
100 hard software engineering interview questions
by Jerome Kehrli
Posted on Friday Dec 06, 2013 at 04:11PM in Computer Science
For some reasons that I'd rather keep private, I got interested in the kind of questions google, microsoft, amazon and other tech companies are asking to candidate during the recruitment process. Most of these questions are oriented towards algorithmics or mathematics. Some other are logic questions or puzzles the candidate is expected to be able to solve in a dozen of minutes in front of the interviewer.
If found various sites online providing lists of typical interview questions. Other sites are discussing topics like "the ten toughest questions asked by google" or by microsoft, etc.
Then I wondered how many of them I could answer on my own without help. The truth is that while I can answer most of these questions by myself, I still needed help for almost as much as half of them.
Anyway, I have collected my answers to a hundred of these questions below.
For the questions for which I needed some help to build an answer, I clearly indicate the source where I found it.
Very likely an inifinite loop: only crashes when the call stack overflows, and that could happen anywhere, depending on how much memory is available for the call stack.
Your code could be invoking anything with undefined behaviour in the C standard, including (but not limited to):
- Not initialising a variable but attempting to use its value.
- Dereferencing a null pointer.
- Reading or writing past the end of an array.
- Defining a preprocessor macro that starts with an underscore and either a capital letter or another underscore.
- disk full, i.e. other processes may delete a different file causing more space to be available
- code depends on timer
- memory issue, i.e. other processes allocate and/or free memory
- a pointer points to a random location in memory that is changed by another process causing some values be "valid" (very rare though) = = Dangling pointer
A dangling pointer is a pointer to storage that is no longer allocated. Dangling pointers are nasty bugs because they seldom crash the program until long after they have been created, which makes them hard to find. Programs that create dangling pointers often appear to work on small inputs, but are likely to fail on large or complex inputs.
Ways to test include debugger, static code analysis tools, dynamic code analysis tools, manual source code review, etc.
Reservoir sampling is a family of randomized algorithms for randomly choosing k samples from a list S containing n items, where n is either a very large or unknown number. Typically n is large enough that the list doesn't fit into main memory.
This simple O(n) algorithm as described in the Dictionary of Algorithms and Data Structures consists of the following steps (assuming that the arrays are one-based, and that the number of items to select, k, is smaller than the size of the source array, S):
array R[k]; // result
integer i, j;
// fill the reservoir array
for each i in 1 to k do
R[i] := S[i]
done;
// replace elements with gradually decreasing probability
for each i in k+1 to length(S) do
j := random(1, i); // important: inclusive range
if j <= k then
R[j] := S[i]
fi
done
Reservoir sampling is and often disguised problem in Google interviews:
There is a linked list of numbers of length N. N is very large and you don't know N. You have to write a function that will return k random numbers from the list. Numbers should be completely random. Hint: 1. Use random function rand() (returns a number between 0 and 1) and irand() (return either 0 or 1) 2. It should be done in O(n).
And here's some C/C++ code:
typedef struct list {int val; list* next;} list;
void select(list* l, int* v, int n) {
int k = 0;
while (l != NULL) {
if (k < n) {
v[k] = l->val;
} else {
int c = rand() * (k + 1);
if (c < n) v[c] = l->val;
}
l = l->next;
k++;
}
}
In the case of both questions above, since N is not known, we need to use a streaming principle instead of a loop.
Hence the following pseudo-code:
// constant k is given
integer k = ...;
array R[k]; // result
integer i = 0;
integer N = 0;
procedure processNewListElement (element)
N := N + 1 // N is unknown in advance, counting it myself
i := i + 1
if i <= k then
R[i] := element // initialization
else
j := random(1, i); // important: inclusive range
if j <= k then
R[j] := element
fi
fi
end proc
Intiuitive idea :
Let's use a distributed algorithm running this way
Hypothesis:
- Arrange every server logically by givien them numbers unique numbers from 1 to n with no holeswe can imagine a distributed algorithm running this way:
- Each node initializes a new consolidated <string (url) -> int (sum of visits among all distributed maps)> map
- Each node computes its ten most visited URLs and put them in its consolidated map
- For i in 2 to n (= number of server) times
- Node [i - 1] communicates its ten most visited URLs from its consolidated map along with their visit
counter to node n
- At the same time, Node [i] receives from its right neihbour its set of ten most visited URL
- Node [i] computes from this new set of ten URLS it has just received and its own set, the new set of ten
most visited URLs and merges the resultin its consolidated map
- Node [n] now holds the answer
We end up in a O(mn) algorithm
One should not that the algorithm can be significantly optimized by having several nodes working at the same time instead of just one at a time as above.
For instance, we can imagine parallelizing the work following a rule of 2. And end up with the following example for n=20
Step 1 using t=2 : 1 -> 2 3 -> 4 5 -> 6 7 -> 8 9 ->10 11->12 13->14 15->16 17->18 19->20 Step 2 using t=4 : 2 -> 4 6 -> 8 10->12 14->16 18->20 Step 3 using t=8 : 4 -> 8 12->16 Step 3 using t=16: 8 ->16 Step 4 (last) : 16->20
This concerptually the same as putting all co mputers in a B-Tree and have at iteratrion 1 the lowest leaf communicates theur results to the higher node, then up and up again at each iteration until the root node has the result.
Ending up this time in O(m log n)
This works if the servers are not clusters load balancing the same application. If every server has a different set of URLs, the the global top ten is amongst the top ten of each invidual servers.
If, on the other hand, several servers serve the same URLS, the global top ten may be consolidated froms URLs not listed in the individual top ten of each server.
Distributed sorting
Another possibility, likely to perform better, is first sporting the data and then taking the top 10 results.
See http://dehn.slu.edu/courses/spring09/493/handouts/sorting.pdf
Solution in C/C++:
http://www.geeksforgeeks.org/merge-two-sorted-linked-lists/
Recursive solution: (Destructive algorithm)
Node MergeLists(Node list1, Node list2) {
if (list1 == null) {
return list2;
}
if (list2 == null) {
return list1;
}
if (list1.data < list2.data) {
list1.next = MergeLists(list1.next, list2);
return list1;
} else {
list2.next = MergeLists(list2.next, list1);
return list2;
}
}
|
Iterative solution: (Destructive as well)
Node mergeLists (Node list1, Node list2) {
ret = NULL
cur = NULL
while (list1 != null and list2 != null) {
prev = cur
if (list1.data == list2.data) {
// no duplicates here
cur = list1
list1 = list1.next
list2 = list2.next
} else if (list1.data < list2.data) {
cur = list1
list1 = list1.next
} else {
cur = list2
list1 = list2.next
}
if (ret == null) {
ret = cur
} else {
prev.next = cur
}
}
if (list1 == null) {
cur.next = list2;
}
if (list2 == null) {
cur.next = list1;
}
return ret
}
|
5. Given a set of intervals (time in seconds) find the set of intervals that overlap
Given a list of intervals, ([x1,y1],[x2,y2],...), what is the most efficient way to find all such intervals that overlap with [x,y]?
It depends:
1. If the question is to be answered only once for one single interval, then we're better of with a one time (O(n)) run through all intervals and return the set of intervals that respect
xStart < yEnd and xEnd > yStart
2. On the other hand, if the question should be answered again and again, we're better of with a complexe data structure :
2.a Using an "interval tree"
In computer science, an interval tree is an ordered tree data structure to hold intervals.
Specifically, it allows one to efficiently find all intervals that overlap with any given interval or point. It is often used for windowing queries, for instance, to
find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene.
Construction
Given a set of n intervals on the number line, we want to construct a data structure so that we can efficiently retrieve all intervals overlapping another interval or point.
We start by taking the entire range of all the intervals and dividing it in half at x_center (in practice, x_center should be picked to keep the tree relatively balanced).
This gives three sets of intervals, those completely to the left of x_center which we'll call S_left, those completely to the right of x_center which we'll call S_right,
and those overlapping x_center which we'll call S_center.
The intervals in S_left and S_right are recursively divided in the same manner until there are no intervals left.
The intervals in S_center that overlap the center point are stored in a separate data structure linked to the node in the interval tree. This data structure consists of two lists, one containing all the intervals sorted by their beginning points, and another containing all the intervals sorted by their ending points.
The result is a binary tree with each node storing:
- A center point
- A pointer to another node containing all intervals completely to the left of the center point
- A pointer to another node containing all intervals completely to the right of the center point
- All intervals overlapping the center point sorted by their beginning point
- All intervals overlapping the center point sorted by their ending point
Construction requires O(n log n) time, and storage requires O(n + log n) = O(n) space.
Example for following intervals:
c=
a=[1..............6][78][9..10]=g
b=[1...2][3...4][5....8][9....11]=h
d= e= [8..9][1011]=i
f=
Gives us this tree:
Nr (6)
<[a,e]
>[e,a]
/ \
/ \
Nl1 (3) Nl2 (9)
<[d] <[f,g,h]
>[d] >[g,h,f]
/ / \
/ / \
Nl3 (2) Nl4 (8) Nl4 (11)
<[b] <[c] <[i]
>[b] >[c] >[i]
Given the data structure constructed above, we receive queries consisting of ranges or points, and return all the ranges in the original set overlapping this input.
a) Intersecting with an interval
We have now a simpe and recursive method. We start at each node (root initially) :
- If the value is contained in the interval, add all stored intervals to result list
- recursively call left
- recursively call right
- ELSE if the value is not contained in the interval but before the interval start
- search end point list for intervals ending after searched interval starts and add them to result list
- recursively call right
- ELSE if the value is not contained in the interval but after the interval ends
- search start point list for intervals starting before searched interval ends and add them to result list
- recursively call left
We end up with the set of overlaping intervals.
In average O(log n), O(n) in the worst case.
b) interseting with a point
Almost the same algorithm applies for a search with a point:
- if the value is before the searched value
- search end point list for intervals ending after searched value and add them to result list
- recursively call right
- ELSE if the value is after the searched value
- search start point list for intervals starting before searched value and add them to result list
- recursively call left
Source on wikipedia : http://en.wikipedia.org/wiki/Interval_tree
and http://en.wikipedia.org/wiki/Segment_tree
If you look at a graph of size 1, it's 0. 2, it's 1. 3, it's 3 (a -> b, a ->c, b ->c) 4, it's 6 (a -> b, a -> c, a ->d, b->c, b->d, c->d)
If you notice, the first node points to all of the other nodes except itself, the next node points to all the other nodes except the first node and itself, and this keeps decreasing by one, so you get (n-1) + (n-2) + ... + 2 + 1
Knowing that the sum of all number from 0 to n = (n x (n+1))/2, this is the sum of 1 to n-1, which is (n x (n-1))/2.
7. What's the difference between finally, final and finalize in Java?
- Finally: deals with exception handling: a finally block is always executed no matter whether or not the internal block threw an exception. If an exception has been thrown, the finally block is executed after the exception handler
- A final variable cannot be changed after construction. In case the variable is a reference (in opposition to a primitive type), its reference cannot be changed. The referenced object can however be modified if its not immutable.
- The finalize method on an object is called upon garbage collection.
8. Remove duplicate lines from a large text
Simple brute-force solution (very little memory consumption): Do an n^2 pass through the file and remove duplicate lines.
Speed: O(n^2), Memory: constant
Fast (but poor, memory consumption): Hashing solution (see below): hash each line, store them in a map of some sort and remove a line whose has already exists.
Speed: O(n), memory: O(n)
If you're willing to sacrifice file order (I assume not, but I'll add it): You can sort the lines, then pass through removing duplicates.
speed: O(n*log(n)), Memory: constant
Hashing solution:
If you have unlimited (or very fast) disk i/o, you could write each line to its own file with the filename being the hash + some identifier indicating order (or no order, if order is irrelevant). In this manner, you use the file-system as extended memory. This should be much faster than re-scanning the whole file for each line.
In addition, if you expect a high duplicate rate, you could maintain some threshold of the hashes in memory as well as in file. This would give much better results for high duplicate rates. Since the file is so large, I doubt n^2 is acceptable in processing time. My solution is O(n) in processing speed and O(1) in memory. It's O(n) in required disk space used during runtime, however, which other solutions do not have.
9. Given a string, find the minimum window containing a given set of characters
Let's use S = 'acbbaca' and T = 'aba'. The idea is mainly based on the help of two pointers (begin and end position of the window) and two tables (needToFind and hasFound) while traversing S. needToFind stores the total count of a character in T and hasFound stores the total count of a character met so far. We also use a count variable to store the total characters in T that's met so far (not counting characters where hasFound[x] exceeds needToFind[x]). When count equals T's length, we know a valid window is found.
Each time we advance the end pointer (pointing to an element x), we increment hasFound[x] by one. We also increment count by one if hasFound[x] is less than or equal to needToFind[x]. Why? When the constraint is met (that is, count equals to T's size), we immediately advance begin pointer as far right as possible while maintaining the constraint.
How do we check if it is maintaining the constraint? Assume that begin points to an element x, we check if hasFound[x] is greater than needToFind[x]. If it is, we can decrement hasFound[x] by one and advancing begin pointer without breaking the constraint. On the other hand, if it is not, we stop immediately as advancing begin pointer breaks the window constraint.
Finally, we check if the minimum window length is less than the current minimum. Update the current minimum if a new minimum is found.
Essentially, the algorithm finds the first window that satisfies the constraint, then continue maintaining the constraint throughout.

i) S = 'acbbaca' and T = 'aba'.

ii) The first minimum window is found. Notice that we cannot advance begin pointer as hasFound['a'] == needToFind['a'] == 2. Advancing would mean breaking the constraint.

iii) The second window is found. begin pointer still points to the first element 'a'. hasFound['a'] (3) is greater than needToFind['a'] (2). We decrement hasFound['a'] by one and advance begin pointer to the right.

iv) We skip 'c' since it is not found in T. Begin pointer now points to 'b'. hasFound['b'] (2) is greater than needToFind['b'] (1). We decrement hasFound['b'] by one and advance begin pointer to the right.

v) Begin pointer now points to the next 'b'. hasFound['b'] (1) is equal to needToFind['b'] (1). We stop immediately and this is our newly found minimum window.
Both the begin and end pointers can advance at most N steps (where N is S's size) in the worst case, adding to a total of 2N times. Therefore, the run time complexity must be in O(N).
// Returns false if no valid window is found. Else returns
// true and updates minWindowBegin and minWindowEnd with the
// starting and ending position of the minimum window.
bool minWindow(const char* S, const char *T,
int &minWindowBegin, int &minWindowEnd) {
int sLen = strlen(S);
int tLen = strlen(T);
int needToFind[256] = {0};
for (int i = 0; i < tLen; i++)
needToFind[T[i]]++;
int hasFound[256] = {0};
int minWindowLen = INT_MAX;
int count = 0;
for (int begin = 0, end = 0; end < sLen; end++) {
// skip characters not in T
if (needToFind[S[end]] == 0) continue;
hasFound[S[end]]++;
if (hasFound[S[end]] <= needToFind[S[end]])
count++;
// if window constraint is satisfied
if (count == tLen) {
// advance begin index as far right as possible,
// stop when advancing breaks window constraint.
while (needToFind[S[begin]] == 0 ||
hasFound[S[begin]] > needToFind[S[begin]]) {
if (hasFound[S[begin]] > needToFind[S[begin]])
hasFound[S[begin]]--;
begin++;
}
// update minWindow if a minimum length is met
int windowLen = end - begin + 1;
if (windowLen < minWindowLen) {
minWindowBegin = begin;
minWindowEnd = end;
minWindowLen = windowLen;
} // end if
} // end if
} // end for
return (count == tLen) ? true : false;
This actually works:
a c b d a b a c d a c b d a
[ ]
[ ]
[ ]
[---]
[ ]
[ ]
[ ]
[ ]
[ ]
[ ]
Source : http://discuss.leetcode.com/questions/97/minimum-window-substring
Rotating a string means rotating two parts of a string around a pivot
Example:
If s1 = "stackoverflow" then the following are some of its rotated versions:
"tackoverflows" "ackoverflowst" "overflowstack"
Solution:
First make sure s1 and s2 are of the same length. Then check to see if s2 is a substring of s1 concatenated with s1:
algorithm checkRotation(string s1, string s2)
if (len(s1) != len(s2))
return false
if (substring(s2,concat(s1,s1))
return true
return false
end
In Java:
boolean isRotation(String s1,String s2) {
return (s1.length() == s2.length()) && ((s1+s1).indexOf(s2) != -1);
}
11. What is the sticky bit and why is it used?
Traditional behaviour on executables
The sticky bit was introduced in the Fifth Edition of Unix for use with pure executable files. When set, it instructed the operating system to retain the text segment of the program in swap space after the process exited. This speeds up subsequent executions by allowing the kernel to make a single operation of moving the program from swap to real memory. Thus, frequently-used programs like editors would load noticeably faster. One notable problem with "stickied" programs was replacing the executable (for instance, during patching); to do so required removing the sticky bit from the executable, executing the program and exiting to flush the cache, replacing the binary executable, and then restoring the sticky bit.
Currently, this behavior is only operative in HP-UX, NetBSD, and UnixWare. Solaris appears to have abandoned this in 2005.[citation needed] The 4.4-Lite release of BSD retained the old sticky bit behavior but it has been subsequently dropped from OpenBSD (as of release 3.7) and FreeBSD (as of release 2.2.1); it remains in NetBSD. No version of Linux has ever supported this traditional behaviour.
Behaviour on folders
The most common use of the sticky bit today is on directories. When the sticky bit is set, only the item's owner, the directory's owner, or the superuser can rename or delete files. Without the sticky bit set, any user with write and execute permissions for the directory can rename or delete contained files, regardless of owner. Typically this is set on the /tmp directory to prevent ordinary users from deleting or moving other users' files. This feature was introduced in 4.3BSD in 1986 and today it is found in most modern Unix systems.
Source : http://en.wikipedia.org/wiki/Sticky_bit.
Quicksort is a divide and conquer algorithm. Quicksort first divides a large list into two smaller sub-lists: the low elements and the high elements. Quicksort can then recursively sort the sub-lists.
The steps are:
- Pick an element, called a pivot, from the list.
- Reorder the list so that all elements with values less than the pivot come before the pivot, while all elements with values greater than the pivot come after it (equal values can go either way). After this partitioning, the pivot is in its final position. This is called the partition operation.
- Recursively sort the sub-list of lesser elements and the sub-list of greater elements.
The base case of the recursion are lists of size zero or one, which never need to be sorted.
Naive implementation
In simple pseudocode, the algorithm might be expressed as this:
function quicksort('array')
if length('array') = 1
return 'array' // an array of zero or one elements is already sorted
select and remove a pivot value 'pivot' from 'array'
create empty lists 'less' and 'greater'
for each 'x' in 'array'
if 'x' = 'pivot' then append 'x' to 'less'
else append 'x' to 'greater'
return concatenate(quicksort('less'), 'pivot', quicksort('greater')) // two recursive calls
Notice that we only examine elements by comparing them to other elements. This makes quicksort a comparison sort.
The correctness of the partition algorithm is based on the following two arguments:
- At each iteration, all the elements processed so far are in the desired position: before the pivot if less than the pivot's value, after the pivot if greater than the pivot's value (loop invariant).
