
At the end of the day, we want a system that books a lot of the resources of the cluster for a job that should process a lot of data and only a small subset of these resources for a job that works on a small subset of data.
And this is precisely what one can achieve pretty easily with the ELK-MS stack, in an almost natural and straightforward way.
I will present why and how in this article.
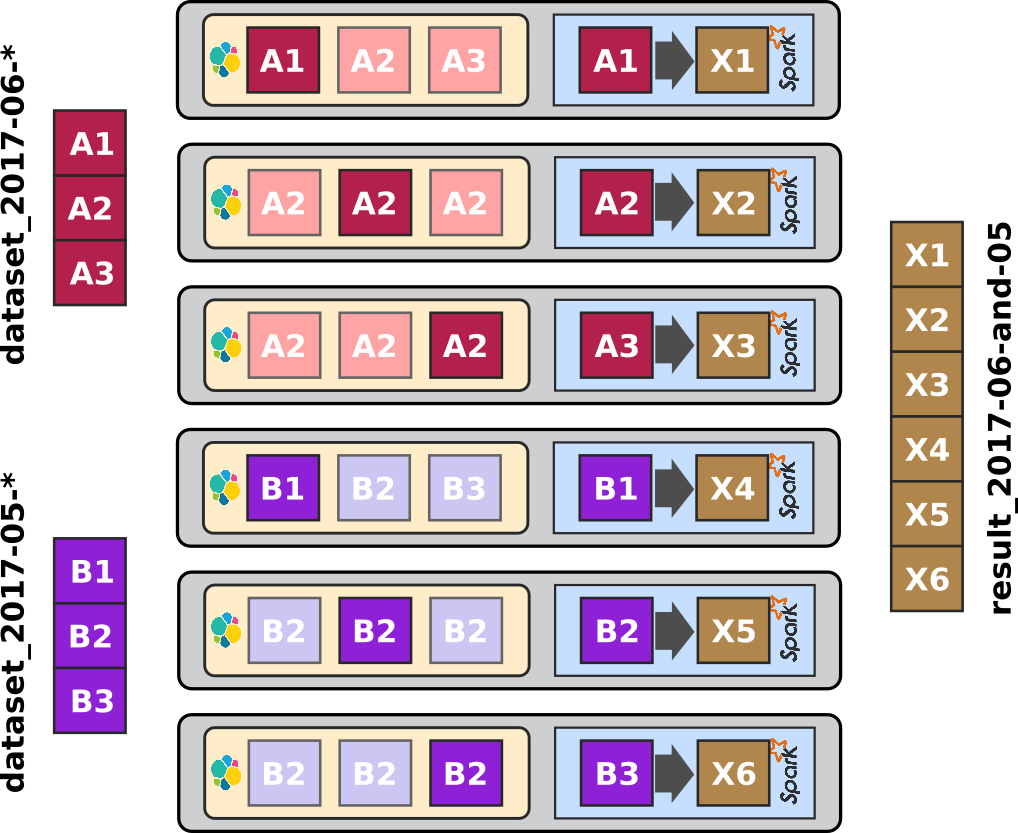
The first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
This third and last article - ELK-MS - part III : so why is it cool? presents, as indicated, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part II : assessing behaviour
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:30PM in Big Data
This article is the second article in my serie of two articles presenting the ELK-MS Stack and test cluster.
ELK-MS stands for ElasticSearch/LogStash/Kibana - Mesos/Spark. The ELK-MS stack is a simple, lightweight, efficient, low-latency and performing alternative to the Hadoop stack providing state of the art Data Analytics features.
ELK-MS is especially interesting for people that don't want to settle down for anything but the best regarding Big Data Analytics functionalities but yet don't want to deploy a full-blend Hadoop distribution, for instance from Cloudera or HortonWorks.
Again, I am not saying that Cloudera and HortonWorks' Hadoops distributions are not good. Au contraire, they are awesome and really simplifies the overwhelming burden of configuring and maintaining the set of software components they provide.
But there is definitely room for something lighter and simpler in terms of deployment and complexity.
