
Entries tagged [big-data]
Modern Information System Architectures
by Jerome Kehrli
Posted on Monday Dec 13, 2021 at 12:04PM in Big Data
For forty years we have been building Information Systems in corporations in the same way, with the same architecture, with very little innovations and changes in paradigms:
- On one side the Operational Information System which sustains day-to-day operations and business activities. On the Operational Information Systems, the 3-tiers architecture and the relational database model (RDBMS - Relational Database Management System / SQL) have ruled for nearly 40 years.
- On the other side the Decision Support Information System - or Business Intelligence or Analytical Information System - where the Data Warehouse architecture pattern has ruled for 30 years.
Of course the technologies involved in building these systems have evolved in all these decades, in the 80s COBOL on IBM hosts used to rule the Information Systems world whereas Java emerged quickly as a standard in the 2000s, etc.
But while the technologies used in building these information systems evolved fast, their architecture in the other hand, the way we design and build them, didn't change at all. The relational model ruled for 40 years along the 3-tiers model in the Operational world and in the analytical world, the Data Warehouse pattern was the only way to go for decades.
The relational model is interesting and has been helpful for many decades. its fundamental objective is to optimize storage space by ensuring an entity is stored only once (3rd normal form / normalization). It comes from a time when storage was very expensive.
But then, by imposing normalization and ACID transactions, it prevents horizontal scalability by design. An Oracle database for instance is designed to run on a single machine, it simply can't implement relational references and ACID transactions on a cluster of nodes.
Today storage is everything but expensive but Information Systems still have to deal with RDBMS limitations mostly because ... that's the only way we used to know.
On the Decision Support Information System (BI / Analytical System), the situation is even worst. in Data warehouses, data is pushed along the way and transformed, one step at a time, first in a staging database, then in the Data Warehouse Database and finally in Data Marts, highly specialized towards specific use cases.
For a long time we didn't have much of a choice since implementing such analytics in a pull way (data lake pattern) was impossible, we simply didn't have the proper technology. The only way to support high volumes of data was to push daily increments through these complex transformation steps every night, when the workload on the system is lower.
The problem with this push approach is that it's utmost inflexible. One can't change his mind along the way and quickly come up with a new type of data. Working with daily increments would require waiting 6 months to have a 6 months history. Not to mention that the whole process is amazingly costly to develop, maintain and operate.
So for a long time, RDBMSes and Data Warehouses were all we had.
It took the Internet revolution and the web giants facing limits of these traditional architectures for finally something different to be considered. The Big Data revolution has been the cornerstone of all the evolutions in Information System architecture we have been witnessing over the last 15 years.
The latest evolution in this software architecture evolution (or revolution) would be micro-services, where finally all the benefits that were originally really fit to the analytical information system evolution finally end up overflowing to the operational information system.
Where Big Data was originally a lot about scaling the computing along with the data topology - bringing the code to where the data is (data tier revolution) - we're today scaling everything, from individual components requiring heavy processing to message queues, etc.
In this article, I would want to present and discuss how Information System architectures evolved from the universal 3 tiers (operational) / Data Warehouse (analytical) approach to the Micro-services architecture, covering Hadoop, NoSQL, Data Lakes, Lambda architecture, etc. and introducing all the fundamental concepts along the way.
Read MoreTags: architecture big-data hadoop kubernetes microservices newsql nosql
Powerful Big Data analytics platform fights financial crime in real time
by Jerome Kehrli
Posted on Friday Sep 03, 2021 at 11:17AM in Big Data
(Article initially published on NetGuardians' blog)
NetGuardians overcomes the problems of analyzing billions of pieces of data in real time with a unique combination of technologies to offer unbeatable fraud detection and efficient transaction monitoring without undermining the customer experience or the operational efficiency and security in an enterprise-ready solution.
When it comes to data analytics, the more data the better, right? Not so fast. That’s only true if you can crunch that data in a timely and cost-effective way.
This is the problem facing banks looking to Big Data technology to help them spot and stop fraudulent and/or non-compliant transactions. With a window of no more than a hundredth of a millisecond to assess a transaction and assign a risk score, banks need accurate and robust real-time analytics delivered at an affordable price. Furthermore, they need a scalable system that can score not one but many thousands of transactions within a few seconds and grow with the bank as the industry moves to real-time processing.
AML transaction monitoring might be simple on paper but making it effective and ensuring it doesn’t become a drag on operations has been a big ask. Using artificial intelligence to post-process and analyze alerts as they are thrown up is a game-changing paradigm, delivering a significant reduction in the operational cost of analyzing those alerts. But accurate fraud risk scoring is a much harder game. Some fraud mitigation solutions based on rules engines focus on what the fraudsters do, which entails an endless game of cat and mouse, staying up to date with their latest scams. By definition, this leaves the bank at least one step behind.