- Each iteration leaves one fewer element to be processed (loop variant).
The correctness of the overall algorithm can be proven via induction: for zero or one element, the algorithm leaves the data unchanged; for a larger data set it produces the concatenation of two parts, elements less than the pivot and elements greater than it, themselves sorted by the recursive hypothesis.
In-place version
The disadvantage of the simple version above is that it requires O(n) extra storage space, which is as bad as merge sort. The additional memory allocations required can also drastically impact speed and cache performance in practical implementations. There is a more complex version which uses an in-place partition algorithm and can achieve the complete sort using O(log n) space (not counting the input) on average (for the call stack). We start with a partition function:
// left is the index of the leftmost element of the array
// right is the index of the rightmost element of the array (inclusive)
// number of elements in subarray = right-left+1
function partition(array, left, right, pivotIndex)
pivotValue := array[pivotIndex]
swap array[pivotIndex] and array[right] // Move pivot to end
storeIndex := left
for i from left to right - 1 // left = i < right
if array[i] < pivotValue
swap array[i] and array[storeIndex]
storeIndex := storeIndex + 1
swap array[storeIndex] and array[right] // Move pivot to its final place
return storeIndex
Tesing it:
a = [1, 9, 5, 4, 8, 6, 2, 3, 4, 7, 5]
( idx = 0 1 2 3 4 5 6 7 8 9 10 )
Call : partition (a, 0, 10, 5)
pivotValue := 6
swap : [1, 9, 5, 4, 8, '6', 2, 3, 4, 5, '7'] -> [1, 9, 5, 4, 8, '7', 2, 3, 4, 5, '6']
storeIndex := 0
i=0 array[i] = 1 <6 true
swap without effet
storeIndex = 1
i=1 array[i] = 9
i=2 array[i] = 5 <6 true
swap : [1, '9', '5', 4, 8, 7, 2, 3, 4, 5, 6] -> [1, '5', '9', 4, 8, 7, 2, 3, 4, 5, 6]
storeIndex = 2
i=3 array[i] = 4 <6 true
swap : [1, 5, '9', '4', 8, 7, 2, 3, 4, 5, 6] -> [1, 5, '4', '9', 8, 7, 2, 3, 4, 5, 6]
storeIndex = 3
i=4 array[i] = 8
i=5 array[i] = 7
i=6 array[i] = 2
swap : [1, 5, 4, '9', 8, 7, '2', 3, 4, 5, 6] -> [1, 5, 4, '2', 8, 7, '9', 3, 4, 5, 6]
storeIndex = 4
i=7 array[i] = 3
swap : [1, 5, 4, 2, '8', 7, 9, '3', 4, 5, 6] -> [1, 5, 4, 2, '3', 7, 9, '8', 4, 5, 6]
storeIndex = 5
i=8 array[i] = 4
swap : [1, 5, 4, 2, 3, '7', 9, 8, '4', 5, 6] -> [1, 5, 4, 2, 3, '4', 9, 8, '7', 5, 6]
storeIndex = 6
i=9 array[i] = 5
swap : [1, 5, 4, 2, 3, 4, '9', 8, 7, '5', 6] -> [1, 5, 4, 2, 3, 4, '5', 8, 7, '9', 6]
storeIndex = 7
LastSwap:
swap : [1, 5, 4, 2, 3, 4, 5, '8', 7, 9, '6'] -> [1, 5, 4, 2, 3, 4, 5, '6', 7, 9, '8']
return storeIndex = 7 which is the last place of the pivot
This is the in-place partition algorithm. It partitions the portion of the array between indexes left and right, inclusively, by moving all elements less than array[pivotIndex] before the pivot, and the equal or greater elements after it. In the process it also finds the final position for the pivot element, which it returns. It temporarily moves the pivot element to the end of the subarray, so that it doesn't get in the way. Because it only uses exchanges, the final list has the same elements as the original list. Notice that an element may be exchanged multiple times before reaching its final place. Also, in case of pivot duplicates in the input array, they can be spread across the right subarray, in any order. This doesn't represent a partitioning failure, as further sorting will reposition and finally "glue" them together.
This form of the partition algorithm is not the original form; multiple variations can be found in various textbooks, such as versions not having the storeIndex. However, this form is probably the easiest to understand.
Once we have this, writing quicksort itself is easy:
function quicksort(array, left, right)
// If the list has 2 or more items
if left < right
// See "Choice of pivot" section below for possible choices
choose any pivotIndex such that left = pivotIndex = right
// Get lists of bigger and smaller items and final position of pivot
pivotNewIndex := partition(array, left, right, pivotIndex)
// Recursively sort elements smaller than the pivot
quicksort(array, left, pivotNewIndex - 1)
// Recursively sort elements at least as big as the pivot
quicksort(array, pivotNewIndex + 1, right)
Each recursive call to this quicksort function reduces the size of the array being sorted by at least one element, since in each invocation the element at pivotNewIndex is placed in its final position. Therefore, this algorithm is guaranteed to terminate after at most n recursive calls. However, since partition reorders elements within a partition, this version of quicksort is not a stable sort.
In average, quick sort runs on O(n log n).
In the worst case, i.e. the most unbalanced case, each time we perform a partition we divide the list into two sublists of size 0 and n-1.
This means each recursive call processes a list of size one less than the previous list. Consequently, we can make n-1 nested calls before we
reach a list of size 1. This means that the call tree is a linear chain of n-1 nested calls. So in that case Quicksort take O(n^2) time
13. Describe a partition-based selection algorithm
Selection by sorting
Selection can be reduced to sorting by sorting the list and then extracting the desired element. This method is efficient when many selections need to be made from a list, in which case only one initial, expensive sort is needed, followed by many cheap extraction operations. In general, this method requires O(n log n) time, where n is the length of the list.
Linear minimum/maximum algorithms
Linear time algorithms to find minima or maxima work by iterating over the list and keeping track of the minimum or maximum element so far.
Nonlinear general selection algorithm
Using the same ideas used in minimum/maximum algorithms, we can construct a simple, but inefficient general algorithm for finding the kth smallest or kth largest item in a
list, requiring O(kn) time, which is effective when k is small. To accomplish this, we simply find the most extreme value and move it to the beginning until we reach our
desired index. This can be seen as an incomplete selection sort.
Here is the minimum-based algorithm:
function select(list[1..n], k)
for i from 1 to k
minIndex = i
minValue = list[i]
for j from i+1 to n
if list[j] < minValue
minIndex = j
minValue = list[j]
swap list[i] and list[minIndex]
return list[k]
Other advantages of this method are:
- After locating the jth smallest element, it requires only O(j + (k-j)^2) time to find the kth smallest element, or only O(1) for k = j.
- It can be done with linked list data structures, whereas the one based on partition requires random access.
Partition-based general selection algorithm
A general selection algorithm that is efficient in practice, but has poor worst-case performance, was conceived by the inventor of quicksort, C.A.R. Hoare, and is known as Hoare's selection algorithm or quickselect.
In quicksort, there is a subprocedure called partition that can, in linear time, group a list (ranging from indices left to right) into two parts, those less than a certain element, and those greater than or equal to the element. (See previous question above)
In quicksort, we recursively sort both branches, leading to best-case O(n log n) time. However, when doing selection, we already know which partition our desired element lies in, since the pivot is in its final sorted position, with all those preceding it in sorted order and all those following it in sorted order. Thus a single recursive call locates the desired element in the correct partition:
function select(list, left, right, k)
if left = right // If the list contains only one element
return list[left] // Return that element
// select pivotIndex between left and right
pivotNewIndex := partition(list, left, right, pivotIndex)
pivotDist := pivotNewIndex - left + 1
// The pivot is in its final sorted position,
// so pivotDist reflects its 1-based position if list were sorted
if pivotDist = k
return list[pivotNewIndex]
else if k < pivotDist
return select(list, left, pivotNewIndex - 1, k)
else
return select(list, pivotNewIndex + 1, right, k - pivotDist)
Note the resemblance to quicksort: just as the minimum-based selection algorithm is a partial selection sort, this is a partial quicksort, generating and partitioning only O(log n) of its O(n) partitions. This simple procedure has expected linear performance, and, like quicksort, has quite good performance in practice.
It is also an in-place algorithm, requiring only constant memory overhead, since the tail recursion can be eliminated with a loop like this:
function select(list, left, right, k)
loop
// select pivotIndex between left and right
pivotNewIndex := partition(list, left, right, pivotIndex)
pivotDist := pivotNewIndex - left + 1
if pivotDist = k
return list[pivotNewIndex]
else if k < pivotDist
right := pivotNewIndex - 1
else
k := k - pivotDist
left := pivotNewIndex + 1
Like quicksort, the performance of the algorithm is sensitive to the pivot that is chosen. If bad pivots are consistently chosen, this degrades to the minimum-based selection described previously, and so can require as much as O(n^2) time.
Source on wikipedia : http://en.wikipedia.org/wiki/Selection_algorithm#Partition-based_general_selection_algorithm.
Use the algorithm above.
The initial call should be Select(A, 0, N, (N-1)/2) if N is odd; you'll need to decide exactly what you want to do if N is even.
Or given that the list of integers is known short, simply sort the values o(n log n) and pick up the median one once they are sorted.
15. Given a set of intervals, find the interval which has the maximum number of intersections.
Key idea : if one first sorts all points of all intervals O(n log n), then one simply needs to browse the point once O(n) and analyze the situation at each encounterd point.
Trying the following algorithm. The algorithm returns a map of intersections count for each interval.
Initialization :
- sorted_points = sort all points (interval starts and ends, start points precedes equivalent end points)
- result = new Map <Interval -> Number>
- current = new List<Interval> // Use to store current intervals
- nb_current = 0
Algorithm:
For each point p in sorted_points do
i = interval matching p
if p is an interval start then
result[i] = nb_current
increment nb_current
for each other in current do
increment result[other]
end for
add i in current
else
remove i from current
decrement nb_current
end if
end for
Testing it with:
c=
a=[1..............6][78][9....10]=g
b=[1...2][3...4][5....8][9....11]=h
d= e= [8..9]
f=
Initialisations:
- sorted_points = {1, 1, 2, 3, 4, 5, 6, 7, 8, 8, 8, 9, 9, 9, 10, 11}
a b b d d e a c f c e g h f g h
- nb_current = 0
Point p=1 / i=a Point p=1 / i=b Point p=2 / i=b
result[a] = 0 result[b] = 1 current = {a}
nb_current = 1 nb_current = 2 nb_current = 1
current = {a} result[a] = 1
current = {a, b}
Point p=3 / i=d Point p=4 / i=d Point p=5 / i=e
result[d] = 1 current = {a} result[e] = 1
nb_current = 2 nb_current = 1 nb_current = 2
result[a] = 2 result[a] = 3
current = {a, d} current = {a, e}
Point p=6 / i=a Point p=7 / i=c Point p=8 / i=f
current = {e} result[c] = 1 result[f] = 2
nb_current = 1 nb_current = 2 nb_current = 3
result[e] = 2 result[e] = 3
current = {e, c} result[c] = 2
current = {e, c, f}
Point p=8 / i=c Point p=8 / i=e Point p=9 / i=g
current = {e, f} current = {f} result[g] = 1
nb_current = 2 nb_current = 1 nb_current = 2
result[f] = 3
current = {f, g}
Point p=9 / i=h Point p=9 / i=f Point p=10 / i=g
result[h] = 2 current = {g, h} current = {h}
nb_current = 3 nb_current = 2 nb_current = 1
result[f] = 4
result[g] = 2
current = {f, g, h}
Point p=11 / i=h
current = {}
nb_current = 1
Results :
reault = {f=4, g=2, e=3, c=2, a=3, h=2, b=1, d=1}
We know that sum(i=1..n) = n x (n + 1) / 2.
Hence the sum of these numbers = 100 * 101 / 2 = x
hence the value of the missing card is equals to x minus the actual sum of the cards which can easily be computed.
sum = 0;
n = 100;
for( i =1; i <= n; i++) {
sum += array[i];
}
print( (n*(n+1)/2 ) - sum )
If nore than one number is missing, see
http://stackoverflow.com/questions/3492302/easy-interview-question-got-harder-given-numbers-1-100-find-the-missing-numbe
This idea is as follows: since we have now two or more missing variables, one needs to find a system of two or more equations.
For 2 missing values, one can use for instance x + = theoretical_sum - real_sum and x^2 + y^2 = theoretical_sum_of_square - real_sum_of_square. For more value, need use higher power functions.
Very similar to the problem above.
We know that sum(i=1..n) = n x (n + 1) / 2.
If there are no duplicates, and yet N nubers between 1 to N, it means we have all the nubers between 1 to N.
Hence the sum of these numbers = 100 * 101 / 2 = x
We're left with computing the actual sum of the array (O(n))
sum = 0;
n = 100;
for( i =1; i <= n; i++) {
sum += array[i];
}
print(sum)
Let's store that sum in y.
If x is not equals to y then
- knowing that the N numbers are between 1 and N (not greater than N, nor smaller that 1)
- One of the i=1..N is missing (otherwise x would have been equals to y)
- Still there are N numbers
- Hence at least one of the i=1..N is duplicated
All the numbers are positive to start with.
Now, For each A[i], Check the sign of A[A[i]]. Make A[A[i]] negative if it's positive.
Report a repetition if it's negative.
Finally all those entries i,for which A[i] is negative are present and those i for which A[i] is positive are absent.
In addition, finding a number already negative when wanting to set a number negative indicates a duplicate.
Runs in O(n) setting negatives and detecting duplicates + O(n) again looking for missing elements => O(n) total time complexity.
Detecting duplicates:
Pseudo-code:
for every index i in list
check for sign of A[abs(A[i])] ;
if positive then
make it negative by A[abs(A[i])]=-A[abs(A[i])];
else // i.e., A[abs(A[i])] is negative
this element (ith element of list) is a repetition
Implementation in C++:
#include <stdio.h>
#include <stdlib.h>
void printRepeating(int arr[], int size)
{
int i;
printf("The repeating elements are: \n");
for (i = 0; i < size; i++)
{
if (arr[abs(arr[i])] >= 0)
arr[abs(arr[i])] = -arr[abs(arr[i])];
else
printf(" %d ", abs(arr[i]));
}
}
int main()
{
int arr[] = {1, 2, 3, 1, 3, 6, 6};
int arr_size = sizeof(arr)/sizeof(arr[0]);
printRepeating(arr, arr_size);
getchar();
return 0;
}
Note: The above program doesn't handle 0 case (If 0 is present in array). The program can be easily modified to handle that also. It is not handled to keep the code simple.
Output:
The repeating elements are: 1 3 6
Detecting missing elements
This simply consists in one additional O(n) loop through the array looking for indices containing positive values. Each of this index represents a missing value, the value given by the index
Source : http://www.geeksforgeeks.org/find-duplicates-in-on-time-and-constant-extra-space/.
With N=100 and k=1
With one single ball, not much of a choice: need to start with floor 1 and climb one floor after the other until N=100 is reached.
hence in the worst case 100 attempts are required.
With N=100 and k=2
The answer is 14. The strategy is to drop the first ball from the K-th story; if it breaks, you know that the answer is between 1 and K and you have to use at most K-1 drops to find it out, thus K drops will be used. It the first ball does not break when dropped from the K-th floor, you drop it again from the (K+K-1)-th floor, then, if it breaks, you find the critical floor between K+1 and K+K-1 in K-2 drops, i.e., again, the total number of drops is K. Continue until you get above the top floor or you drop the first ball K times. Therefore, you have to choose K so that the total number of floors covered in K steps, which is K(k+1)/2, is greater that 100 (the total size of the building). 13*14/2=91 -- too small. 14*15/2=105 -- enough.
Obviously, the only possible strategy is to drop the first ball with some "large" intervals and then drop the last ball with interval 1 inside the "large" interval set by the two last drops of the first ball. If you claim that you can finish in 13 drops, you cannot drop the first ball for the first time from a floor above 13, since then you won't be able to detect the critical floor 13. The next cannot be above 25 etc.
Hence in the worst case 14 attempts are required.
With N=100 and k=3
TODO To Be Continued
18. Why are manhole covers round?
Reasons for the shape include:
- A round manhole cover cannot fall through its circular opening, whereas a square manhole cover may fall in if it were inserted diagonally in the hole. (A Reuleaux triangle or other curve of constant width would also serve this purpose, but round covers are much easier to manufacture. The existence of a "lip" holding up the lid means that the underlying hole is smaller than the cover, so that other shapes might suffice.)
- Round tubes are the strongest and most material-efficient shape against the compression of the earth around them, and so it is natural that the cover of a round tube assume a circular shape.
- The bearing surfaces of manhole frames and covers are machined to assure flatness and prevent them from becoming dislodged by traffic. Round castings are much easier to machine using a lathe.
- Circular covers do not need to be rotated to align with the manhole.
- A round manhole cover can be more easily moved by being rolled.
- A round manhole cover can be easily locked in place with a quarter turn (as is done in countries like France). They are then hard to open unless you are authorised and have a special tool. Also then they do not have to be made so heavy traffic passing over them cannot lift them up by suction.
First approximative approach:
public static int getAngleInDegreesBetweenHandsOnClock (int hour /*0-59*/, int minute /*0-59*/) {
int angleFromNoonBig = (hour * 360 / 12) + (minute * 360 / 12 / 60);
int angleFromNoonSmall = minute * 360 / 60;
return Math.abs (angleFromNoonBig - angleFromNoonSmall);
}
A little more precise approach
public static double getAngleInDegreesBetweenHandsOnClock (int hour /*0-59*/, int minute /*0-59*/,
int second /*0-59*/) {
double angleFromNoonBig = ((double)hour * 360 / 12) + ((double)minute * 360 / 12 / 60)
+ ((double)second * 360 / 12 / 60 / 60);
double angleFromNoonSmall = ((double)minute * 360 / 60) + ((double)second * 360 / 60 / 60);
return Math.abs (angleFromNoonBig - angleFromNoonSmall);
}
19.b. How many times a day does a clock's hands overlap?
22 times a day if you only count the minute and hour hands overlapping. (12:00, 1:05, 2:11, 3:16, etc.)
2 times a day if you only count when all three hands overlap. This occurs at midnight and noon.
One can use the algorithm above to ensure this:
List<String> result = new ArrayList<String>();
for (int i = 0; i < 60; i++) {
for (int j = 0; j < 60; j++) {
for (int k = 0; k < 60; k++) {
double angle = DateUtils.getAngleInDegreesBetweenHandsOnClock(i, j, k);
if (angle < 0.045 && angle > -0.045) {
result.add (i + ":" + j + ":" + k);
}
}
}
}
System.err.println (result);
Which gives:
[0:0:0, 1:5:27, 2:10:55, 3:16:22, 4:21:49, 5:27:16, 6:32:44, 7:38:11, 8:43:38, 9:49:5, 10:54:33]
20. What is a priority queue ? And what are the cost of the usual operations ?
[priority queue]
In computer science, a priority queue is an abstract data type which is like a regular queue or stack data structure, but where additionally each element has a "priority" associated with it. In a priority queue, an element with high priority is served before an element with low priority. If two elements have the same priority, they are served according to their order in the queue.