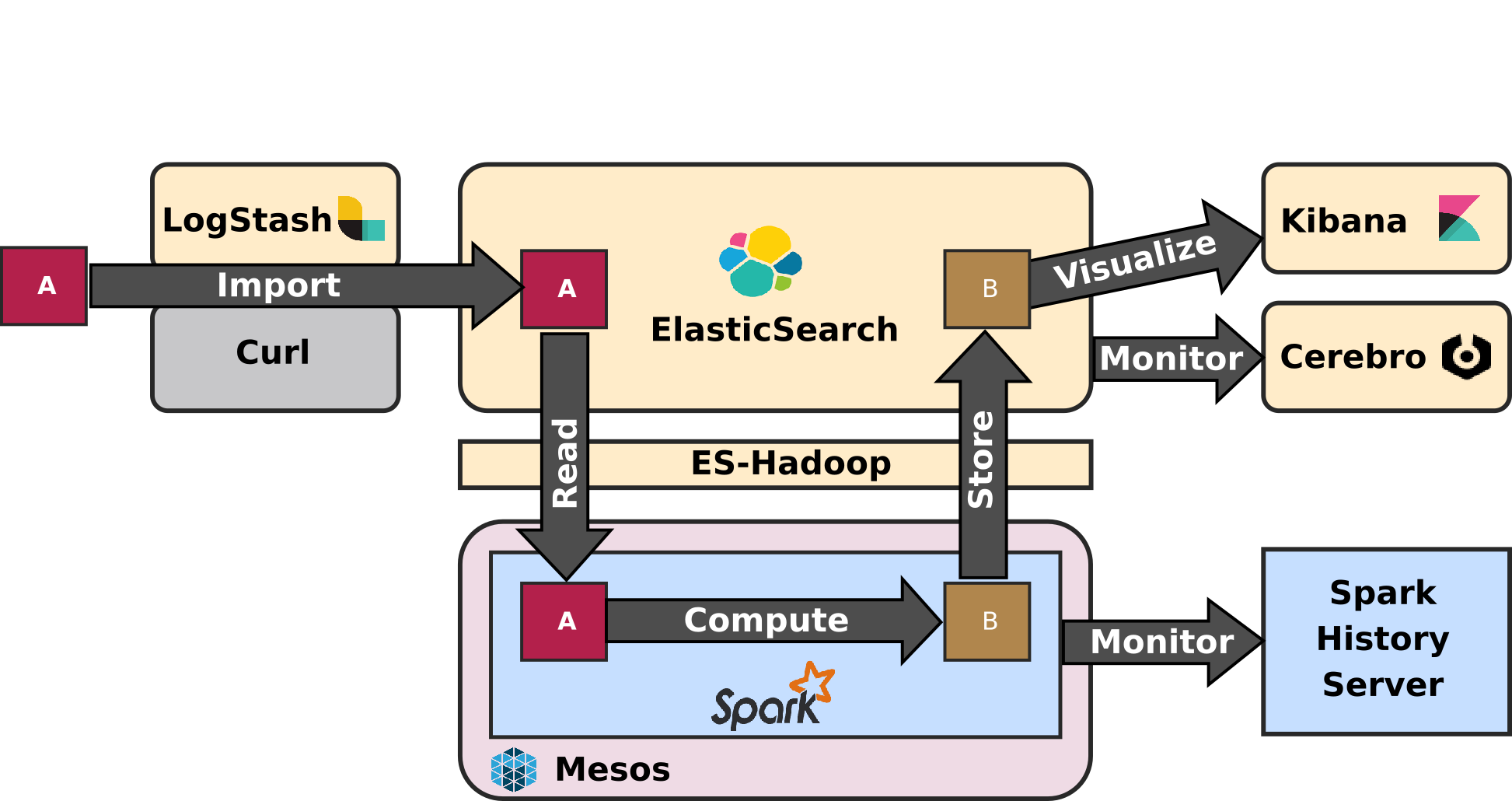
The first article - entitled - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
This second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses the challenges and constraints on this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part I : setup the cluster
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:29PM in Big Data
In my current company, we implement heavy Data Analytics algorithms and use cases for our customers. Historically, these heavy computations were taking a whole lot of different forms, mostly custom computation scripts in python or else using RDBMS databases to store data and results.
A few years ago, we started to hit the limits of what we were able to achieve using traditional architectures and had to move both our storage and processing layers to NoSQL / Big Data technologies.