At NetGuardians, rather than try to keep up with the fraudsters, we focus on what we know and what changes very little – customers’ behavior and that of bank staff. By learning “normal” behavior, such as typical time of transaction, size, beneficiary, location, device, trades, etc., for each customer and internal user, and comparing each new transaction or activity against those of the past, we can give every transaction a risk score.
Read MoreTags: architecture bank banking banking-fraud big-data netguardians
Lambda Architecture with Kafka, ElasticSearch and Spark (Streaming)
by Jerome Kehrli
Posted on Friday May 04, 2018 at 12:32PM in Big Data
The Lambda Architecture, first proposed by Nathan Marz, attempts to provide a combination of technologies that together provide the characteristics of a web-scale system that satisfies requirements for availability, maintainability, fault-tolerance and low-latency.
Quoting Wikipedia: "Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods.
This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation.
The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce."
In my current company - NetGuardians - we detect banking fraud using several techniques, among which real-time scoring of transactions to compute a risk score.
The deployment of Lambda Architecture has been a key evolution to help us evolve towards real-time scoring on the large scale.
In this article, I intend to present how we do Lambda Architecture in my company using Apache Kafka, ElasticSearch and Apache Spark with its extension Spark-Streaming, and what it brings to us.
Read MoreTags: architecture big-data elasticsearch kafka lambda-architecture mesos spark
Artificial Intelligence for Banking Fraud Prevention
by Jerome Kehrli
Posted on Monday Apr 30, 2018 at 02:57PM in Banking
In this article, I intend to present my company's - NetGuardians - approach when it comes to deploying Artificial Intelligence techniques towards better fraud detection and prevention.
This article is inspired from various presentations I gave on the topic in various occasions that synthesize our experience in regards to how these technologies were initially triggering a lot of skepticism and condescension and how it turns our that they are now really mandatory to efficiently prevent fraud in financial institutions, due to the rise of fraud costs, the maturity of cybercriminals and the complexity of attacks.
Here financial fraud is considered at the broad scale, both internal fraud, when employees divert funds from their employer and external fraud in all its forms, from sophisticated network penetration schemes to credit card theft.
I don't have the pretension to present an absolute or global overview. Instead, I would want to present things from the perspective of NetGuardians, from our own experience in regards to the problems encountered by our customers and the how Artificial Intelligence helped us solve these problems.
Tags: ai artificial-intelligence bank banking big-data finance fraud-prevention netguardians
Presenting NetGuardians' Big Data technology (video)
by Jerome Kehrli
Posted on Friday Jan 05, 2018 at 07:00PM in Big Data
I am presenting in this video NetGuardians' Big Data approach, technologies and its advantages for the banking institutions willing to deploy big data technologies for Fraud Prevention.
The speech is reported in textual form hereafter.
Read MoreTags: bank banking big-data netguardians video
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part III : so why is it cool ?
by Jerome Kehrli
Posted on Wednesday Aug 30, 2017 at 10:43PM in Big Data
So, finally the conclusion of this serie of three articles, the big conclusion, where I intend to present why this ELK-MS, ElasticSearch/LogStash/Kibana - Mesos/Spark, stack is cool.
Without any more waiting, let's give the big conclusion right away, using ElasticSearch, Mesos and Spark can really distribute and scale the processing the way we want and very easily scale the processing linearly with the amount of data to process.
And this, exactly this and nothing else, is very precisely what we want from a Big Data Processing cluster.
At the end of the day, we want a system that books a lot of the resources of the cluster for a job that should process a lot of data and only a small subset of these resources for a job that works on a small subset of data.
And this is precisely what one can achieve pretty easily with the ELK-MS stack, in an almost natural and straightforward way.
I will present why and how in this article.