In fact, a priority queue is pretty much a sorted list, which is kept sorted upon insertion.
One usual implementation relies on a Linked List, respecting following properties:
- Insertion : in O(log n) if implemented using a binary search approach to find insertion point.
- Removal: in O(log n) using same approach
- Search of an element : in O(log n) using same approach
- get successor or predecessor : in O(log n) using same approach
- Get min or max : in constant time - O(1) - by using the head pointer or tail pointer.
Initial construction here is O(n log n). I do not see a better way also online docs (wikipedia) show that there should be some ...
21. Tree traversal
Describe and discuss common tree traversal algorithms
[Tree traversal algos]
In computer science, tree traversal refers to the process of visiting (examining and/or updating) each node in a tree data structure, exactly once, in a systematic way. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
The algorithms we'll discuss here are considered Depth-first
Pre-order
Algorithm principle:
- Visit the root.
- Traverse the left subtree.
- Traverse the right subtree.
With the following pseudo-code:
preorder(node)
if node == null then return
visit(node)
preorder(node.left)
preorder(node.right)
|
iterativePreorder(node)
parentStack = empty stack
while not parentStack.isEmpty() or node != null
if node != null then
parentStack.push(node)
visit(node)
node = node.left
else
node = parentStack.pop()
node = node.right
|
In-order
Algorithm principle:
- Traverse the left subtree.
- Visit the root.
- Traverse the right subtree.
With the following pseudo-code:
inorder(node)
if node == null then return
inorder(node.left)
visit(node)
inorder(node.right)
|
iterativeInorder(node)
parentStack = empty stack
while not parentStack.isEmpty() or node != null
if node != null then
parentStack.push(node)
node = node.left
else
node = parentStack.pop()
visit(node)
node = node.right
|
Post-order
Algorithm principle:
- Traverse the left subtree.
- Traverse the right subtree.
- Visit the root.
With the following pseudo-code:
postorder(node)
if node == null then return
postorder(node.left)
postorder(node.right)
visit(node)
|
iterativePostorder(node)
if node == null then return
nodeStack.push(node)
prevNode = null
while not nodeStack.isEmpty()
currNode = nodeStack.peek()
if prevNode == null or prevNode.left == currNode
or prevNode.right == currNode
if currNode.left != null
nodeStack.push(currNode.left)
else if currNode.right != null
nodeStack.push(currNode.right)
else if currNode.left == prevNode
if currNode.right != null
nodeStack.push(currNode.right)
else
visit(currNode)
nodeStack.pop()
prevNode = currNode
|
Source on wikipedia : http://en.wikipedia.org/wiki/Tree_traversal
22. Graph traversal
Describe and discuss common graph traversal algorithms
[Graph Search algo]
Depth-first search (DFS) is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root (selecting some node as the root in the graph case) and explores as far as possible along each branch before backtracking.
DFS is an uninformed search that progresses by expanding the first child node of the search tree that appears and thus going deeper and deeper until a goal node is found, or until it hits a node that has no children. Then the search backtracks, returning to the most recent node it hasn't finished exploring. In a non-recursive implementation, all freshly expanded nodes are added to a stack for exploration.
Algorithm :
Input: A graph G and a vertex v of G
Output: A labeling of the edges in the connected component of v as discovery edges and back edges
1 procedure DFS(G,v): 2 label v as explored 3 for all edges e in G.adjacentEdges(v) do 4 if edge e is unexplored then 5 w <- G.adjacentVertex(v,e) 6 if vertex w is unexplored then 7 label e as a discovery edge 8 recursively call DFS(G,w) 9 else 10 label e as a back edge
Complexity : O(|V|)
breadth-first search (BFS) is a strategy for searching in a graph when search is limited to essentially two operations: (a) visit and inspect a node of a graph; (b) gain access to visit the nodes that neighbor the currently visited node. The BFS begins at a root node and inspects all the neighboring nodes. Then for each of those neighbor nodes in turn, it inspects their neighbor nodes which were unvisited, and so on. Compare it with the depth-first search.
The algorithm uses a queue data structure to store intermediate results as it traverses the graph, as follows:
- Enqueue the root node
- Dequeue a node and examine it
- If the element sought is found in this node, quit the search and return a result.
- Otherwise enqueue any successors (the direct child nodes) that have not yet been discovered.
- If the queue is empty, every node on the graph has been examined so quit the search and return "not found".
- If the queue is not empty, repeat from Step 2.
Note: Using a stack instead of a queue would turn this algorithm into a depth-first search.
Algorithm :
Input: A graph G and a root v of G
1 procedure BFS(G,v): 2 create a queue Q 3 enqueue v onto Q 4 mark v 5 while Q is not empty: 6 t <- Q.dequeue() 7 if t is what we are looking for: 8 return t 9 for all edges e in G.adjacentEdges(t) do 12 u <- G.adjacentVertex(t,e) 13 if u is not marked: 14 mark u 15 enqueue u onto Q
The time complexity can be expressed as O(|V|+|E|) since every vertex and every edge will be explored in the worst case.
Source on wikipedia : http://en.wikipedia.org/wiki/Graph_traversal
23. How to find Inorder Successor in Binary Search Tree
In Binary Tree, Inorder successor of a node is the next node in Inorder traversal of the Binary Tree. Inorder Successor is NULL for the last node in Inorder traversal.
In Binary Search Tree, Inorder Successor of an input node can also be defined as the node with the smallest key greater than the key of input node. So, it is sometimes important to find next node in sorted order.
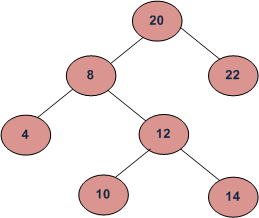
In the above diagram, inorder successor of 8 is 10, inorder successor of 10 is 12 and inorder successor of 14 is 20.
Method 1 (Uses Parent Pointer)
In this method, we assume that every node has a parent pointer.
The Algorithm is divided into two cases on the basis of right subtree of the input node being empty or not.
/>
Input: node, root // where node is the node whose Inorder successor is needed.
output: succ // where succ is Inorder successor of node.
- If right subtree of node is not NULL, then succ lies in right subtree. Do following.
Go to right subtree and return the node with minimum key value in right subtree. - If right sbtree of node is NULL, then succ is one of the ancestors. Do following.
Travel up using the parent pointer until you see a node which is left child of it's parent. The parent of such a node is the succ.
Method 2 (Search from root)
Simnply use iterative inorder. When value is found, return next visited node if any
findSucessor(node, value)
parentStack = empty stack
found = false;
while not parentStack.isEmpty() or node != null
if node != null then
parentStack.push(node)
node = node.left
else
node = parentStack.pop()
// here comes the trick
if (node.value == value) then
found = true
if (found) then
return node.value
node = node.right
24. Write a method to pretty print a binary tree
Key Idea : Use a recursive method that generates the left and right subtrees as an array of string (lines of strings).
Then, when the subtrees arrays of strings are generated, merge them together horizontally and add the root node on top with the
value located at the location of junction of both sub matrices.
___________________ | __A__ | |_____/_ _\_____| | B | | C | | .... | | .... | |_______| |_______|
Using A BFS traversal of the tree enables us then to print the nodes right at the order in which they need to be printed. One only needs to store the level with each node when the node is put in the traversal queue
Time complexity = O(n), space complexity = O(n)
Some pseudo code could be:
procedure printTree (node)
leftTreePrint = printTree (node.left)
rightTreePrint = printTree (node.right)
underPart = appendSide (leftTreePrint, rightTreePrint);
value = node.information
fullLength = max (length (leftPrintTree) + length (rightPrintTree), length (value) + 2)
firstLine = node.information;
firstLine = padLeft (value, max (length (leftPrintTree), 1))
firstLine = padRight (value, max (length (rightPrintTree), 1))
secondLine = ... # Put " /-------- ------ \" above values of left and right subtree
underPart = appendTop (secondLine, underPart)
return appendTop (firstLine, underPart)
Implementation in Java is as follows, assuming a node is defined this way:
node.leftnode.informationnode.right
public class TreePrinter {
public static String printTree(Node<?> root) {
MutableInt rootPos = new MutableInt(0);
char[][] printLines = printTree (root, rootPos);
StringBuilder builder = new StringBuilder();
for (char[] line : printLines) {
if (line != null) {
builder.append (String.valueOf(line));
builder.append("\n");
}
}
return builder.toString();
}
private static char[][] printTree(Node root, MutableInt retPos) {
if (root == null) {
return null;
}
MutableInt retPosLeft = new MutableInt(0);
MutableInt retPosRight = new MutableInt(0);
char[][] leftTreePrint = printTree (root.left, retPosLeft);
char[][] rightTreePrint = printTree (root.right, retPosRight);
String value = root.information.toString();
int lengthLeft = getLength(leftTreePrint, value);
int lengthRight = getLength(rightTreePrint, value);
char[][] under = appendSide (leftTreePrint, lengthLeft, rightTreePrint, lengthRight);
// if one is null, use one space instead
int fullLength = lengthLeft + lengthRight;// printLength (under); // min 3 !!!
if (value.length() + 2 > fullLength) {
fullLength = value.length() + 1;
}
// 1. Fill in first line
char[] firstLine = new char[fullLength];
Arrays.fill(firstLine, ' ');
int pos = lengthLeft - (value.length() / 2);
if (pos < 0) {
pos = 0;
}
retPos.setValue(pos);
System.arraycopy(value.toCharArray(), 0, firstLine, pos, value.length());
// 2. Fill in second line
char[] secondLine = null;
if (under != null && under.length > 0) {
secondLine = new char[fullLength];
Arrays.fill(secondLine, ' ');
if (leftTreePrint != null && leftTreePrint.length > 0) {
int posLeftTree = retPosLeft.intValue() + root.left.information.toString().length() / 2;
secondLine[posLeftTree >= 0 ? posLeftTree : 0] = '/';
// underscores on first line
if (posLeftTree + 1 < pos) {
Arrays.fill(firstLine, posLeftTree + 1, pos, '_');
}
}
if (rightTreePrint != null && rightTreePrint.length > 0) {
int posRightTree = lengthLeft + retPosRight.intValue()
+ root.right.information.toString().length() / 2;
secondLine[posRightTree >= 1 ? posRightTree : 1] = '\\';
// underscores on first line
if (pos + value.length() < posRightTree) {
Arrays.fill(firstLine, pos + value.length(), posRightTree, '_');
}
}
}
// 3. append underneath tree
return appendTop (firstLine, secondLine, under, lengthLeft, lengthRight); // pad under with left and right spaces if required
}
private static int getLength(char[][] treePrint, String value) {
int length = printLength (treePrint);
if (length < (value.length() + 1) / 2) {
length = (value.length() + 1) / 2;
}
return length;
}
private static char[][] appendTop(char[] firstLine, char[] secondLine,
char[][] under, int lengthLeft, int lengthRight) {
int maxWidth = firstLine.length;
if (secondLine != null && secondLine.length > maxWidth) {
maxWidth = secondLine.length;
}
if (under != null && under.length > 0 && under[0].length > maxWidth) {
maxWidth = under[0].length;
}
char[][] result = new char[1 + (secondLine != null ? 1 : 0) + under.length][];
result[0] = padLine (firstLine, maxWidth);
if (secondLine != null) {
result[1] = padLine (secondLine, maxWidth);
if (under != null && under.length > 0) {
for (int i = 0; i < under.length; i++) {
result[2 + i] = padLineDirection (under[i], maxWidth,
lengthLeft > lengthRight ? false : true);
}
}
}
return result;
}
private static char[] padLineDirection(char[] line, int maxWidth, boolean left) {
int leftPadCounter = 0;
int rightPadCounter = 0;
char[] result = new char[maxWidth];
for (int i = 0; i < maxWidth - line.length; i++) {
if (left) {
result[leftPadCounter] = ' ';
leftPadCounter++;
} else {
result[maxWidth - 1 - rightPadCounter] = ' ';
rightPadCounter++;
}
}
System.arraycopy(line, 0, result, leftPadCounter, line.length);
return result;
}
private static char[] padLine(char[] line, int maxWidth) {
int leftPadCounter = 0;
int rightPadCounter = 0;
char[] result = new char[maxWidth];
for (int i = 0; i < maxWidth - line.length; i++) {
if (i % 2 == 1) {
result[leftPadCounter] = ' ';
leftPadCounter++;
} else {
result[maxWidth - 1 - rightPadCounter] = ' ';
rightPadCounter++;
}
}
System.arraycopy(line, 0, result, leftPadCounter, line.length);
return result;
}
private static char[][] appendSide(char[][] leftTreePrint, int lengthLeft, char[][] rightTreePrint,
int lengthRight) {
int maxHeight = 0;
if (leftTreePrint != null) {
maxHeight = leftTreePrint.length;
}
if (rightTreePrint != null && rightTreePrint.length > maxHeight) {
maxHeight = rightTreePrint.length;
}
char[][] result = new char[maxHeight][];
// Build assembled row
for (int i = 0; i < maxHeight; i++) {
char[] leftRow = null;
if (leftTreePrint != null && i < leftTreePrint.length) {
leftRow = leftTreePrint[i];
}
char[] rightRow = null;
if (rightTreePrint != null && i < rightTreePrint.length) {
rightRow = rightTreePrint[i];
}
result[i] = appendRow (leftRow, rightRow, lengthLeft, lengthRight);
}
return result;
}
private static char[] appendRow(char[] leftRow, char[] rightRow, int maxWidthLeft, int maxWidthRight) {
char[] result = new char[maxWidthLeft + maxWidthRight];
if (leftRow != null) {
System.arraycopy(leftRow, 0, result, 0, leftRow.length);
} else {
Arrays.fill(result, 0, maxWidthLeft, ' ');
}
if (rightRow != null) {
System.arraycopy(rightRow, 0, result, maxWidthLeft, rightRow.length);
} else {
Arrays.fill(result, maxWidthLeft, maxWidthLeft + maxWidthRight, ' ');
}
return result;
}
private static int printLength(char[][] under) {
if (under != null && under.length > 0) {
return under[0].length;
}
return 0;
}
}
25.a. What is dynamic programming ?
[Dynamic Programming]
In mathematics, computer science, and economics, dynamic programming is a method for solving complex problems by breaking them down into simpler subproblems. It is applicable to problems exhibiting the properties of overlapping subproblems and optimal substructure (described below). When applicable, the method takes far less time than naive methods.
The key idea behind dynamic programming is quite simple. In general, to solve a given problem, we need to solve different parts of the problem (subproblems), then combine the solutions of the subproblems to reach an overall solution. Often, many of these subproblems are really the same. The dynamic programming approach seeks to solve each subproblem only once, thus reducing the number of computations: once the solution to a given subproblem has been computed, it is stored or "memo-ized": the next time the same solution is needed, it is simply looked up. This approach is especially useful when the number of repeating subproblems grows exponentially as a function of the size of the input.
There are two key attributes that a problem must have in order for dynamic programming to be applicable: optimal substructure and overlapping subproblems. If a problem can be solved by combining optimal solutions to non-overlapping subproblems, the strategy is called "divide and conquer". This is why mergesort and quicksort are not classified as dynamic programming problems.
Optimal substructure means that the solution to a given optimization problem can be obtained by the combination of optimal solutions to its subproblems. Consequently,
the first step towards devising a dynamic programming solution is to check whether the problem exhibits such optimal substructure. Such optimal substructures are usually
described by means of recursion. For example, given a graph G=(V,E), the shortest path p from a vertex u to a vertex v exhibits optimal substructure: take any intermediate
vertex w on this shortest path p. If p is truly the shortest path, then the path p1 from u to w and p2 from w to v are indeed the shortest paths between the corresponding
vertices (by the simple cut-and-paste argument described in Introduction to Algorithms). Hence, one can easily formulate the solution for finding shortest paths in a recursive
manner, which is what the Bellman-Ford algorithm or the Floyd-Warshall algorithm does.
KEJ: I.e. shorted_path (v, w = min (for each u "neighbours of v" do shorted_path(u, w)) where memoization consists of the shortest_path (x, y)already computed.
Overlapping subproblems means that the space of subproblems must be small, that is, any recursive algorithm solving the problem should solve the same subproblems over and over, rather than generating new subproblems. For example, consider the recursive formulation for generating the Fibonacci series: Fi = Fi-1 + Fi-2, with base case F1 = F2 = 1. Then F43 = F42 + F41, and F42 = F41 + F40. Now F41 is being solved in the recursive subtrees of both F43 as well as F42. Even though the total number of subproblems is actually small (only 43 of them), we end up solving the same problems over and over if we adopt a naive recursive solution such as this. Dynamic programming takes account of this fact and solves each subproblem only once.
The pattern for dynamic programming:
In a nutshell, dynamic programming is recursion without repetition. Developing a dynamic programming algorithm almost always requires two distinct stages.
- Formulate the problem recursively. Write down a recursive formula or algorithm for the whole problem in terms of the answers to smaller subproblems. This is the hard part.
- Build solutions to your recurrence from the bottom up. Write an algorithm that starts with
the base cases of your recurrence and works its way up to the final solution, by considering
intermediate subproblems in the correct order. This stage can be broken down into several smaller,
relatively mechanical steps:
- Identify the subproblems. What are all the different ways can your recursive algorithm call itself, starting with some initial input? For example, the argument to recursiveFibo (see below) is always an integer between 0 and n.
- Choose a data structure to memoize intermediate results. For most problems, each recursive subproblem can be identified by a few integers, so you can use a multidimensional array. For some problems, however, a more complicated data structure is required.
- Analyze running time and space. The number of possible distinct subproblems determines the space complexity of your memoized algorithm. To compute the time complexity, add up the running times of all possible subproblems, ignoring the recursive calls. For example, if we already know F_(i-1) and F_(i-2), we can compute Fi in O(1) time, so computing the first n Fibonacci numbers takes O(n) time.
- Identify dependencies between subproblems. Except for the base cases, every recursive subproblem depends on other subproblems-which ones? Draw a picture of your data structure, pick a generic element, and draw arrows from each of the other elements it depends on. Then formalize your picture.
- Find a good evaluation order. Order the subproblems so that each subproblem comes after the subproblems it depends on. Typically, this means you should consider the base cases first, then the subproblems that depends only on base cases, and so on. More formally, the dependencies you identified in the previous step define a partial order over the subproblems; in this step, you need to find a linear extension of that partial order. Be careful!
- Write down the algorithm. You know what order to consider the subproblems, and you know how to solve each subproblem. So do that! If your data structure is an array, this usually means writing a few nested for-loops around your original recurrence.
Dynamic programming algorithms store the solutions of intermediate subproblems, often but not always in some kind of array or table. Many algorithms students make the mistake of focusing on the table (because tables are easy and familiar) instead of the much more important (and difficult) task of finding a correct recurrence.
Dynamic programming is not about filling in tables; it's about smart recursion.
Sources : Wikipedia on http://en.wikipedia.org/wiki/Dynamic_programming and others ...
In a Fibonacci series each number is the sum of the two previous numbers starting with 1,1.
The rule is Xn = Xn-1 + Xn-2
1. Naive Algorithm
A naive version of the Fibonacci sequence algorithm, which generates the n'th number of the Fibonacci sequence is as follows:
(for instance in Java)
int recursiveFib(int n) {
if (n <= 1)
return 1;
else
return recursiveFib(n - 1) + recursiveFib(n - 2);
}
Complexity
the complexity of a naive recursive fibonacci is indeed 2^n.