We considered a whole lot of different approaches, but eventually, and contrary to what I expected first, we didn't settle for a standard Hadoop stack. We are using ElasticSearch as key storage backend and Apache Spark as processing backend.
Now of course we were initially still considering a Hadoop stack for the single purpose of using YARN as resource management layer for Spark ... until we discovered Apache Mesos.
Today this state of the art ELK-MS - for ElasticSearch/Logstash/Kibana - Mesos/Spark stack performs amazingly and I believe it to be a really lightweight, efficient, low latency and performing alternative to a plain old Hadoop Stack.
I am writing a serie of two articles to present this stack and why it's cool.
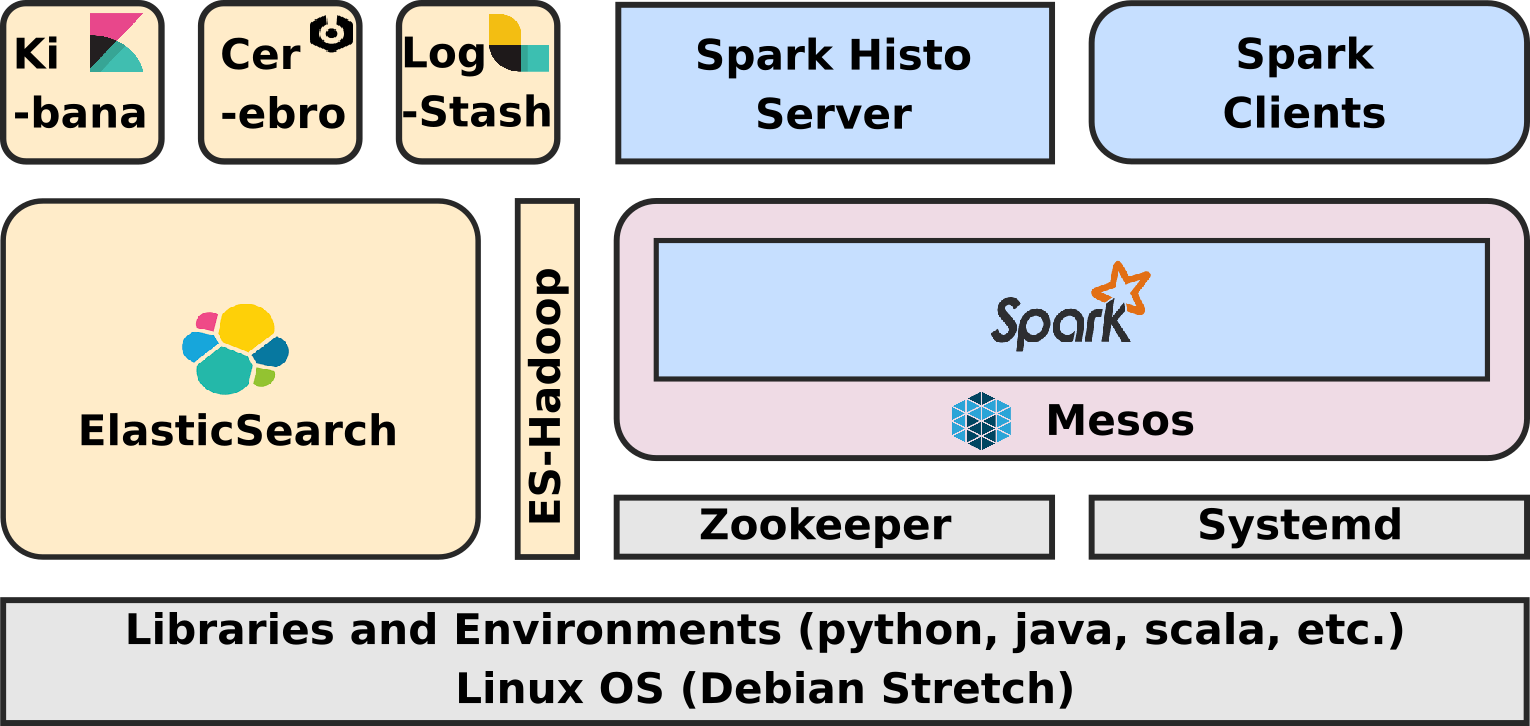
This first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Hadoop and Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark