
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part III : so why is it cool ?
by Jerome Kehrli
Posted on Wednesday Aug 30, 2017 at 10:43PM in Big Data
So, finally the conclusion of this serie of three articles, the big conclusion, where I intend to present why this ELK-MS, ElasticSearch/LogStash/Kibana - Mesos/Spark, stack is cool.
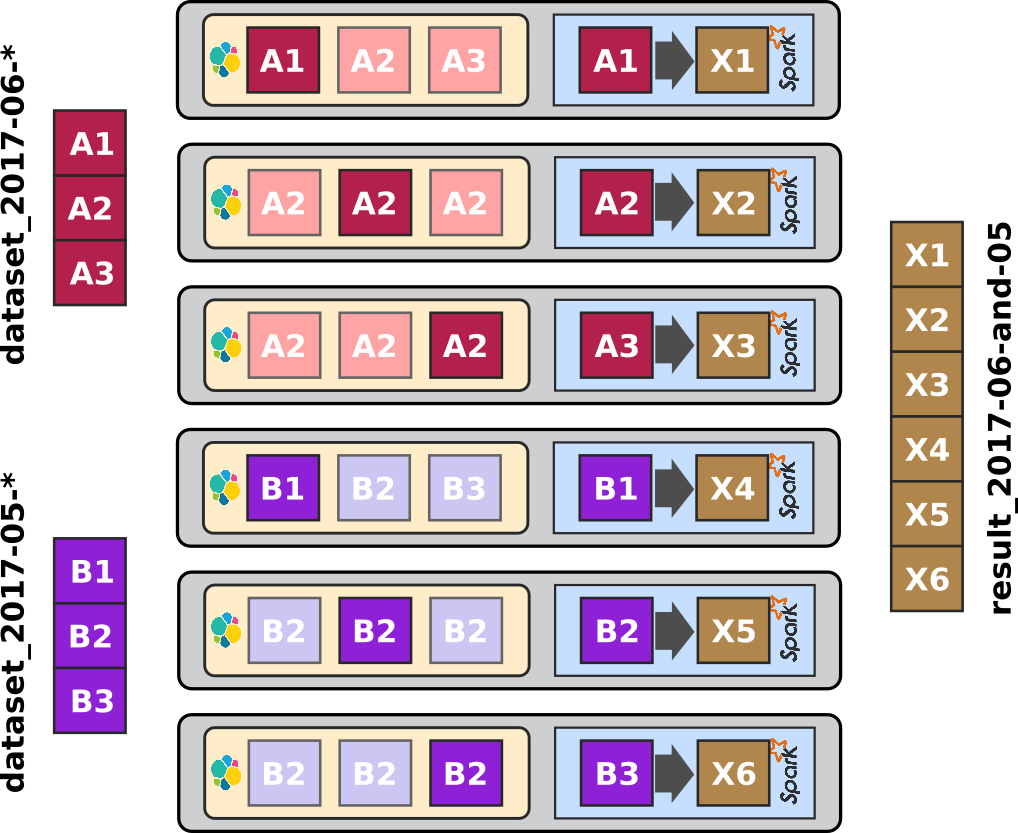
Without any more waiting, let's give the big conclusion right away, using ElasticSearch, Mesos and Spark can really distribute and scale the processing the way we want and very easily scale the processing linearly with the amount of data to process.
And this, exactly this and nothing else, is very precisely what we want from a Big Data Processing cluster.
At the end of the day, we want a system that books a lot of the resources of the cluster for a job that should process a lot of data and only a small subset of these resources for a job that works on a small subset of data.
And this is precisely what one can achieve pretty easily with the ELK-MS stack, in an almost natural and straightforward way.
I will present why and how in this article.
The first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
This third and last article - ELK-MS - part III : so why is it cool? presents, as indicated, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Read MoreTags: big-data elasticsearch elk elk-ms kibana logstash mesos spark