T(n) = T(n-1) + T(n-2) = T(n-2) + T(n-3) + T(n-3) + T(n-4) =
= T(n-3) + T(n-4) + T(n-4) + T(n-5) + T(n-4) + T(n-5) + T(n-5) + T(n-6) = ...
in each step you call T twice, thus will provide eventual asymptotic barrier of: T(n) = 2 * 2 * ... * 2 = 2^n
Space Complexity
Here we are not using any memory except the stack. Only one resursive function call occurs at a time, hence the space complexity is O(n)
2. A first better approach : use a memory
The obvious reason for the recursive algorithm's lack of speed is that it computes the same Fibonacci
numbers over and over and over. A single call to recursiveFib(n) results in one recursive call to recursiveFib(n - 1), two recursive calls to recursiveFib(n - 2), three recursive calls to
recursiveFib(n - 3), five recursive calls to recursiveFib(n - 4), and in general, F_(k-1) recursive calls to recursiveFib(n - k), for any 0 <= k < n.
For each call, we're recomputing some Fibonacci number from scratch.
We can speed up the algorithm considerably just by writing down the results of our recursive calls and looking them up again if we need them later.
This process is called memoization.
For instancre in Java:
// initialization
int F = new int[n]
for (int i = 0; i < n; i++) F[i] = -1;
int memoryFib (int n) {
if (n < 2)
return n;
else {
if (F[n] == -1)
F[n] = memoryFib(n - 1) + memoryFib(n - 2)
return F[n];
}
}
We end up here with an algorithm of time complexity O(n) and space complexity O(n), hence an exponential speedup over the previous algorithm.
3. Even better: use dynamic programming
In the example above, if we actually trace through the recursive calls made by memoryFib, we find that the memory F[] is filled from the bottom up: first F[2], then F[3], and so on, up to F[n].
Once we see this pattern, we
can replace the recursion with a simple for-loop that fills the array in order, instead of relying on the
complicated recursion to do it for us. This gives us our first explicit dynamic programming algorithm.
For instance in Java:
// initialization
int F = new int[n]
int iterativeFib (int n) {
F[0] = 0;
F[1] = 1;
for (int i = 2; i <= n; i++)
F[i] = F[i - 1]+ F[i -2];
return F[n];
}
This is still of time complexity O(n) and space complexity O(n) but removes the overhead of all the recursive method calls.
4. Best approach
We can reduce the space to O(1) by noticing that we never need more than the last two elements of the array:
int iterativeFib2 (int n) {
prev = 1;
cur = 0;
for (int i = 1 ; i <= n; i++) {
next = cur + prev;
prev = cur;
cur = next;
}
return cur;
}
This algorithm uses the non-standard but perfectly consistent base case F_1 = 1 so that iterativeFib2(0) returns the correct value 0.
25.c. Given an array, find the longest (non necessarily continuous) increasing subsequence.
Not to be confused with problem 66.c which adds a "continuous" constraint.
- Let A be our sequence [a_1, a_2, a_3, ..., a_n]
- Define q_k as the length of the longest increasing subsequence of A that ends on element a_k.
- For instance q_4 is 2 if there are two elements before "position 4" in the array that are increasing towards the value a_4
- q_1 is alway 1
- The longest increasing subsequence of A must end on some element of A, so that we can find its length by searching the q_k that has the maximum value
- All that remains is to find out the values q_k
q_k can be found recursively, as follows:
- Consider the set S_k of all i < k such that a_i < a_k. Those are all the elements of S before "positon k" that are below a_k.
- If this set is null, then all of the elements that come before a_k are greater than it, which forces q_k = 1
- Otherwise, if S_k is not null, then q has some distribution over S_k (which is discussed below)
By the general contract of q, if we maximize q over S_k, we get the length of the longest increasing subsequence in S_k.
We can append a_k to this sequence to get q_k = max (q_j | j in S_k) + 1
This means : For each q_k, look in every position j in S before q searching for the values a_j that are below a_k. These values form the set S_k. In this set, search for the maximum q_i. Add 1 to this value to obtain q_k.
If the actual subsequence is desired, it can be found in O(n) further steps by moving backward through the q-array, or else by implementing the q-array as a set of stacks, so that the above "+ 1" is accomplished by "pushing" ak into a copy of the maximum-length stack seen so far.
Naive approach
One can design the recursive aklgorithm posed above:
procedure lis_length(a, 0, end)
max = 0
for j from 0 to end do
if a[end] > a[j] then
ln = lis_length (a, j)
if ln > max then
max = ln
max = max + 1
return max
// call lis_length (a, 0, length(a) - 1) // the first time
This works, for instance on [1, 2, 1, 5, 2, 3, 4, 7, 5, 4] with longest subsequence [1, 2, 3, 4, 7]:
[1, 2, 1, 5, 2, 3, 4, 7, 5, 4]
| |
||
1
| |
2
| |
1
...
| |
3
...
| |
3
...
| |
4
...
| |
5
...
This is a typical problem where dynamic programming comes in help since we end up solving the same sub-problems over and over again.
Using dynamic programming
There is a straight-forward Dynamic Programming solution if and only if only the length is required not the soluton itself (which can later be retrieved though).
Some pseudo-code for finding the length of the longest increasing subsequence:
procedure lis_length( a )
n = a.length
q = new Array(n)
for k from 0 to n do
max = 0
for j from 0 to k do
if a[k] > a[j] then // Set S_k
if q[j] > max then
max = q[j]
q[k] = max + 1;
max = 0
for i from 0 to n do
if q[i] > max then
max = q[i]
return max;
Source on wikipedia http://www.algorithmist.com/index.php/Longest_Increasing_Subsequence.
26. Describe and discuss the MergeSort algorithm
Merge sort (also commonly spelled mergesort) is an O(n log n) comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the implementation preserves the input order of equal elements in the sorted output. Merge sort is a divide and conquer algorithm
Conceptually, a merge sort works as follows
- Divide the unsorted list into n sublists, each containing 1 element (a list of 1 element is considered sorted).
- Repeatedly merge sublists to produce new sublists until there is only 1 sublist remaining. This will be the sorted list.
Example pseudocode for top down merge sort algorithm which uses recursion to divide the list into sub-lists, then merges sublists during returns back up the call chain.
function merge_sort(list m)
// if list size is 0 (empty) or 1, consider it sorted and return it
// (using less than or equal prevents infinite recursion for a zero length m)
if length(m) <= 1
return m
// else list size is > 1, so split the list into two sublists
var list left, right
var integer middle = length(m) / 2
for each x in m before middle
add x to left
for each x in m after or equal middle
add x to right
// recursively call merge_sort() to further split each sublist
// until sublist size is 1
left = merge_sort(left)
right = merge_sort(right)
// merge the sublists returned from prior calls to merge_sort()
// and return the resulting merged sublist
return merge(left, right)
In this example, the merge function merges the left and right sublists.
function merge(left, right)
var list result
while length(left) > 0 or length(right) > 0
if length(left) > 0 and length(right) > 0
if first(left) <= first(right)
append first(left) to result
left = rest(left)
else
append first(right) to result
right = rest(right)
else if length(left) > 0
append first(left) to result
left = rest(left)
else if length(right) > 0
append first(right) to result
right = rest(right)
end while
return result
In sorting n objects, merge sort has an average and worst-case performance of O(n log n)
27. Given a circularly sorted array, describe the fastest way to locate the largest element.
Rotated circular array
We assume here the cicular array takes the form of a usual sorted array that has been rotated at some random point.
One can use the following algorithm:
T findLargestElement(T[] data, int start, int end) {
int mid = start + (end - start) / 2
if (start == mid]) {
return data[start];
}
// we search for the place the rotation took place
if (data[start] > data[mid]) {
return findLargestElement (data, start, mid);
} else {
return findLargestElement (data, mid + 1, end);
}
}
Using it for instance on [3 4 6 7 8 11 0 1 2] -> 11, we get following recusrions
[3 4 6 7 8 11 0 1 2]
indices : 0 1 2 3 4 5 6 7 8
[3 4 6 7 8 11 0 1 2]
start = 0
end = 8
mid = 0 + (8 - 0) / 2 = 4
[11 0 1 2]
start = 5
end = 8
mid = 5 + (8 - 5) / 2 = 6
[11 0]
start = 5
end = 6
mid = 5 + (6 - 5) / 2 = 5
return 11
A pointer on a circular array, unknown size, unknown start
If we face a simple pointer as input on some position on the circular array of which we know neither the start nor the length, we have no choice but a O(n) solution to browse the pointers from an element to another until we spot the place where the next element is less than the current element.
28.a Reverse a linked list. Write code in C
Both approaches (iterative and recusrive) here are destructive algorithms.
The advantage is that they don't require an additional O(n) storage.
Recursive solution
Node * reverse( Node * ptr , Node * previous) {
Node * temp;
if(ptr->next == NULL) {
ptr->next = previous;
return ptr;
} else {
temp = reverse(ptr->next, ptr);
ptr->next = previous;
return temp;
}
}
reversedHead = reverse(head, NULL);
|
Iterative solution
Node * reverse( Node * ptr ) {
Node * temp;
Node * previous = NULL;
while(ptr != NULL) {
temp = ptr->next;
ptr->next = previous;
previous = ptr;
ptr = temp;
}
return previous;
}
reversedHead = reverse(head);
|
Time Complexity : O(n)
If I cannot use recursion (which would allow easier approaches), I would use the destructive iterative reverse function above:
reversedList = reverse(list);
ptr = reversedList
while (ptr != null) {
printf ("%s,", ptr->value);
}
28.c Write a function to reverse a singly linked list, given number of links to reverse.
Use any of the funcitons abovem adding a argument l for the number of links to be reversed.
Decrease k by 1 at each iteration / recursion.
Stop when k is equals to 0.
1. Wrong solution, doesn't work
With the usual methods found on internet, the solution gets largely biased.
First let's look at these methods:
Implementation in C:
int rand7(){
int k = rand5() + rand5() + rand5() + rand5() + rand5() + rand5() + rand5();
return k / 5;
}
Extending it for any other number:
int rand_any_number_using_rand5(int new_base) {
int k = 0;
for (int i = 1; i < new_base; i++) {
k += rand5();
}
return k / new_base;
}
Or in Java:
import java.util.Random;
public class Rand {
Random r = new Random();
int rand7() {
int s = r.nextInt(5);
for (int i = 0; i < 6; i++) {
s += r.nextInt(5);
}
return s % 7;
}
}
2. Proof that these methods are wrong
let's try the following program:
import java.util.Arrays;
public class RandUtils {
public static void main (String[] args) {
int[] count = new int[7];
for (int i = 0; i < 50000; i++) {
int rand = rand7();
count[rand] = count[rand] + 1;
}
System.err.println (Arrays.toString(count));
}
static int rand7() {
double retValue = 0;
for (int i = 0; i < 7; i++) {
retValue += rand5();
}
return (int) retValue / 5;
}
static int rand5 () {
return (int) (Math.random() * 5.0 + 1.0);
}
}
Which gives :
[0, 9767, 10019, 9962, 10111, 10141, 0]
This is obvious since there are more posibilities to build the middle values than the extreme values.
3. Correct solution
A correct solution should consist in finding a way using rand5() to select with the same probability any of the numbers between 1 and X.
A binary search can be used to do the trick:
public class RandUtils {
public static void main (String[] args) {
int[] count = new int[7];
for (int i = 0; i < 50000; i++) {
int rand = rand7();
count[rand - 1] = count[rand - 1] + 1;
}
System.err.println (Arrays.toString(count));
}
static int rand7() {
return randXInt(1, 7);
}
static int randXInt(int start, int end) {
if (start == end) {
return start;
}
// if the number of values in range is odd, make it even
// (otherwise the distibution would be biased since an element would
// have twice more chance to appear than others)
int effEnd = end;
if ((end - start + 1) % 2 != 0 ) {
effEnd++;
}
int pivot = (effEnd - start) / 2 + start;
// two first values of rand 5 makes us go left, two last right
int retValue = 0;
int rand = 0;
do {
rand = rand5();
if (rand == 1 || rand == 2) {
retValue = randXInt (start, pivot);
} else if (rand == 4 || rand == 5) {
retValue = randXInt (pivot + 1, effEnd);
}
} while (rand == 3);
if (end != effEnd && retValue == effEnd) {
// retry
return randXInt(start, end);
}
return retValue;
}
static int rand5 () {
return (int) (Math.random() * 5.0 + 1.0);
}
}
Which gives:
[7150, 7228, 7033, 7281, 7049, 7156, 7103]
Hence a pretty uniform distribution.
Time complexity is O(log n) and space complexity O(log n) as well (function calls on the stack).
Let's start by creating an equation. Let x be the probability of a car passing the intersection in a 5 minute window.
Probability of a car passing in a 20 minute window = 1 - (probability of no car passing in a 20 minute window)
Probability of a car passing in a 20 minute window = 1 - (1 - probability of a car passing in a 5 minute window)^4
0.9 = 1 - (1 - x)^4
(1 - x)^4 = 0.1
1 - x = 10^(-0.25)
x = 1 - 10^(-0.25) = 0.4377
30.b. You are given biased coin. Find unbiased decision out of it?
Throw the biased coin twice. Classify it as true for HT and false for TH.
Both of these occur with probability=p*(1-p),hence unbiased. Ignore the other 2 events namely HH and TT.
Source : http://sudhansu-codezone.blogspot.ch/2012/02/unbiased-decision-from-biased-coin.html
(Very simple answer: A Mutex is a Semaphore with value 1)
Mutexes are typically used to serialise access to a section of re-entrant code that cannot be executed concurrently by more than one thread. A mutex object only allows one thread into a controlled section, forcing other threads which attempt to gain access to that section to wait until the first thread has exited from that section
A semaphore restricts the number of simultaneous users of a shared resource up to a maximum number. Threads can request access to the resource (decrementing the semaphore), and can signal that they have finished using the resource (incrementing the semaphore). A semaphore is initialized with the number of threads that can use it concurrently (the initial value). A binary semaphore enables one single thread at a time.
The mutex is similar to the principles of the binary semaphore with one significant difference: the principle of ownership. Ownership is the simple concept that when a task locks (acquires) a mutex, then only it can unlock (release) it. If a task tries to unlock a mutex it hasn't locked (thus doesn't own) then an error condition is encountered and, most importantly, the mutex is not unlocked. If the mutual exclusion object doesn't have ownership then, irrelevant of what it is called, it is not a mutex.
With a Mutex, no other thread can unlock the lock in your thread. With "binary-semaphore" any other thread can unlock the lock in your thread. So, if you are very particular about using binary-semaphore instead of mutex, then you should be very careful in "scoping" the locks and unlocks. I mean that every control-flow that hits every lock should hit an unlock call, also there shouldn't be any "first unlock", rather it should be always "first lock".
In order to protect access to an increment operation, the underlying variable should be considered as a protected resource, hence a mutex seems more appropriate.
32. Write a C program which measures the the speed of a context switch on a UNIX/Linux system.
Key idea:
Use two programs that perform a lot of computation and saturate the CPU on a single CPU machine. Then force these programs to trigger context switches
(by calling yield, not an IO since we don't want to measure the time lost on IOs). Measure the time used by the programs for actual computation.
The total execution (elapses) time minus the computation time is the time actually used for all the context switches. The time required for a context switch.
The program should be designed such a way that its computation time is below the time quantom and that it doesn't trigger unwanted context switches (IOs, wait, etc.)
Write a program that :
- Initialize 'duration' to 0
- Run a loop, let's say 100k times:
- Get current system time tick, nanosecond precision and store in 'start'
- Performs an operation (like incrementing a dummy variable 100k times) hopefully below the time quantum,
Let's admit that it should last a few milliseconds only. - Increment 'yield_count'
- Set 'duration' += getCurrentSystemTick() - 'start'
- Call yield() system call to give up its execution and force the scheduler to schedule another process
- Echo duration on the console
The program should be executed on a system with a very minimal set of systems threads and almost no other processes (in order to avoid interference).
Then one only needs to execute this program twice at the same time, measure the time of completion of both processes and store that time in 'total'
A rough approximation of a context switch (at process level) is then:
('total' - ('duration a' + 'duration b')) / 200k
The same approach shiuld be usable to measure the time of a context switch at thread level by using posix threads instead of distincts processes.
33. Design a class library for writing card games.
I would implement the following classes:
- Game: a class that represents the card game, which contains decks, cards and sets of players.
- Deck: a stack of cards that could be initialized and used as the full cards deck (52 cards) and drawn from it to other decks like player hands or ground stacks.
- Card: the actual card object.
- Combination: Any arbitrary set of cards
- Player: represents a player which may hold a combination
One can imagine the following attributes and/or methods for each class:
|--------------------------| |--------------------------| |-------------------------|
| Game | | Deck | | Card |
|--------------------------| |--------------------------| |-------------------------|
| - String name | | - abstract format | | - Family family |
| - Set<Player> cards | | - Set<Card> cards | | - number |
| - Deck deck | |--------------------------| |-------------------------|
|--------------------------| | Combin. pickUp (int nbr) | | bool beats (Card other) |
| void draw(Window wnd) | | int remainingCnt() | |-------------------------|
|--------------------------| | void putBack (Comb. cmb) |
|--------------------------|
|-------------------------| |-------------------------|
| Combination | | Player |
|-------------------------| |-------------------------|
| - Set<Card> cards | | - int number |
|-------------------------| | - Combination comb |
| int numberCards() | |-------------------------|
| bool beats (Comb. other)|
| void add (Card card) |
| void remove (Card card) |
|-------------------------|
For both algorithms, the case of a Tree is just as sub case of the graph search BFS algorithm seen here and the DFS algorithm seen here.
The difference between tree-search and graph-search is that the graph-search algorithms need to keep track of visited nodes since a graph can have cycles, whereas a tree cannot hence no neeed to keep track of already visited nodes (a node can never get visited twice in a tree).
Complexity of BFS in terms of run time is O(n) and space O(1).
Complexity of DFS in terms of run time is O(n) and space O(n).
To take into consideration weighted edges a first idea would be to handle edges in the order given by the sorted weights.
First a note on permutations:
When considering sequences of a fixed length k of elements taken from a given set of size n. These objects are also known as partial permutations or as sequences without repetition, terms that avoids confusion with the other, more common, meanings of "permutation". The number of such k-permutations of n is denoted.
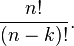
In this case we are facing simplier permutations in an array of size n, hence n! possibilities.
perm(a) = [a] perm(ab) = [perma(a).perm(b), perma(b).perm(a)] perm(abc) = [perma(a).perm(bc), perma(b).perm(a).perm(c), perma(c).perm(a).perm(b), perma(bc).perm(a)] perm(abcd) = [perm(a).perm(bcd), perm(b).perm(a).perm(cd), ...] ...
Is there any way to define a resursive notation ?