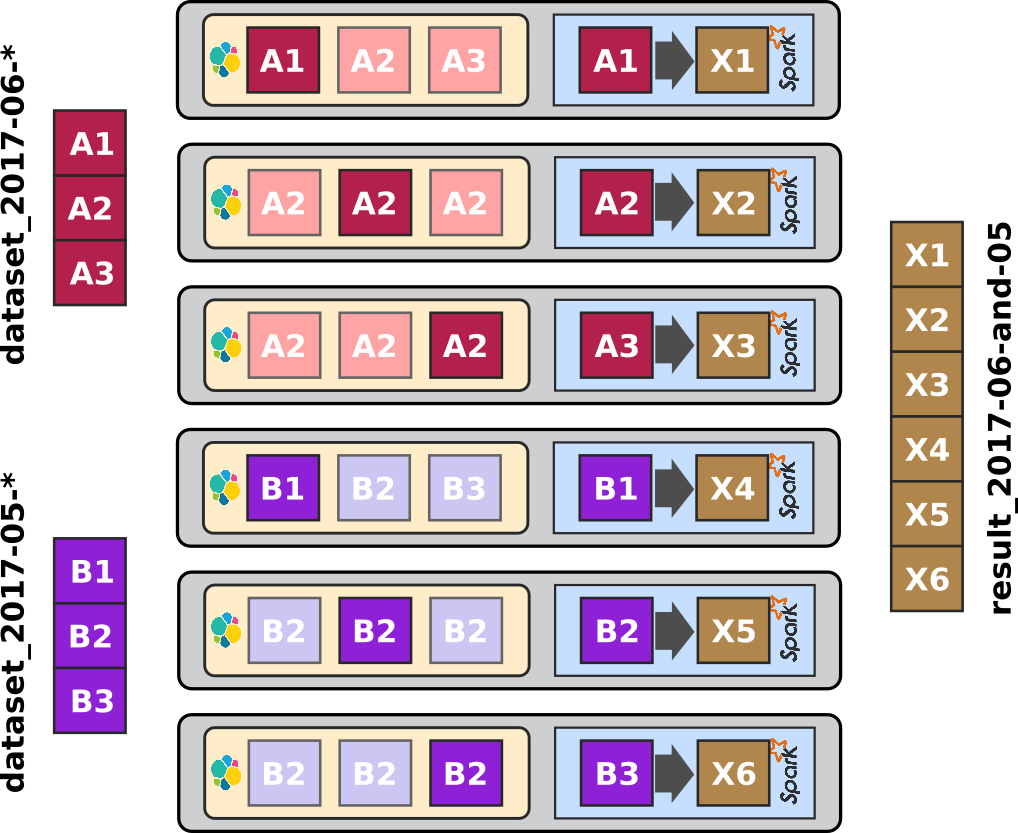
The first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
This third and last article - ELK-MS - part III : so why is it cool? presents, as indicated, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part II : assessing behaviour
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:30PM in Big Data
This article is the second article in my serie of two articles presenting the ELK-MS Stack and test cluster.
ELK-MS stands for ElasticSearch/LogStash/Kibana - Mesos/Spark. The ELK-MS stack is a simple, lightweight, efficient, low-latency and performing alternative to the Hadoop stack providing state of the art Data Analytics features.
ELK-MS is especially interesting for people that don't want to settle down for anything but the best regarding Big Data Analytics functionalities but yet don't want to deploy a full-blend Hadoop distribution, for instance from Cloudera or HortonWorks.
Again, I am not saying that Cloudera and HortonWorks' Hadoops distributions are not good. Au contraire, they are awesome and really simplifies the overwhelming burden of configuring and maintaining the set of software components they provide.
But there is definitely room for something lighter and simpler in terms of deployment and complexity.
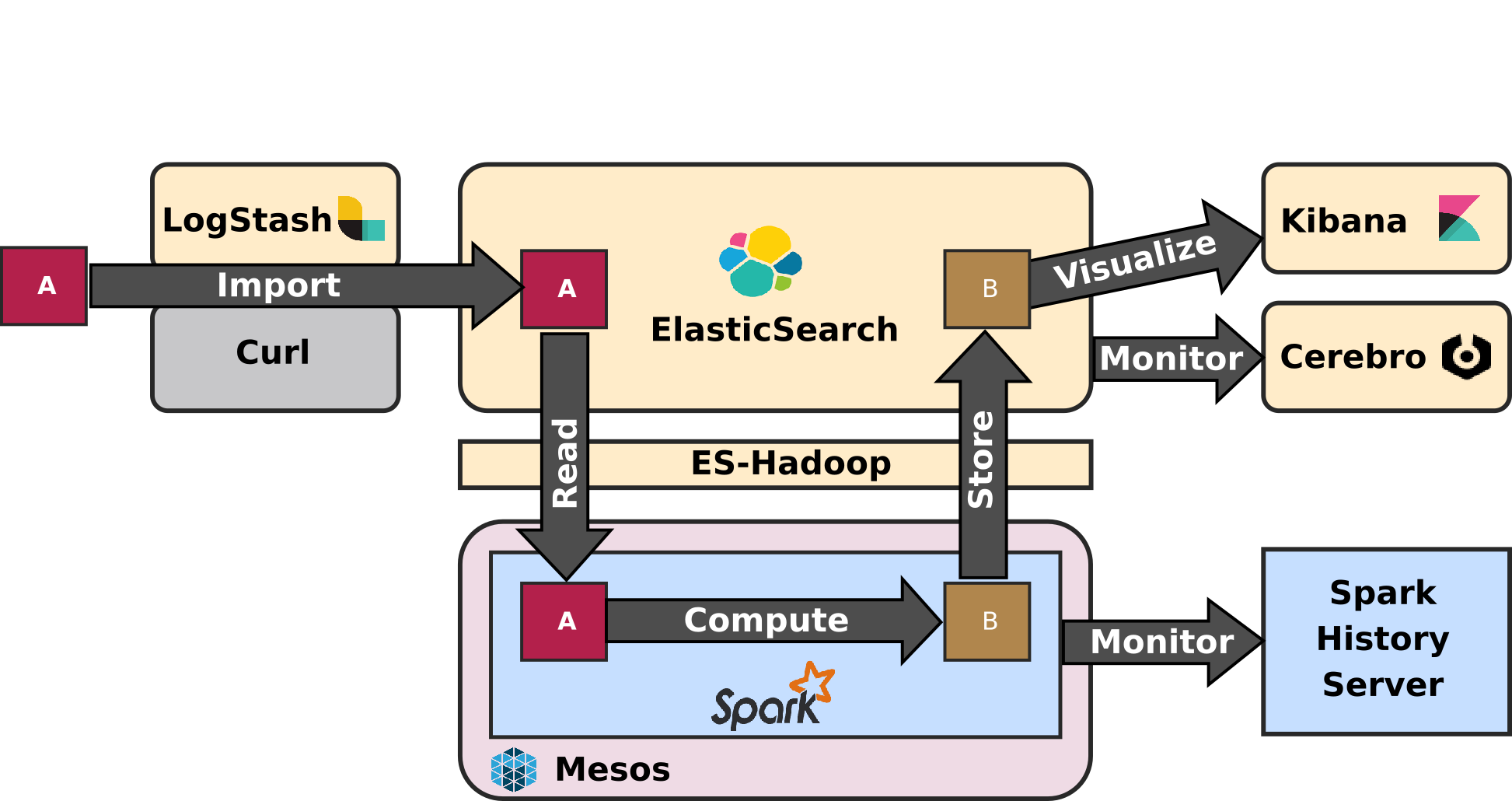
The first article - entitled - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
This second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses the challenges and constraints on this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part I : setup the cluster
by Jerome Kehrli
Posted on Wednesday Aug 23, 2017 at 11:29PM in Big Data
In my current company, we implement heavy Data Analytics algorithms and use cases for our customers. Historically, these heavy computations were taking a whole lot of different forms, mostly custom computation scripts in python or else using RDBMS databases to store data and results.
A few years ago, we started to hit the limits of what we were able to achieve using traditional architectures and had to move both our storage and processing layers to NoSQL / Big Data technologies.
We considered a whole lot of different approaches, but eventually, and contrary to what I expected first, we didn't settle for a standard Hadoop stack. We are using ElasticSearch as key storage backend and Apache Spark as processing backend.
Now of course we were initially still considering a Hadoop stack for the single purpose of using YARN as resource management layer for Spark ... until we discovered Apache Mesos.
Today this state of the art ELK-MS - for ElasticSearch/Logstash/Kibana - Mesos/Spark stack performs amazingly and I believe it to be a really lightweight, efficient, low latency and performing alternative to a plain old Hadoop Stack.
I am writing a serie of two articles to present this stack and why it's cool.