Let's write an algorithm that does just that:
import java.util.ArrayList;
import java.util.List;
public class TestPermute {
public static void main(String[] args) {
for (String in : permute ("abcd")) {
System.err.println (in);
}
}
private static List<String> permute(String string) {
List<String> permutations = new ArrayList<String>();
if (string.length() > 1) {
char fixed = string.charAt(0);
for (String other : permute (string.substring(1))) {
permutations.add (fixed + other);
for (int i = 1; i < other.length(); i++) {
permutations.add (other.substring(0, i) + fixed + other.substring(i));
}
permutations.add (other + fixed);
}
} else {
permutations.add (string);
}
return permutations;
}
}
36.a. What is a hash table ahd how is it typically implemented ?
[Hash Table principle]
A hash table (also hash map) is a data structure used to implement an associative array, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the correct value can be found.
Ideally, the hash function should assign each possible key to a unique bucket, but this ideal situation is rarely achievable in practice (unless the hash keys are fixed; i.e. new entries are never added to the table after it is created). Instead, most hash table designs assume that hash collisions-different keys that are assigned by the hash function to the same bucket-will occur and must be accommodated in some way.
In a well-dimensioned hash table, the average cost (number of instructions) for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key-value pairs, at constant average (amortized indeed) cost per operation
Choosing a good hash function
A good hash function and implementation algorithm are essential for good hash table performance, but may be difficult to achieve.
A basic requirement is that the function should provide a uniform distribution of hash values. A non-uniform distribution increases the number of collisions, and the cost of resolving them. Uniformity is sometimes difficult to ensure by design, but may be evaluated empirically using statistical tests, e.g. a Pearson's chi-squared test for discrete uniform distributions.
The distribution needs to be uniform only for table sizes s that occur in the application. In particular, if one uses dynamic resizing with exact doubling and halving of s, the hash function needs to be uniform only when s is a power of two. On the other hand, some hashing algorithms provide uniform hashes only when s is a prime number.
For open addressing schemes, the hash function should also avoid clustering, the mapping of two or more keys to consecutive slots. Such clustering may cause the lookup cost to skyrocket, even if the load factor is low and collisions are infrequent. The popular multiplicative hash[3] is claimed to have particularly poor clustering behavior.
Cryptographic hash functions are believed to provide good hash functions for any table size s, either by modulo reduction or by bit masking. They may also be appropriate, if there is a risk of malicious users trying to sabotage a network service by submitting requests designed to generate a large number of collisions in the server's hash tables. However, the risk of sabotage can also be avoided by cheaper methods (such as applying a secret salt to the data, or using a universal hash function).
Collision resolution
Hash collisions are practically unavoidable when hashing a random subset of a large set of possible keys. For example, if 2,500 keys are hashed into a million buckets, even with a perfectly uniform random distribution, according to the birthday problem there is a 95% chance of at least two of the keys being hashed to the same slot.
Therefore, most hash table implementations have some collision resolution strategy to handle such events. Some common strategies are described below. All these methods require that the keys (or pointers to them) be stored in the table, together with the associated values.
Sol 1. seperate chaining

In the method known as separate chaining, each bucket is independent, and has some sort of list of entries with the same index. The time for hash table operations is the time to find the bucket (which is constant) plus the time for the list operation. (The technique is also called open hashing or closed addressing.)
In a good hash table, each bucket has zero or one entries, and sometimes two or three, but rarely more than that. Therefore, structures that are efficient in time and space for these cases are preferred. Structures that are efficient for a fairly large number of entries are not needed or desirable. If these cases happen often, the hashing is not working well, and this needs to be fixed.
Sol 2. Open addressing

In another strategy, called open addressing, all entry records are stored in the bucket array itself. When a new entry has to be inserted, the buckets are examined, starting with the hashed-to slot and proceeding in some probe sequence, until an unoccupied slot is found. When searching for an entry, the buckets are scanned in the same sequence, until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table.[12] The name "open addressing" refers to the fact that the location ("address") of the item is not determined by its hash value. (This method is also called closed hashing; it should not be confused with "open hashing" or "closed addressing" that usually mean separate chaining.)
Advantages
The main advantage of hash tables over other table data structures is speed. This advantage is more apparent when the number of entries is large. Hash tables are particularly efficient when the maximum number of entries can be predicted in advance, so that the bucket array can be allocated once with the optimum size and never resized.
If the set of key-value pairs is fixed and known ahead of time (so insertions and deletions are not allowed), one may reduce the average lookup cost by a careful choice of the hash function, bucket table size, and internal data structures. In particular, one may be able to devise a hash function that is collision-free, or even perfect (see below). In this case the keys need not be stored in the table.
Drawbacks
Although operations on a hash table take constant time on average, the cost of a good hash function can be significantly higher than the inner loop of the lookup algorithm for a sequential list or search tree. Thus hash tables are not effective when the number of entries is very small. (However, in some cases the high cost of computing the hash function can be mitigated by saving the hash value together with the key.)
For certain string processing applications, such as spell-checking, hash tables may be less efficient than tries, finite automata, or Judy arrays. Also, if each key is represented by a small enough number of bits, then, instead of a hash table, one may use the key directly as the index into an array of values. Note that there are no collisions in this case.
The entries stored in a hash table can be enumerated efficiently (at constant cost per entry), but only in some pseudo-random order. Therefore, there is no efficient way to locate an entry whose key is nearest to a given key. Listing all n entries in some specific order generally requires a separate sorting step, whose cost is proportional to log(n) per entry. In comparison, ordered search trees have lookup and insertion cost proportional to log(n), but allow finding the nearest key at about the same cost, and ordered enumeration of all entries at constant cost per entry.
If the keys are not stored (because the hash function is collision-free), there may be no easy way to enumerate the keys that are present in the table at any given moment.
Although the average cost per operation is constant and fairly small, the cost of a single operation may be quite high. In particular, if the hash table uses dynamic resizing, an insertion or deletion operation may occasionally take time proportional to the number of entries. This may be a serious drawback in real-time or interactive applications.
O(n) memory and O(1 + n/k) comparisons for lookup in the simplest model (table of size k with chaining and n keys).
(Source : wikipedia under http://en.wikipedia.org/wiki/Hash_table#Collision_resolution)
36.b When would you use a binary tree vs. a hash map (hash table)?
Short answer :
- Use a binary search tree when there is a strong need to keep the data sorted in the data structure.
- Use a Hash Table when there is a strong need to have an average very fast retrieval (lookup) time (highly dependent however on the design of the hash table)
Has table are indeed deemed faster for lookup in average when the key generates a uniform distribution and the load factor is low. In this case lookup can be as good as O(1) while the search tree is rather O(log n).
Other considerations:
Hash Tables:
- Caution with HashTable: they have got bad performance (O(n)) at the worst case (all elements in the same bucket, i.e same hash for all elements)
- Hash Table can use a lot of extra empty space (for instance, 256 entries resevered for only 8 elements in the end)
- A worthy point on a modern architecture: A Hash table will usually, if its load factor is low, have fewer memory reads than a binary tree will. Since memory access tend to be rather costly compared to burning CPU cycles, the Hash table is often faster.
- On the other hand, if you need to rehash everything in the hash table when you decide to extend it, this may be a costly operation which occur (amortized).
Binary trees does not have this limitation.
Binrary search trees;
- Operations (insert, search, etc.) are guaranteed O(h). If the tree is a balanced binary search tree, then O(h) = O(log n)
(Understand blanced binary search Trees are O(log n) guaranteed in the worst case while HashTable can turn to O(n) in the worst case.) - Less extra space except n pointers
- Trees tend to be the "average performer". There are nothing they do particularly well, but then nothing they do particularly bad.
- A binary search tree requires a total order relationship among the keys. A hash table requires only an equivalence or identity relationship with a consistent hash function.
Put three balls in each pan and weigh.
- If they are equal then the heavier ball is between the two balls that are left un-weighed. Put each of the two unweigthtd balls on each pan and weigh, the heavier ball is the culprit.
- If they are un-equal. Take the two balls from the heavier pan and weigh them against each other. the heavier is the culprit. In case they are equal then the one left unweighted from the first heavier pan is the culprit.
Take one pill from first, two from second, three from third and so on. Total pills are n(n+1)/2 and should weigh 10n(n+1)/2. If it weighs x gm less than that then the x'th jar is contaminated, since we took x pills from that jar which weighed 1 gm less.
Let the balls be numbered 1 to 12.
Weigh 1, 2, 3, 4 vs. 5, 6, 7, 8 with three possible outcomes:
-
If they balance, then 9,10,11,12 have the odd ball, so weigh 6,7,8 vs. 9,10,11 with three possible outcomes:
- If 6,7,8 vs. 9,10,11 balances, 12 is the odd ball. Weigh it against any other ball to determine if it's heavy or light.
- If 9,10,11 is heavy, then they contain a heavy ball. Weigh 9 vs. 10. If balanced, then 11 is the odd heavy ball, or else the heavier of 9 or 10 is the odd heavy ball.
- If 9,10,11 is light, then they contain a light ball. Weigh 9 vs. 10. If balanced, then 11 is the odd light ball, or else the lighter of 9 or 10 is the odd light ball.
-
If 5,6,7,8 > 1,2,3,4 then either 5,6,7,8 contains a heavy ball or 1,2,3,4 contains a light ball so weigh 1,2,5 vs. 3,6,12 with three possible outcomes:
- If 1,2,5 vs. 3,6,12 balances, then either 4 is the odd light ball or 7 or 8 is the odd heavy ball. Weigh 7 vs 8, if they balance then 4 is the odd light ball, or the heaviest of 7 vs 8 is the odd heavy ball.
- If 3,6,12 is heavy, then either 6 is the odd heavy ball or 1 or 2 is the odd light ball. Weigh 1 vs. 2. If balanced, then 6 is the odd heavy ball, or else the lightest of 1 vs. 2 is the odd light ball.
- If 3,6,12 is light, then either 3 is light or 5 is heavy. Weigh 3 against any other ball. If balanced, then 5 is the odd heavy ball, or else 3 is the odd light ball.
-
If 1,2,3,4 > 5,6,7,8 then either 1,2,3,4 contains a heavy ball or 5,6,7,8 contains a light ball so weigh 5,6,1 vs. 7,2,12 with three possible outcomes:
- If 5,6,1 vs. 7,2,12 balances, then either 8 is the odd light ball or 3 or 4 is the odd heavy ball. Weigh 3 vs 4. If balanced, then 8 is the odd light ball, or else the heaviest of 3 vs. 4 is the odd heavy ball.
- If 7,2,12 is heavy, then either 2 is the odd heavy ball or 5 or 6 is the odd light ball. Weigh 5 vs. 6. If balanced, then 2 is the odd heavy ball, or else the lightest of 5 vs. 6 is the odd light ball.
- If 7,2,12 is light, then either 7 is light or 1 is heavy. Weigh 7 against any other ball. If balanced, then 1 is the odd heavy ball, or else 7 is the odd light ball.
Note : same question : You are given an array [a1 To an] and we have to construct another array [b1 To bn] where bi = a1*a2*...*an/ai. you are allowed to use only constant space and the time complexity is O(n). No divisions are allowed.
Since the complexity required is O(n), the obvious O(n^2) brute force solution is not good enough here. Since the brute force solution recompute the multiplication each time again and again, we can avoid this by storing the results temporarily in an array.
First we construct an array B where element B[i] = multiplication of numbers from A[n] to A[i]. For example, if A = {4, 3, 2, 1, 2}, then B = {48, 12, 4, 2, 2}. The array B is built by browsing A from right to left, eac B[i] = A[i] * B[i + 1].
Then, we scan the array A from left to right, and have a temporary variable called product which stores the multiplication from left to right so far. Calculating OUTPUT[i] is straight forward, as OUTPUT[i] = B[i + 1] * product.
Hence the following akgorithm, in Java:
import java.util.Arrays;
public class TestMult {
public static void main(String[] args) {
int[] mult = multiplyArray (new int[] {4, 3, 2, 1, 2});
System.out.println (Arrays.toString(mult));
}
private static int[] multiplyArray(int[] in) {
int[] temp = new int[in.length];
int[] out = new int[in.length];
temp[in.length - 1] = in[in.length - 1];
for (int i = in.length - 2; i >= 0; i--) {
temp[i] = temp[i + 1] * in[i];
}
//System.out.println (Arrays.toString(temp));
int prod = 1;
for (int i = 0; i < in.length - 1; i++) {
out[i] = temp[i + 1] * prod;
prod = prod * in[i];
}
out[in.length - 1] = prod;
return out;
}
}
The above method requires only O(n) time but uses O(n) space. We have to trade memory for speed.
Is there a better way? (i.e., runs in O(n) time but without extra space?)
Yes, actually the temporary table is not required. We can have two variables called left and right, each keeping track of the product of numbers multiplied from
left->right and right->left.
Can you see why this works without extra space?
void array_multiplication(int A[], int OUTPUT[], int n) {
int left = 1;
int right = 1;
for (int i = 0; i < n; i++)
OUTPUT[i] = 1;
for (int i = 0; i < n; i++) {
OUTPUT[i] *= left;
OUTPUT[n - 1 - i] *= right;
left *= A[i];
right *= A[n - 1 - i];
}
}
Source : http://leetcode.com/2010/04/multiplication-of-numbers.html.
I would try binary search which typically works in O(log n)
A binary search is a search algorithm that operates by selecting between two distinct alternatives (dichotomies) at each step. It is a specific type of divide and conquer algorithm.
A binary search or half-interval search algorithm finds the position of a specified value (the input "key") within a sorted array. In each step, the algorithm compares the input key value with the key value of the middle element of the array. If the keys match, then a matching element has been found so its index, or position, is returned. Otherwise, if the sought key is less than the middle element's key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the input key is greater, on the sub-array to the right. If the remaining array to be searched is reduced to zero, then the key cannot be found in the array and a special "Not found" indication is returned.
An algorithm that works this way:
function find (files, n)
target <- NULL
for each file in files
if last number in file > n then
target <- file
break
return find (file, n, 0, length(file))
function find (file, n, startIdx, endIdx)
span <- (endIdx - startIdx) / 2
if span = 0 then
return not found;
index <- span + startIdx
number_at_idx = file(index)
if span == 1 then
if number_at_idx == n then
return found
else
return not found
if number_at_idx < n then
return find (file, n, index + 1, endIdx)
else
return find (file, n, startIdx, index - 1)
First let's try the ith * 2 position trick:
3
/ \
2 8
/ / \
1 5 9
/ \ \
4 6 10
index : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
value : 3 2 8 1 5 9 4 6 10
Indeed it's not the most efficient way in terms of space usage wince it leaves a lot of emtpy elements within the array.
Another better idea:
If you want to be able to reconstruct the tree as it stands, you can simply store the BST nodes in the array using a pre-order traversal.
When you want to rebuild the tree just walk through the array in order, adding the nodes normally, and the tree will end up just like it was before.
This example tree would be stored as { 3, 2, 1, 8, 5, 4, 6, 9, 10 } - there is no need for empty elements to be represented in the array.
The simpliest is to use "reverse inorder" and stop after the fifth element is encounterd. Iterative way seems preferable over recursive way:
findFifthMaximal(node)
// from iterativeReverseInorder
parentStack = empty stack
int counter = 0;
while not parentStack.isEmpty() or node != null
if node != null then
parentStack.push(node)
node = node.right
else
node = parentStack.pop()
counter++;
if counter == 5 then
return node
node = node.left
return null
If the data structure is an array
Single way I found is by cheating. I'm using the stack as a memory (hence a O(n) space complexity)
// 1 2 3 4 a b c d
// 1 a 2 b 3 c 4 d
rearrange (array)
N = length(array) / 2
i = 1
move(array, i, N)
move (array, i, N)
num_pos = i
num_target_pos = i * 2 - 1
char_pos = N + i
char_target_pos = i * 2
num = array[num_pos]
char = array[char_pos]
if (i < N) {
move (array, i + 1, N)
}
array[num_target_pos] <- num
array[char_target_pos] <- char
If the data structure is a Linked List, things get a lot easier since we can insert at random location
Use an algorithm working this way:
rearrange (node)
// locate first character
cPointer = node
while pointer.value is number do
cPointer = cPointer.next
done
while node is not null do
nextNum = node.next
node.next = cPointer
cPointer = cPointer.next // have next char here
node.next.next = nextNum
node = nextNum;
done
Proof of work:
0 : 1 2 3 4 a b c d
n c
1 : 1 a 2 3 4 b c d
n c
2 : 1 a 2 b 3 4 c d
n c
3 : 1 a 2 b 3 c 4 d
n c
4 : 1 a 2 b 3 c 4 d
Runs in time complexity O(n) and space complexity O(1)
43. Use basic operations to create a square root function.
First approach : use binary search
One can use a binary search like approach between the numbers between 1 and the target number until x * x = N.
Second approach : Babylonian method :
function sqrt(N)
oldguess = -1
guess = 1
while abs(guess-oldguess) > 1 do
oldguess = guess
guess = (guess + N/guess) / 2
return guess
44. Given a file of 4 billion 32-bit integers, how to find one that appears at least twice?
Two approaches:
1. Use in place quick sort to order the data
Then one only needs an additional O(n) browse of the data to find duplicates
2. Use a data structure of 2^32 x 1 bit to check whether a specific number has already been encountered
Which would need around 4.3 G bit of memory = ~ 512Mb of RAM provided one writes an efficient data structure.
It also requires a language that supports bitwise operations.
Implementation is easy in Java using a BitSet instance.
Use either a B-Tree or a Hash Index to store the words. Instead of the word, store a structure which associates to the word the number of times it has been encounterd.
Once that structure is built, browse every data and build a second structure indexed by counts.
Backtracking is a general algorithm for finding all (or some) solutions to some computational problem, that incrementally builds candidates to the solutions, and abandons each partial candidate c ("backtracks") as soon as it determines that c cannot possibly be completed to a valid solution.
Backtracking can be applied only for problems which admit the concept of a "partial candidate solution" and a relatively quick test of whether it can possibly be completed to a valid solution. It is useless, for example, for locating a given value in an unordered table. When it is applicable, however, backtracking is often much faster than brute force enumeration of all complete candidates, since it can eliminate a large number of candidates with a single test.
Backtracking is an important tool for solving constraint satisfaction problems, such as crosswords, verbal arithmetic, Sudoku, and many other puzzles. It is often the most convenient (if not the most efficient) technique for parsing, for the knapsack problem and other combinatorial optimization problems.
Backtracking depends on user-given "black box procedures" that define the problem to be solved, the nature of the partial candidates, and how they are extended into complete candidates. It is therefore a metaheuristic rather than a specific algorithm - although, unlike many other meta-heuristics, it is guaranteed to find all solutions to a finite problem in a bounded amount of time.
Description of the method
The backtracking algorithm enumerates a set of partial candidates that, in principle, could be completed in various ways to give all the possible solutions to the given problem. The completion is done incrementally, by a sequence of candidate extension steps.
Conceptually, the partial candidates are the nodes of a tree structure, the potential search tree. Each partial candidate is the parent of the candidates that differ from it by a single extension step; the leaves of the tree are the partial candidates that cannot be extended any further.
The backtracking algorithm traverses this search tree recursively, from the root down, in depth-first order. At each node c, the algorithm checks whether c can be completed to a valid solution. If it cannot, the whole sub-tree rooted at c is skipped (pruned). Otherwise, the algorithm (1) checks whether c itself is a valid solution, and if so reports it to the user; and (2) recursively enumerates all sub-trees of c. The two tests and the children of each node are defined by user-given procedures.
Therefore, the actual search tree that is traversed by the algorithm is only a part of the potential tree. The total cost of the algorithm is the number of nodes of the actual tree times the cost of obtaining and processing each node. This fact should be considered when choosing the potential search tree and implementing the pruning test.
Pseudo code
In order to apply backtracking to a specific class of problems, one must provide the data P for the particular instance of the problem that is to be solved, and six procedural parameters, root, reject, accept, first, next, and output. These procedures should take the instance data P as a parameter and should do the following:
root(P): return the partial candidate at the root of the search tree.reject(P,c): return true only if the partial candidate c is not worth completing.accept(P,c): return true if c is a solution of P, and false otherwise.first(P,c): generate the first extension of candidate c.next(P,s): generate the next alternative extension of a candidate, after the extension s.output(P,c): use the solution c of P, as appropriate to the application.
The backtracking algorithm reduces then to the call bt(root(P)), where bt is the following recursive procedure:
procedure bt(c)
if reject(P,c) then return
if accept(P,c) then output(P,c)
s <- first(P,c)
while s is not "the null candidate" do
bt(s)
s <- next(P,s)
(Note : the pseudo-code above will call output for all candidates that are a solution to the given instance P)
Usage considerations:
The reject procedure should be a boolean-valued function that returns true only if it is certain that no possible extension of c is a valid solution for P. If the procedure cannot reach a definite conclusion, it should return false. An incorrect true result may cause the bt procedure to miss some valid solutions. The procedure may assume that reject(P,t) returned false for every ancestor t of c in the search tree.
On the other hand, the efficiency of the backtracking algorithm depends on reject returning true for candidates that are as close to the root as possible. If reject always returns false, the algorithm will still find all solutions, but it will be equivalent to a brute-force search.
The accept procedure should return true if c is a complete and valid solution for the problem instance P, and false otherwise. It may assume that the partial candidate c and all its ancestors in the tree have passed the reject test.
Note that the general pseudo-code above does not assume that the valid solutions are always leaves of the potential search tree. In other words, it admits the possibility that a valid solution for P can be further extended to yield other valid solutions.
The first and next procedures are used by the backtracking algorithm to enumerate the children of a node c of the tree, that is, the candidates that differ from c by a single extension step. The call first(P,c) should yield the first child of c, in some order; and the call next(P,s) should return the next sibling of node s, in that order. Both functions should return a distinctive "null" candidate, denoted here by "the null candidate", if the requested child does not exist.
Together, the root, first, and next functions define the set of partial candidates and the potential search tree. They should be chosen so that every solution of P occurs somewhere in the tree, and no partial candidate occurs more than once. Moreover, they should admit an efficient and effective reject predicate.
(Source on wikipedia : http://en.wikipedia.org/wiki/Backtracking)
I'm using here a backtracking method (rather to illustrate a simple case yet standard case of backtracking).
Implementation is in Java:
public class NumberSumSolver {
final int targetNumber;
private final Map<String, Boolean> printedSolMap = new HashMap<String, Boolean>();
NumberSumSolver (int targetNumber) {
this.targetNumber = targetNumber;
}
private void printSolutionIfNotAlready(int[] numberOfNumbers) {
String key = Arrays.toString(numberOfNumbers);
if (!printedSolMap.containsKey(key)) {
printedSolMap.put (key, Boolean.TRUE);
StringBuilder solBuild = new StringBuilder();
boolean first = true;
for (int i = 0; i < numberOfNumbers.length; i++) {
if (numberOfNumbers[i] != 0) {
if (!first) {
solBuild.append (" + ");
}
solBuild.append (i + 1);
solBuild.append (" x ");
solBuild.append (numberOfNumbers[i]);
first = false;
}
}
System.out.println (solBuild);
}
}
public void printSumPossibilities() {
int[] numberOfNumbers = new int[targetNumber - 1];
for (int index = 0; index < targetNumber - 1; index++) {
numberOfNumbers[index] = 0;
}
backtrack (targetNumber, numberOfNumbers);
}
private void backtrack(int targetSum, int[] numberOfNumbers) {
if (reject (targetSum, numberOfNumbers)) {
return;
}
if (accept (targetSum, numberOfNumbers)) {
printSolutionIfNotAlready (numberOfNumbers);
}
for (int i = 0; i < numberOfNumbers.length; i++) {
numberOfNumbers[i]++;
backtrack (targetSum, numberOfNumbers);
numberOfNumbers[i]--;
}
}
private boolean reject(int targetSum, int[] numberOfNumbers) {
int curSum = 0;
for (int i = 0; i < numberOfNumbers.length; i++) {
curSum += (i + 1) * numberOfNumbers[i];
}
return curSum > targetSum;
}
private boolean accept(int targetSum, int[] numberOfNumbers) {
int curSum = 0;
for (int i = 0; i < numberOfNumbers.length; i++) {
curSum += (i + 1) * numberOfNumbers[i];
}
return curSum == targetSum;
}
public static void main (String[] args) {
new NumberSumSolver (9).printSumPossibilities ();
}
}
The above can be optinmized a lot but I'm keeping it simple for illustrating the simpliest backtrack algorithm.
The problem is mostly that the tree of solution is a graph, several paths lead to the same solutions which are evaluated again and again. Hence the need of a Map to store the solution already reported.
I simple change into building the tree of solution enables us to build a true tree where the possibilities are not repeated:
public class NumberSumSolver {
final int targetNumber;
NumberSumSolver (int targetNumber) {
this.targetNumber = targetNumber;
}
private void printSolutionIfNotAlready(int[] numberOfNumbers) {
StringBuilder solBuild = new StringBuilder();
boolean first = true;
for (int i = 0; i < numberOfNumbers.length; i++) {
if (numberOfNumbers[i] != 0) {
if (!first) {
solBuild.append (" + ");
}
solBuild.append (i + 1);
solBuild.append (" x ");
solBuild.append (numberOfNumbers[i]);
first = false;
}
}
System.out.println (solBuild);
}
public void printSumPossibilities() {
int[] numberOfNumbers = new int[targetNumber - 1];
for (int index = 0; index < targetNumber - 1; index++) {
numberOfNumbers[index] = 0;
}
backtrack (targetNumber, 0, numberOfNumbers);
}
private void backtrack(int targetSum, int index, int[] numberOfNumbers) {
if (reject (targetSum, index, numberOfNumbers)) {
return;
}
if (accept (targetSum, numberOfNumbers)) {
printSolutionIfNotAlready (numberOfNumbers);
return; // I know If I have a solution, any other on the same base cannot work
}
for (int i = 0; i < targetSum; i++) {
numberOfNumbers[index] = i;
if (index + 1 < numberOfNumbers.length) {
backtrack (targetSum, index + 1, numberOfNumbers);
}
}
numberOfNumbers[index] = 0;
}
private boolean reject(int targetSum, int index, int[] numberOfNumbers) {
int curSum = 0;
for (int i = 0; i < numberOfNumbers.length; i++) {
curSum += (i + 1) * numberOfNumbers[i];
}
return curSum > targetSum;
}
private boolean accept(int targetSum, int[] numberOfNumbers) {
int curSum = 0;
for (int i = 0; i < numberOfNumbers.length; i++) {
curSum += (i + 1) * numberOfNumbers[i];
}
return curSum == targetSum;
}
public static void main (String[] args) {
new NumberSumSolver (9).printSumPossibilities ();
}
}
Posing the problem
I would use an optimization method.
For instance let's assume we have coins of 5, 10, 20 and 50.
We're left with a classical optimization problem
min f(x) = x + y + z + a
u.c. 5x + 10y + 20z + 50a = amount
One can then optimize this problem with a branch-and-bound or branch-and-cut algorithm (both simplex based) that are discrete combinatory optimization algorithms.
Why greedy approach wouldn't work
Greedy approach (fill with bigger coins until no additional fits, then try with smaller) won't work.
See simple example:
coins = { 1, 10, 25 }
amount = 30
Greedy approach will choose 25 first and then five coins of value 1, i.e. 6 coins instead of simply 3 coins of 10.
SOLUTION: Using a simplier backtracking algorithm
We can also use recursion (with its run-time stack) to drive a backtracking algorithm. The general recursive backtracking algorithm for optimization problems (e.g., fewest number of coins) looks something like:
procedure Backtrack (recursionTreeNode p)
treeNode c;
for each child c of p do # each c represents a possible choice
if promising(c) then # c is "promising" if it could lead to a better solution
if c is a solution that's better than best then # check if this is the best solution found so far
best = c # remember the best solution
else
Backtrack(c) # follow a branch down the tree
end if
end if
end for
end procedure
Implementation in Java:
public class CoinsRenderer {
private final int changeAmt;
private final int[] coinTypes;
// global current state of the backtrack
private int[] numberOfEachCoinType = null;
private int numberOfCoinsSoFar = 0;
private int bestFewestCoins = -1;
private int[] bestNumberOfEachCoinType = null;
public CoinsRenderer (int changeAmt, int[] coinTypes) {
this.changeAmt = changeAmt;
this.coinTypes = coinTypes;
}
private void backtrack(int changeAmt) {
for (int index = coinTypes.length - 1; index >= 0; index--) {
int smallerChangeAmt = changeAmt - coinTypes[index];
if (promising(smallerChangeAmt, numberOfCoinsSoFar + 1)) {
if (smallerChangeAmt == 0) { // a solution is found
// check if its best
if (bestNumberOfEachCoinType == null || numberOfCoinsSoFar + 1 < bestFewestCoins) {
bestFewestCoins = numberOfCoinsSoFar + 1;
bestNumberOfEachCoinType = Arrays.copyOfRange(numberOfEachCoinType, 0,
numberOfEachCoinType.length);
bestNumberOfEachCoinType[index]++;
}
} else {
// update global "current state" for child before call
numberOfCoinsSoFar++;
numberOfEachCoinType[index]++;
backtrack(smallerChangeAmt);
// undo change to global "current state" after backtracking
numberOfCoinsSoFar--;
numberOfEachCoinType[index]--;
}
}
}
}
private boolean promising(int changeAmt, int numberOfCoinsReturned) {
if (changeAmt < 0) { // dummy case
return false;
} else if (changeAmt == 0) { // dummy case
return true;
} else { // changeAmt > 0
// This is simple : is the solution better than the one we have now (if we have one)?
return bestNumberOfEachCoinType == null || numberOfCoinsReturned + 1 < bestFewestCoins;
}
}
public int[] solve() {
numberOfEachCoinType = new int[coinTypes.length];
for (int index = 0; index < coinTypes.length; index++) {
numberOfEachCoinType[index] = 0;
}
backtrack(changeAmt);
return bestNumberOfEachCoinType;
}
public static void main (String[] args) {
/*
int changeAmt = 399;
int[] coinTypes = new int[] {1, 5, 10, 12, 25, 50};
*/
int changeAmt = 30;
int[] coinTypes = new int[] {1, 10, 25};
int[] bestNumberOfEachCoinType = new CoinsRenderer(changeAmt, coinTypes).solve();
System.err.println (changeAmt);
System.err.println (Arrays.toString(coinTypes));
System.err.println (Arrays.toString(bestNumberOfEachCoinType));
}
}
This works and returns the correct number of coins for each case with minimum exploration (since it starts with the biggest coin, see reverse for loop):
30 [1, 10, 25] [0, 3, 0]
or
399 [1, 5, 10, 12, 25, 50] [0, 0, 0, 2, 1, 7]
What about a standard backtrack approach ?
However with standard backtrack, the three of solution would be:
____________________[0>1]___________________
/ \
___[0>2]___ ___[1>2]___ ___[2>2]___ ...
/ | \ / | \ / | \
[0>3] [1>3] [2>3] ... [1>3] [2>3] [3>3] ... [3>3] [4>3] [5>3] ...
Hence with a lot of duplicates...
In addition Backtracking here makes no sense since it is never possible to discard a branch of the three since further nodes on a branch can still make it to the target
because the problem doesn't say that the list contains only positive integers.
If the list can contain as well negatove integers, then one needs to test all possibilities, a branch of solutions can never be discarded => backtracking is not appropriate.
if the problem is reduced to an array containing only positive integers, then backtracking is a good approach.
Here however, I am hence using a greedy solution:
private static class SubArraySolver {
private final int[] original;
private final int targetSum;
SubArraySolver (int[] original, int targetSum) {
this.original = original;
this.targetSum = targetSum;
}
public void findAllSubArrays() {
testAll (0);
}
private void testAll(int length) {
if (length > original.length) {
return;
}
for (int i = 0; i < original.length - length; i++) {;
if (accept (i, length)) {
printSolutionIfNotAlready (i, length);
}
}
testAll (length + 1);
}
private void printSolutionIfNotAlready(int start, int length) {
System.out.println (Arrays.toString (Arrays.copyOfRange(original, start, start+length)));
}
private boolean accept(int start, int length) {
int curSum = 0;
for (int i = start; i < start + length; i++) {
curSum += original[i];
}
return curSum == targetSum;
}
public static void findSubArrayWithSum (int[] array, int target) {
new SubArraySolver (array, target).findAllSubArrays();
}
public static void main (String[] args) {
findSubArrayWithSum(new int[]{1, 5, 3, 4, -1, -6, 4, 8, 2, 5, 4, -2, 8, 9, -3, 4}, 12);
}
}
Which returns:
[4, 8] [5, 3, 4] [-2, 8, 9, -3] [1, 5, 3, 4, -1] [3, 4, -1, -6, 4, 8] [-1, -6, 4, 8, 2, 5]
Simply use and of the Graph traversal algorithm. Run it on both trees at the same time and quit when the first difference is found.
One can use a modified version of inorder that stops when the first difference is found:
compare(node1, node2)
if node1 == null and node2 == null then
return true
if node1 == null or node2 == null then
return false
subResult = compare(node1.left, node2.left)
if (!subResult) then
return false
if (node1.value != node2.value) then
return false
return compare(node2.right, node2.right)
49. Write a function that flips the bits inside a byte (either in C++ or Java).
Two solutions :
1. Use the XOR operator
byte ReverseByte(byte b) { return b ^ 0xff; }
2. Use byte after byte inversion
Java or C#:
byte ReverseByte(byte b)
{
byte r = 0;
for (int i=0; i < 8; i++)
{
int mask = 1 << i;
int bit = (b & mask) >> i;
int reversedMask = bit << (7 - i);
r |= (byte)reversedMask;
}
return r;
}
50. What's 2 to the power of 64?
2^64 = 1,84467441 x 10^19
=2^32 * 2^32 = 4 294 967 296 * 4 294 967 296
First idea, somewhat brute force but not such bad since the source string is ran through only once:
int[M] findMatching (source, searches[M])
// returns index of last match of each search in source or -1
int[M] return
int[M] temp
for j in 1 to M do
return[j] <- 1
temp[j] <- 1
for i in 1 to nchar(source) do // char by char
for j in 1 to length(searches) // every searched string
search = searches[j]
if search[0] == source[i] then
temp[j] = i
else if temp[j] > -1
index = i - return[j];
if index > length(search) then
return[j] <- temp[j]
else
if search[index] != source[i] then
temp[j] = -1
In Java:
static public int[] multipleSearch (String source, String[] searches) {
int[] ret = new int[searches.length];
int[] temp = new int[searches.length];
for (int j = 0; j < searches.length; j++) {
ret[j] = - 1;
temp[j] = - 1;
}
for (int i = 0; i < source.length(); i++) { // char by char
for (int j = 0; j < searches.length; j++) { // every searched string
String search = searches[j];
if (search.charAt(0) == source.charAt(i)) {
temp[j] = i;
} else if (temp[j] > -1) {
int index = i - temp[j];
if (index >= search.length()) {
ret[j] = temp[j];
} else if (search.charAt(index) != source.charAt(i)) {
temp[j] = -1;
}
}
}
}
return ret;
}
This runs in time complexity O(m x n) and space complexity O(m)
52. Order the functions in order of their asymptotic performance: 1) 2^n 2) n^100 3) n! 4) n^n
n^n
n!
n^100
2^n
Binary search is the way to go. See binary search.
If the list to be searched contains more than a few items (a dozen, say) a binary search will require far fewer comparisons than a linear search, but it imposes the requirement that the list be sorted. Similarly, a hash search can be faster than a binary search but imposes still greater requirements. If the contents of the array are modified between searches, maintaining these requirements may even take more time than the searches. And if it is known that some items will be searched for much more often than others, and it can be arranged that these items are at the start of the list, then a linear search may be the best.
Algorithms:
Recursive:
int binary_search(int A[], int key, int imin, int imax)
{
// test if array is empty
if (imax < imin):
// set is empty, so return value showing not found
return KEY_NOT_FOUND;
else
{
// calculate midpoint to cut set in half
int imid = midpoint(imin, imax);
// three-way comparison
if (A[imid] > key)
// key is in lower subset
return binary_search(A, key, imin, imid-1);
else if (A[imid] < key)
// key is in upper subset
return binary_search(A, key, imid+1, imax);
else
// key has been found
return imid;
}
}
Iterative
int binary_search(int A[], int key, int imin, int imax)
{
// continue searching while [imin,imax] is not empty
while (imax >= imin)
{
/* calculate the midpoint for roughly equal partition */
int imid = midpoint(imin, imax);
// determine which subarray to search
if (A[imid] < key)
// change min index to search upper subarray
imin = imid + 1;
else if (A[imid] > key )
// change max index to search lower subarray
imax = imid - 1;
else
// key found at index imid
return imid;
}
// key not found
return KEY_NOT_FOUND;
}
I would use an in-place version of quick sort since it requires only O(log n) RAM storage (recursive calls on the stack).
See In place Quick sort
The in-place version of quicksort has a space complexity of O(log n), even in the worst case, when it is carefully implemented using the following strategies:
- in-place partitioning is used. This unstable partition requires O(1) space.
- After partitioning, the partition with the fewest elements is (recursively) sorted first, requiring at most O(log n) space. Then the other partition is sorted using tail recursion or iteration, which doesn't add to the call stack. This idea, as discussed above, was described by R. Sedgewick, and keeps the stack depth bounded by O(log n).
A Balanced Tree sort -> Guaranteed to be O(n log n) performance. No better, no worse.
Insertion of all elements requires n * O (log n) => o(n log n) performance.
Use three pointers. Pointer on string C is advanced at each iteration. Then either the pointer on string a or the pointer on string b is advanced depending on what character is found. Whenever the value in string C doesn't match neither of the expected value, return false.