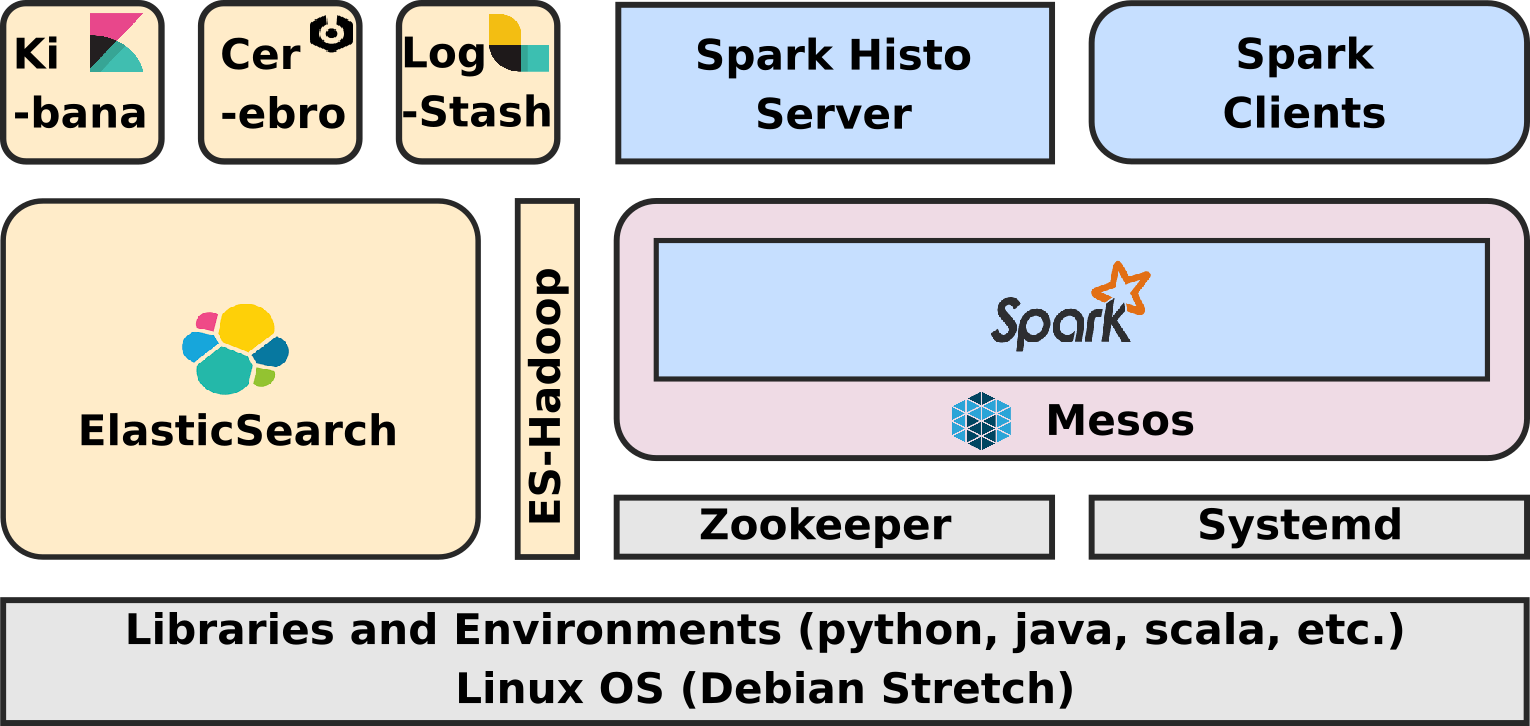
This first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
The conclusions of this serie of articles are presented in the third and last article - ELK-MS - part III : so why is it cool? which presents, as the name suggests, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Hadoop and Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark
Big Data and private banking, what for ?
by Jerome Kehrli
Posted on Wednesday Oct 05, 2016 at 10:50AM in Big Data
Big Data technologies are increasingly used in retail banking institutions for customer profiling or other marketing activities. In private banking institutions, however, applications are less obvious and there are only very few initiatives.
Yet, as a matter of fact, there are opportunities in such institutions and they can be quite surprising.
Big Data technologies, initiated by the Web Giants such as Google or Amazon, enable to analyze very massive amount of data (ranging from Terabytes to Petabytes). Apache Hadoop is the de-facto standard nowadays when it comes to considering Open Source Big Data technologies but it is increasingly challenged by alternatives such as Apache Spark or others providing less constraining programming paradigms than Map-Reduce.
These Big Data Processing Platform benefits from the NoSQL genes : the CAP Theorem when it comes to storing data, the usage of commodity hardware, the capacity to scale-out (almost) linearly (instead of scaling up your Oracle DB) and a much lower TCO (Total Cost of Ownership) than standard architectures.
Most essential applications for such technologies in retail banking institutions consist in gathering knowledge and insights on the customer base, customer's profiles and their tendencies by using cutting-edge Machine Learning techniques on such data.
In contrary to retail banking institutions that are exploiting such technologies for many years, private banking institution, with their very low amount of transactions and their limited customer base are considering these technologies with a lot of skepticism and condescension.
However, in contrary to preconceived ideas, use case exist and present surprising opportunities, mostly around three topics :
- Enhance proximity with customers
- Improve investment advisory services
- Reduce computation costs
Tags: banking big-data finance private-bank