Here's some code in Java:
public static boolean isInterleaved (String a, String b, String test) {
int idxA = 0;
int idxB = 0;
for (int i = 0; i < test.length(); i++) {
if (idxA < a.length() && test.charAt(i) == a.charAt(idxA)) {
idxA++;
} else if (idxB < b.length() && test.charAt(i) == b.charAt(idxB)) {
idxB++;
} else {
return false;
}
}
if (idxA < a.length() || idxB < b.length()) {
return false;
}
return true;
}
57. Given a Binary Tree, Programmatically you need to Prove it is a Binary Search Tree
If the given binary tree is a Binary search tree,then the inorder traversal should output the elements in increasing order.We make use of this property of inorder traversal to check whether the given binary tree is a BST or not
One can modifiy iterativeInOrder this way:
isBST(node)
prev = NULL
parentStack = empty stack
while not parentStack.isEmpty() or node != null
if node != null then
parentStack.push(node)
node = node.left
else
node = parentStack.pop()
if prev is not null then
if prev > node.value then
return false
prev = node
node = node.right
return true
58. Given an arbitrarily connected graph, explain how to ascertain the reachability of a given node.
Use any traversal algorithm and :
- either check whether the given node has been marked or not
- or return as soon as the node is encountered
One can modifiy the BFS algorithm this way:
procedure BFS(G,v,s): // s is the searched vertex
create a queue Q
enqueue v onto Q
while Q is not empty:
t <- Q.dequeue()
if t == s then
return true
for all edges e in G.adjacentEdges(t) do
u <- G.adjacentVertex(t,e)
if u is not marked:
mark u
enqueue u onto Q
return false
Idea 1 : a hash map. in the end 1001 entries. (O(n) space / O(n) time average / O(n^2) time worst case)
In this case, use a hash table with 1000 entries, using "number mod 1000" as hash function may be a good idea
Idea 2 : Insert the numbers into a balanced binary search tree, when the duplicate comes up it will find that the value already exists in the tree, and it can then return. O ( n * log n ).
The simple recurrence relation governing this problem is f(N)=f(N-1) +f(N-2),which is a fibonacci sequence.
See Generate a Fibonnaci sequence.
Nth state can be arrived directly by taking 2 step movement from N-2 or 1 step from N-1.Remember N-2 -> N-1 -> N is not a direct path from N-2th state to Nth state.
Hence the no of solutions is no of ways to reach N-2th step and then directly taking a 2 jump step to N + no of ways to reach N-1th step and then taking 1 step advance.
Notes:
- Median of median doesn't necessarily return the true median ! Hence cannot distribute the median computation across 100 computers.
- Naive Median finding algorithms runs in O(n) but can hardly be distributed.
- Sorting runs in O(n log n) but median can then be fetched in O(1)
- n = 1'000'000 => log_2 n ~= 20 => below 100
- Hence sorting first and then finding the median with usual algorithms may be interesting when using distributed sorting since:
+ O(n log n) whith log n = 20 divided on 100 computers is still more interesting than O(n) one one single computer.
+ The key idea is to have "sufficiently more" cores than log n (20)
Better idea ?
Recall partition base selection. Is there any way to distribute it ?
TODO Or any approach using MapReduce ?
62.a Implement multiplication (without using the multiply operator, obviously).
I would use binary multiplication.
One way : Repeated Shift and Add
(There are other ways)
Starting with a result of 0, shift the second multiplicand to correspond with each 1 in the first multiplicand and add to the result. Shifting each position left is equivalent to multiplying by 2, just as in decimal representation a shift left is equivalent to multiplying by 10.
Set result to 0
Repeat
Shift 2nd multiplicand left until rightmost digit is lined up with leftmost 1 in first multiplicand
Add 2nd multiplicand in that position to result
Remove that 1 from 1st multiplicand
Until 1st multiplicand is zero
Result is correct
See following steps:

|

|

|

|

|
Source : http://courses.cs.vt.edu/~cs1104/BuildingBlocks/multiply.040.html
62.b Implement division (without using the divide operator, obviously).
I would use binary division.
Basically the reverse of the mutliply by shift and add.
Set quotient to 0
Align leftmost digits in dividend and divisor
Repeat
If that portion of the dividend above the divisor is greater than or equal to the divisor then
subtract divisor from that portion of the dividend and
Concatentate 1 to the right hand end of the quotient
Else
concatentate 0 to the right hand end of the quotient
Shift the divisor one place right
Until dividend is less than the divisor
quotient is correct, dividend is remainder

Source : http://courses.cs.vt.edu/~cs1104/BuildingBlocks/divide.030.html
KEJ IDEA : since the arrays are sorted : keep moving the pointers until the solution gets better, stop when no pointer move, neither left nor right, can make the solution any better
Solution from someone else:
I am not sure if this is correct, but it seems to be correct by intuition and intuitive testing, and works alright for a few test cases.
Its also o(n)
public class NewMain {
public static void main(String[] args) {
int inp[] = {155, 160, 163, 170};
int inp2[] = {160, 162, 172};
int inp3[] = {143, 151, 159, 164, 167, 180};
int i=0, j=0, k=0; //counters
int min, max, minadd, maxadd;
int mindist=100000, mini=0, minj=0, mink=0, tempdist=0;
while(i < inp.length && j < inp2.length && k < inp3.length) {
min = inp[i];
minadd = i;
if (inp2[j] < min) {
min = inp2[j];
minadd = j;
}
if (inp3[k] < min) {
min = inp3[k];
minadd = k;
}
max=inp[i];
maxadd = i;
if (inp2[j] > max) {
max=inp2[j];
maxadd = j;
}
if (inp3[k] > max) {
max = inp3[k];
maxadd = k;
}
if ((max - min) < mindist) {
mindist = max - min;
mini=i;
minj=j;
mink=k;
}
System.out.printf("%d %d %d %d %d\n", i,j,k, max-min, mindist);
if (inp[i]==min)
i++;
if (inp2[j]==min)
j++;
if (inp3[k]==min)
k++;
}
System.out.printf("%d\n%d\n%d\n", inp[mini], inp2[minj], inp3[mink]);
}
}
Test cases:
int inp[] = {155, 160, 163, 170};
int inp2[] = {160, 162, 172};
int inp3[] = {3,9,15,21,25,31,40};
155
160
40
int inp[] = {155, 160, 163, 170};
int inp2[] = {160, 162, 172};
int inp3[] = {143, 151, 159, 164, 167, 180};
160
160
159
int inp[] = {100,200, 300};
int inp2[] = {151, 152, 152};
int inp3[] = {3,9,15,21,25,31,40};
100
151
40
Key idea: use two pointers, one starting at lowest value, other starting at value k, move first to right, second to left (inOrder order) until value is found ... or not.
Example Tree:
15
/ \
10 16
/ \ \
5 12 20
/ \ / \ / \
2 8 11 14 17 22
Solution:
// input : k
// note : in order to ease implementation of nextInOrder amd prevInOrder,
// it might be required to build a tree with backlinks as initialization step (O(n))
// Othwerwise, une iterativeInOrder and return value following, resp. preceding
// search value.
// init
min = first node inOrder
max = locate node in the tree that is either equal to k or the smallest that is greater than k
doLoop = true
// algo
while doLoop do
l = value(min) + value(max)
if (max == min && l != k) then
stop "ERROR : none found"
end if
if (l == k) then
break // min and max sum to k
else if (l < k) then
min = nextInOrder (min)
else if (l > k) then
max = prevInOrder (max)
end if
end do
Test values:
k : 10
It : 0 1 2 3 4 5 6
min : 2 2
max : 10 8
l : 12 10 DONE
k : 20
It : 0 1 2 3 4 5 6
min : 2 2 5 5 5
max : 20 17 17 16 15
l : 22 19 22 21 20 DONE
k : 18
It : 0 1 2 3 4 5 6
min : 2 2 2
max : 18 17 16
l : 20 19 18 DONE
k : 9
It : 0 1 2 3 4 5 6
min : 2 2 2 5
max : 10 8 5 5
l : 12 10 7 10 ERROR
k : 13
It : 0 1 2 3 4 5 6
min : 2 2 2
max : 14 12 11
l : 16 14 13 DONE
65. What is the KBL algorithm ?
TODO ...
This is an all-time favorite software interview question. The best way to solve this puzzle is to use Kadane's algorithm which runs in O(n) time.
The idea is to keep scanning through the array and calculating the maximum sub-array that ends at every position. The sub-array will either contain a range of numbers
if the array has intermixed positive and negative values, or it will contain the least negative value if the array has only negative values.
Here's some code to illustrate.
void maxSumSubArray( int *array, int len, int *start, int *end, int *maxSum )
{
int maxSumSoFar = -2147483648;
int curSum = 0;
int a = b = s = i = 0;
for( i = 0; i < len; i++ ) {
curSum += array[i];
if ( curSum > maxSumSoFar ) {
maxSumSoFar = curSum;
a = s;
b = i;
}
if ( curSum < 0 ) {
curSum = 0;
s = i + 1;
}
}
*start = a;
*end = b;
*maxSum = maxSumSoFar;
}
Testing it on some values:
Input : array [ 1, 2, -6, 6, 17, 12, -4, 7, -8, -11, 12, -5, 3, 4, 16, -7, -8, 12, -4, 6]
(idx) 0 1 2 3 4 5 6 7 8 9 19 11 12 13 14 15 16 17 18 19
Feelings [ 35 ]
[ 38 ]
[ 30 ]
[ 49 ]
Algo:
i : init 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
array[i] : 1 2 -6 6 17 12 -4 7 -8 -11 12 -5 3 4 16 -7 -8 12 -4 6
a : 0 0 0 3 3 3 3 3
b : 0 0 1 3 4 5 7 14
s : 0 3
curSum (bef.) : 0 1 3 -3 6 23 35 31 38 30 19 31 26 29 33 49 42 34 46 42 48
curSum (aft.) : 0 1 3 0
maxSumSoFar : -.. 1 3 6 23 35 38 49
BEST : |
66.b. Given an array, find the longest continuous(!) increasing subsequence.
Not to be confused with problem 25.c which releases the "continuous" constraint.
We can do better than backtracking (O(n^2)) in the worst case.
We can use a variant of Kadane's algorithm which runs in O(n) time.
The idea consists simply in moving the pointer from the beginning to the end of the array, incrementing the size of the longest increasing continuous sequence as long as the number increase and restarting the sequence collection as soon as a decreasing number is encountered.
Algorithm looks this way:
public static int[] findLongestContinousIncreasingSequence(int[] array) {
int start = 0;
int bestStart = 0;
int bestEnd = 1;
int bestSize = 1;
for (int i = 1; i < array.length; i++) {
if (array[i] > array[i - 1]) {
if (i - start + 1 > bestSize) {
bestSize = i - start + 1;
bestStart = start;
bestEnd = i + 1;
}
} else {
start = i;
}
}
return Arrays.copyOfRange(array, bestStart, bestEnd);
}
public static void main (String[] args) {
System.out.println (Arrays.toString (findLongestContinousIncreasingSequence(
new int[]{1, 5, 3, 4, -1, -6, 4, 8, 2, 5, 4, -2, 8, 9, 12, -3, 4})));
}
Which returns:
[-2, 8, 9, 12]
First idea in O(n) time O(n) space
Loop through space and stack words (O(n)) then unstack until stack is empty (O(n) worst case)
Second idea in O(n) time O(1) space ... well not really O(1) space
- browse input string until a space is found.
- string so far is a word
- recursively call function on end of string and append word to result
Java code:
public static String reverseString (String source) {
for (int i = 0; i < source.length(); i++) {
if (source.charAt(i) == ' ') {
if (i < source.length() + 1) {
return reverseString (source.substring(i + 1)) + ' ' + source.substring(0, i);
}
break;
}
}
return source;
}
Note This is not really O(1) space, but O(n) since it uses function calls on the stack as a memory.
68.a. Fastest algorithm or way to check a X's and 0's game (i.e. TIC TAC TOE) board.
TODO
Good solution on
http://stackoverflow.com/questions/1056316/algorithm-for-determining-tic-tac-toe-game-over-java
One approach is that you need to store all possible configurations of the board and the move that is associated with that. Then it boils down to just accessing the right element and getting the corresponding move for it. Do some analysis and do some more optimization in storage since otherwise it becomes infeasible to get the required storage in a DOS machine.
A tree storing all possible games with positions played each time would take this much storage: 9! = 362'880 nodes. One could then ask at each level of the tree which
of the subtree has the max count of wining games and then choose the next move accordingly.
(count of wining games for a node is the sum of the count of wining games of each of its sub-trees or 1 if the node is a wining game itself)
This seems to be the fastest possible way yet by sacrificing the required storage.
My idea that optimizes storage as much as possible is to store each possible game this way : 01010101, i.e. 9 positions of 0 or 1 for O or X. The problem with this is that
it doesn't store the order of each play. An exact approach
An algorithm could then run this way (somewhat probabilistic approach)
- At each move
- Find all games mathing current start game
(all of them at first)
- In these games, find all games in which I am victorious
(since all board are always completely filled, i consider victorious games where I have the single line
or games where I have more lines that the opponent)
- In all these games, find my position that comes most often (find the byte that it is the most often set)
- Play that move
The probability is 25% because there are 3 ants all with two possible paths and 8 total possible outcomes. But there are two possible outcomes that the ants don't collide. Either they move one way or the other. 2/8 = 25%.
Each ant can move in 2 directions. Lets say direction are Left (L) and Right (R). Solution if all ants move either towards L or R. For L (1/2 * 1/2 * 1/2) = 1/8. Same for R = 1/8. Total for L and R = 1/8 + 1/8 = 1/4.
Provided as example:
A
0/ \1
/ \
/ \
1/ \0
B0-----1C
Karnaugh table is as follows
ABC | Collide ? ---------------- 000 | 0 001 | 1 010 | 1 011 | 1 100 | 1 101 | 1 110 | 1 111 | 0
Which confirms: there are 2/8 = 1/4 chance they don't collide while they collide 6/8 = 3/4 times.
a) 1 and 2 cross together : 3,4 -> 1,2 - 2 min b) 1 comes back : 1,3,4 <- 2 - 1 min c) 3 and 4 cross together : 1 -> 2,3,4 - 10 min d) 2 comes back : 1,2 <- 3,4 - 2 min e) 1 and 2 cross together : -> 1,2,3,4 - 2 min
First idea:
2^x = n => x = log_2 (n)
Then, if n is a power of 2, then x is an integer
if x is integer then x % 1 = 0
One can then use 2^((int)log_2(n)) == n as a condition.
Better: (no need to use a log_2 function in C)
A power of 2 has only one bit set to 1 and all other to 0 (also value intger 1 which need to be checked).
Let's name x that power of 2.
In this case, the value (x - 1) has other bytes set to 1, always. It never has the same byte set to 1.
hence x & (x - 1) == 0, always (& = "bitwise and").
Examples:
x = 0010 0000 = 32
x-1 = 0001 1111 = 31
x & (x - 1) = 0000 0000 = 0
x = 0000 1000 = 8
x-1 = 0000 0111 = 7
x & (x - 1) = 0000 0000 = 0
Counter examples (for numbers not a power of 2)
x = 0110 0000 = 96
x-1 = 0101 1111 = 95
x & (x - 1) = 0100 0000 = 0
x = 0000 0110 = 6
x-1 = 0000 0101 = 5
x & (x - 1) = 0100 0000 = 0
We can hence come up with a one-line expression this way: ((n > 1) && !(n & n-1))
Source : http://answers.yahoo.com/question/index?qid=20080711094134AAyQ2vg
72. Give a very good method to count the number of ones in a 32 bit number.
Solution A
Brian Kernighan's method goes through as many iterations as there are set bits. So if we have a 32-bit word with only the high bit set, then it will only go once through the loop.
long count_bits(long n) {
unsigned int c; // c accumulates the total bits set in v
for (c = 0; n; c++)
n &= n - 1; // clear the least significant bit set
return c;
}
Note that this is a question used during interviews. The interviewer will add the caveat that you have "infinite memory". In that case, you basically create an array of size 232 and fill in the bit counts for the numbers at each location. Then, this function becomes O(1).
Solution B (easier to understand)
In my opinion, the "best" solution is the one that can be read by another programmer (or the original programmer two years later) without copious comments. You may well want the fastest or cleverest solution which some have already provided but I prefer readability over cleverness any time.
unsigned int bitCount (unsigned int value) {
unsigned int count = 0;
while (value > 0) { // until all bits are zero
if ((value & 1) == 1) // check lower bit
count++;
value >>= 1; // shift bits, removing lower bit
}
return count;
}
First naive idea
First naive idea consists in O(m x n) looping through the first string, then through the second string, deleting every character that appears.
Hence the following code in C:
void trimString() {
char s1[] = "hello world";
char s2[] = "el";
int i, j;
for (i = 0; i < (signed)strlen(s1); i++) {
for (j = 0; j < (signed)strlen(s2); j++) {
if (s1[i] == s2[j]) {
s1[i] = -1;
break;
}
}
}
for (i = 0, j = 0; i < (signed)strlen(s1); i++) {
if (s1[i] != -1) {
s1[j] = s1[i];
j++;
}
}
s1[j] = '\0';
printf("\nString is%s", s1);
}
Better idea using a hastable
Since you are looking for characters only, we can try using a hash table of size 256. One should note that it's not exactly a hash table since we have as many entries as elements in the table and the hash function is rather returning the element itself.
char *DeleteAndClean (char *s1, char *s2) {
char hash[256];
int i;
for(i = 0; i < 256; i ++)
hash[i] = 0; // Init Hash
char *t = s1;
while (*t) {
hash[*t] = 1; // populate hash
t++;
}
size_t count = 0;
size_t cleanlen = 0
// Iteration 1: compute length of result string
t = s2;
while (*t) {
if (hash[*t] == 1)
count++;
else
cleanlen++;
t++;
}
cleanlen++; // Include space for null Terminator
if (count == 0)
return strdup(s2);
// dynamically allocate new space for result
char* clean = (char*) malloc(sizeof(char) * cleanlen);
if (!clean)
throw out_of_mem_exception;
t = s1;
// Iteration 2: build result
while (*t) {
if (hash[*t] == 0)
*clean++ = *t;
t++;
}
*clean = '\0';
return clean;
}
Should the additional memory required to return the value be an issue (since it's O(n) space), one can use the same idea than in the former algorithm and use a destructive approach on the string given as argument.
74. Determine the 10 most frequent words given a terabyte of strings.
Use MapReduce http://en.wikipedia.org/wiki/MapReduce.
There are two problems to be solved:
- the long value must be decomposed in each of its decimal position for them to be printed individualy
- A decimal (0-9) must be converted to a char in order to be printed with put char
These two problems are easily solved this way:
- Either an iterative (using an array) or a recursive (discarding the need of an array in favor of a usage of the stack) to decompose the long number. Use division by 10 and remainder (modulo) to proceed with the decomposition
- Converting a [0-9] number to a char in ASCII or UTF-8 is easy. One only needs to add the ASCI number mathing '0' to the decimal number and one gets the ASCII number of the decimal number (No need to know where the numbers start in the ASCII sequence).
Hence the following code in C:
#include<stdio.h>
#include<string.h>
void printInt(unsigned long x){
if (x > 10){
printInt(x / 10);
}
//putchar(x % 10 + '0'); // Both will work fine
putchar(x % 10 + 48);
}
int main(){
long int a;
printf(" Enter integer value : ");
scanf("%d",&a);
printf("\n");
printInt(a);
return 0;
}
75.b. Write a function to convert an int to a string.
Very similar to the problem above. The very same approach can be used.
#include<stdio.h>
#include<string.h>
void toString(unsigned long x, char* result){
if (x > 10){
toString(x / 10, result);
}
int len = strlen(result);
result[len] = (x % 10) + '0';
result[len + 1] = \0;
}
1. The North Pole is one such place that you can walk one mile South, one mile East, one mile North and end up where you started.
2. Somewhere near the South pole, there is also a point where once you walk one mile South, you are standing at the point on the globe where the Earth's
circumference is one mile. That way once you walk one mile East, you arrive back to where you started walking East.
Of course, one mile North from there puts you back at your starting point.
In fact, there are an infinite number of points where this is true. Take the preceding case, but instead of using the place where the circumference of the
earth is one mile, use the place where the circumference of the earth is 1/2 mile and start one mile north from there. When you walk one mile East,
you simply walk around the globe twice and end up in the same spot.
This will work for a circumference of 1/3 mile, 1/4 mile, 1/5 mile, etc to infinity.
Another way the question is asked is "How can you find out if there is a loop in a very long list?"
Browse the list marking each node as visited. Stop whenever a node is encountered that is already marked (there is the loop). If the end of the list is reached then there is no loop.
Add one boolean field in structure of node as visited and initialised it will FALSE. Now start travesing the list and upon next element visit, make this boolean filed as true and before making it as true check if it is already TRUE or not. In case if it is true than there is certainly loop.
while (current ->next != NULL) do
if (current->visited == TRUE) then
printf("LOOP in LL found");
break;
else
current->visited = TRUE;
current = current->next;
end if
end do
This runs in O(n).
Whenever this list structure cannot be modified, use a hash table or a B-Tree to store the visited flag.
In this case the algorithm becomes O(n log n)
78.a. Reverse each bit in a number.
This is as easy as XORing the number with a mask made only of 1s.
For instance for a 32 bits integer:
unsigned int n = 12345..; unsigned int mask = 0xFFFFFFFF; unsigned int result = n ^ mask;
Let's use the XOR method on each 4 bit of the whole number.
Use the XOR on the four right-most bits then shift 4 bits right. Continue as long as number != 0.
TODO
I assume a two-bytes character never has 0 as its first bit, but always 1.
Hence one only needs to check the previous byte.
- If last byte starts with 0 and previous byte starts with 0 then delete last byte only
- If last byte starts with 1 and previous byte starts with 0 then crash (current byte is only half of the two-bytes character)
- Otherwise (previous byte starts with 1 and last byte starts with whatever) delete both the last and the previous byte
1. First idea : actually do the operation and check result
If adding both numbers result in an overflow, then the result is necessarily below both numbers.
(Let's imagine INT_MAX_VALUE = 10, then 9 + 2 = 11 => 1 with 1 < 9 and 1 < 2)
One can hence use the following code:
uint32_t x, y; uint32_t value = x + y; bool overflow = value < x; // Alternatively "value < y" should also work
2. Second idea : no need to actually perform the comparison but need to have access to MIN/MAX_VALUE constants
unsigned int si1, si2, sum;
/* Initialize si1 and si2 */
if ( si1 > (INT_MAX - si2)) {
/* handle error condition */
} else {
sum = si1 + si2;
}
For signed integers : the solution is only a little more complicated:
signed int si1, si2, sum;
/* Initialize si1 and si2 */
if ( ((si2 > 0) && (si1 > (INT_MAX - si2)))
|| ((si2 < 0) && (si1 < (INT_MIN - si2)))) {
/* handle error condition */
} else {
sum = si1 + si2;
}
Source : http://www.fefe.de/intof.html
and http://stackoverflow.com/questions/199333/best-way-to-detect-integer-overflow-in-c-c
This is simple. One only need to browse the string with a pointer from start forward and from end backward.
Whenever a character is encountered, make sure both pointers point to the same character (case insensitive)
Hence the following algorithm in Java:
static public boolean isPalindrome (String s) {
int len = s.length();
int start = 0;
int end = len - 1;
while (true) {
// stop condition
if (start >= end) {
return true;
}
char charStart = 0;
do {
charStart = Character.toLowerCase(s.charAt(start++));
if (start >= len) {
return true;
}
} while ( charStart == ' ' || charStart == ',' || charStart == '.'
|| charStart == '\'' || charStart == '\n');
char charEnd = 0;
do {
charEnd = Character.toLowerCase(s.charAt(end--));
if (end < 0) {
return true;
}
} while ( charEnd == ' ' || charEnd == ',' || charEnd == '.'
|| charEnd == '\'' || charEnd == '\n');
if (charStart != charEnd) {
return false;
}
}
}
Running in time complexity O(n) and space complexity O(1).
82. Write a function to find the depth of a binary tree.
The depth of a tree is the maximum of the depth of its sub-trees plus 1 for the root node. A recursive approach makes more sense.
hence the following pseudo-code:
function depth (tree)
if tree is NULL then
return 0
end if
depthLeft = depth (tree.left)
depthRight = depth (tree.right)
if depthLeft > depthRight then
return depthLeft
else
return depthRight
end if
Runs in time complexity O(n) and space complexity O(1).
83. Besides communication cost, what is the other source of inefficiency in RPC?
Context switches, excessive buffer copying.
Optimize by communicating through shared memory on same machine, bypassing the kernel.
Source : http://k2cplus.blogspot.ch/2009/12/besides-communication-cost-what-is.html
There is an algorithm in O(n) to solve this known as the Fisher - Yates shuffle algorithm. The version of this algorithm used today has been popularized by Donald E. Knuth in volume 2 of his book The Art of Computer Programming as "Algorithm P".
Pseudo-code is as follows:
To shuffle an array a of n elements (indices 0..n-1):
for i from n - 1 downto 1 do
j <- random integer with 0 <= j <= i
exchange a[j] and a[i]
There is an implementation of that algorithm in Java in Collections.shuffle() (simplified):
public static void shuffle(List<?> list, Random rnd) {
int size = list.size();
Object arr[] = list.toArray();
// Shuffle array
for (int i=size; i>1; i--)
swap(arr, i-1, rnd.nextInt(i));
// Dump array back into list
ListIterator it = list.listIterator();
for (int i=0; i < arr.length; i++) {
it.next();
it.set(arr[i]);
}
}
public static void swap(List<?> list, int i, int j) {
list.set(i, list.set(j, list.get(i)));
}
Runs in time complexity O(n) and space complexity O(1).
Source : http://en.wikipedia.org/wiki/Fisher%E2%80%93Yates_shuffle
84.b. Write an efficient algorithm and C code to shuffle a pack of cards
One simply needs to use the Fisher - Yates shuffle algorithm described above.
A deadlock occurs when a set of concurrent workers are waiting on each other to make forward progress before any of them can make forward progress. If this sounds like a paradox, it is. There are four general properties that must hold to produce a deadlock:
- Mutual Exclusion: When one thread owns some resource, another cannot acquire it. This is the case with most critical sections, but is also the case with GUIs in Windows. Each window is owned by a single thread, which is solely responsible for processing incoming messages; failure to do so leads to lost responsiveness at best, and deadlock in the extreme.
- A Thread Holding a Resource is Able to Perform an Unbounded Wait For example, when a thread has entered a critical section, code is ordinarily free to attempt acquisition of additional critical sections while it is held. This typically results in blocking if the target critical section is already held by another thread.
- Resources Cannot be Forcibly Taken Away From Their Current Owners In some situations, it is possible to steal resources when contention is noticed, such as in complex database management systems (DBMSs). This is generally not the case for the locking primitives available to managed code on the Windows platform.
- A Circular Wait Condition A circular wait occurs if chain of two or more threads is waiting for a resource held by the next member in the chain. Note that for non-reentrant locks, a single thread can cause a deadlock with itself. Most locks are reentrant, eliminating this possibility.
Let's have two ressources A and B and two threads that need a lock on these ressources. The following conditions can be identified:
T1 lock A then B / T2 lock A then B -> OK (no cycle) T1 lock A then B / T2 lock B then A -> potential DEADLOCK !
Two general strategies are useful for dealing with critical-section-based deadlocks.
- Avoid Deadlocks Altogether Eliminate one of the aforementioned four conditions. For example, you can enable multiple resources to share the same resource (usually not possible due to thread safety), avoid blocking altogether when you hold locks, or eliminate circular waits, for example. This does require some structured discipline, which can unfortunately add noticeable overhead to authoring concurrent software.
- Detect and Mitigate Deadlocks Most database systems employ this technique for user transactions. Detecting a deadlock is straightforward, but responding to them is more difficult. Generally speaking, deadlock detection systems choose a victim and break the deadlock by forcing it to abort and release its locks. Such techiques in arbitrary managed code could lead to instability, so these techniques must be employed with care.
- Avoiding Deadlocks with Lock Leveling: A common approach to combating deadlocks in large software systems is a technique called lock leveling (also known as lock hierarchy or lock ordering). This strategy factors all locks into numeric levels, permitting components at specific architectural layers in the system to acquire locks only at lower levels. For example, in the original example, I might assign lock A a level of 10 and lock B a level of 5. It is then legal for a component to acquire A and then B because B's level is lower than A's, but the reverse is strictly illegal. This eliminates the possibility of deadlock.
85.b. What is the difference between a live-lock and a deadlock ?
Deadlock
Deadlock is a situation when two processes, each having a lock on one piece of data, attempt to acquire a lock on the other's piece. Each process would wait indefinitely for the other to release the lock, unless one of the user processes is terminated. SQL Server detects deadlocks and terminates one user's process.
A deadlock occurs when two or more tasks permanently block each other by each task having a lock on a resource which the other tasks are trying to lock.
For example with database transactions:
- Transaction A acquires a share lock on row 1.
- Transaction B acquires a share lock on row 2.
- Transaction A now requests an exclusive lock on row 2, and is blocked until transaction B finishes and releases the share lock it has on row 2.
- Transaction B now requests an exclusive lock on row 1, and is blocked until transaction A finishes and releases the share lock it has on row 1.
Transaction A cannot complete until transaction B completes, but transaction B is blocked by transaction A. This condition is also called a cyclic dependency: Transaction A has a dependency on transaction B, and transaction B closes the circle by having a dependency on transaction A.
Both transactions in a deadlock will wait forever unless the deadlock is broken by an external process
Livelock:
A livelock is one, where a request for an exclusive lock is repeatedly denied because a series of overlapping shared locks keeps interfering.
A livelock is similar to a deadlock, except that the states of the processes involved in the livelock constantly change with regard to one another, none progressing. Livelock is a special case of resource starvation; the general definition only states that a specific process is not progressing.
A real-world example of livelock occurs when two people meet in a narrow corridor, and each tries to be polite by moving aside to let the other pass, but they end up swaying from side to side without making any progress because they both repeatedly move the same way at the same time.
Livelock is a risk with some algorithms that detect and recover from deadlock. If more than one process takes action, the deadlock detection algorithm can be repeatedly triggered. This can be avoided by ensuring that only one process (chosen randomly or by priority) takes action.
Linked list
I believe the best data structure is a Linked List, linked with pointers.
Dynamic memory allocation comes in help here. Using a simple structure like
struct node {
Type data;
struct node next;
};
Here any number of lists or queues can be created in the finite memory segment using dynamic memory allocation. Every queue is simply represented by two pointers, the head of the queue and the current tail of the queue.
Whenever a new element needs to be aded to a queue, a new struct instance is allocated in te hfinit memory segment, the next pointer of the current last element is updated to point to it and finally the tail pointer is updated.
The problem here is that it is inneficient in terms of memory consumption because of the overhead required to store all pointers.
Hybrid solution
This memory consumtion efficiency problem can be solved (at least a little) by using an hybrid approach. Every 10 elements of each queue is stored in an array. Each array is stored in a structure along with a pointers pointing on the next 10 elements array.
Hence a structure this way:
struct node {
Type data[10];
struct node next;
};
This way, instead of having potentially only 50% elements and 50% pointers in the finite memory segment, we can achieve 90% elements and only 10% pointers in the finite memory segment.
This is pretty appropriate for a queue where elements are always added to the tail but would be unneffective for a list with random insertion and deletions.
Group the multiplications. Specifically, use the binary value of the power. For example:
x ^ 27?
- note that 27 (base10) == 11011 (base2)
- so x ^ 27 = x^1 * x^2 * x^8 * x^16
- so calculate x^1, x^2, x^4, x^8, x^16 sequentially and store them (this costs you 4 multiplications, since you can get each successive term by squaring the previous one)
- multiply the ones that are required (see decomposition of 27 into powers of 2) together (3 multiplications)
Total cost 7 multiplications, rather than the 26 required in the naive way.
88. You have given an array. Find the maximum and minimum numbers in less number of comparisons.
I assume the array is unsorted (if it is sorted, just take first and last element).
There isn't any reliable way to get the minimum/maximum without testing every value. You don't want to try a sort or anything like that, walking through the array is O(n), which is better than any sort algorithm can do in the general case.
Naive algorithm
The naive algorithm is too loop and update min, max.
Recursive solution
A recursive solution will require less comparisons than naive algorithm, if you want to get min, max simultaneously
struct MinMax{
public int min,max;
}
MinMax FindMinMax(int[] array, int start, int end) {
if (start == end)
return new MinMax { min = array[start], max = array[start] };
if (start == end - 1)
return new MinMax { min = Math.Min(array[start], array[end]), max = Math.Max(array[start], array[end]) } ;
MinMax res1 = FindMinMax(array, start, (start + end)/2);
MinMax res2 = FindMinMax(array, (start+end)/2+1, end);
return new MinMax { min = Math.Min(res1.Min, res2.Min), max = Math.Max(res1.Max, res2.Max) } ;
}
This isn't necessarily faster due to function call overhead, not to count the memory allocation.
Best solution : iterative solution
Then there is an algorithm that finds the min and max in 3n/2 number of comparisons. What one needs to do is process the elements of the array in pairs. The larger of the pair should be compared with the current max and the smaller of the pair should be compared with the current min. Also, one needs take special care if the array contains odd number of elements.
struct MinMax{
int min,max;
}
MinMax FindMinMax(int[] array, int start, int end) {
MinMax min_max;
int index;
int n = end - start + 1;//n: the number of elements to be sorted, assuming n>0
if ( n%2 != 0 ){// if n is odd
min_max.min = array[start];
min_max.max = array[start];
index = start + 1;
}
else{// n is even
if ( array[start] < array[start+1] ){
min_max.min = array[start];
min_max.max = array[start+1];
index = start + 2;
}
int big, small;
for ( int i = index; i < n-1; i = i+2 ){
if ( array[i] < array[i+1] ){ //one comparison
small = array[i];
big = array[i+1];
}
else{
small = array[i+1];
big = array[i];
}
if ( min_max.Min > small ){ //one comparison
min_max.min = small;
}
if ( min_max.Max < big ){ //one comparison
min_max.max = big;
}
}
return min_max;
}
It's very easy to see that the number of comparisons it takes is 3n/2. The loop runs n/2 times and in each iteration 3 comparisons are performed. This is probably the optimum one can achieve.
Intuitive approach
Only half of the pirates should agree to the plan for the leader not to be killed. Here there are 5 pirates, so 3 pirates should agree to the plan.
Hence intuitively, the leader should propose to two other pirates to share the loot. He keeps 34 to himself and offers two other pirates 33 each.
Solution
The given hints states that one pirate ends up with 98% of the gold.
In this case, I assume that the leader keeps 98 gold coins and gives two other pirates 1 gold coind each. Since one gold coin is better than nothing, the two pirates accepts the plan and the leader survives.
Assumptions
A few assumptions are required to explain this solution:
- First, assume that if the Pirate 5 (the top pirate) is voted down and gets killed, then the remaining pirates retain their rankings and continue the game, with Pirate 4 now in charge. If Pirate 4 is killed, then Pirate 3 is in charge, and so on.
- Second, assume that any vote includes the person who proposed the plan (the top pirate), and a tie vote is enough to carry the plan.
- Third, assume that all pirates are acting rationally to maximize the amount of gold they receive, and are not motivated by emotion or vindictiveness.
- Fourth, assume that pirates are ruthless and cannot be trusted to collaborate with each other.
Generalized answer is
If there are odd number of pirates then
the number of coins with top pirate = total number of coins - number of odd numbers below the number.
else
the number of coins with top pirate = total number of coins - number of even numbers below the number.
The cheating husband problem is a classic recursion pb.
Once all the wives know there are at least 1 cheating husband, we can understand the process recursively. Let's assume that there is only 1 cheating husband. Then his wife doesn't see anybody cheating, so she knows he cheats, and she will kill him that very day. If there are 2 cheating husband, their wives know of one cheating husband, and must wait one day before concluding that their own husbands cheat (since no husband got killed the day of the announcement).
So with 100 cheating husbands, all life is good until 99 days later, when the 100 wives wives kill their unfaithful husband all on the same day.
91. What is the birthday paradox ?
In probability theory, the birthday problem or birthday paradox concerns the probability that, in a set of n randomly chosen people, some pair of them will have the same birthday. By the pigeonhole principle, the probability reaches 100% when the number of people reaches 367 (since there are 366 possible birthdays, including February 29). However, 99% probability is reached with just 57 people, and 50% probability with 23 people. These conclusions are based on the assumption that each day of the year (except February 29) is equally probable for a birthday.
The mathematics behind this problem led to a well-known cryptographic attack called the birthday attack, which uses this probabilistic model to reduce the complexity of cracking a hash function.
Understanding the problem
The birthday problem asks whether any of the people in a given group has a birthday matching any of the others - not one in particular. (See "Same birthday as you" below for an analysis of this much less surprising alternative problem.)
In the example given earlier, a list of 23 people, comparing the birthday of the first person on the list to the others allows 22 chances for a matching birthday, the second person on the list to the others allows 21 chances for a matching birthday, third person has 20 chances, and so on. Hence total chances are: 22+21+20+....+1 = 253, so comparing every person to all of the others allows 253 distinct chances (combinations): in a group of 23 people there are  = 253 pairs.
= 253 pairs.
Presuming all birthdays are equally probable,[2][3][4] the probability of a given birthday for a person chosen from the entire population at random is 1/365 (ignoring Leap Day, February 29). Although the pairings in a group of 23 people are not statistically equivalent to 253 pairs chosen independently, the birthday paradox becomes less surprising if a group is thought of in terms of the number of possible pairs, rather than as the number of individuals.
Calculating the probability
92.a What method would you use to look up a word in a dictionary?
Technically, all of those answers are right. However, major companies are looking for the most efficient way. By saying you use a trie, you search basically the way most people do. Slightly brighter people use binary searches, because it is much quicker. Even brighter people use B-Trees. A binary search is basically a B-tree search where the B-tree node has only 1 key and 2 pointers. There is an optimum B-tree that will have a search that is log_n().
I would say that it highly depends on the technical form of the dictionary we're allowed to give to the dictionary and the constraints that come with. I would go for a B-Tree or at least a Hash Index
The standard trade offs between these data structures apply.
- Binary Trees
- medium complexity to implement (assuming you can't get them from a library)
- inserts are O(logN)
- lookups are O(logN)
-
Linked lists (unsorted)
- low complexity to implement
- inserts are O(1)
- lookups are O(N)
-
Hash tables
- high complexity to implement
- inserts are O(1) on average
- lookups are O(1) on average
- A hash table can degenerate to O(N) in the worst case.
In a map, as in linked lists and binary trees, each entry is a node storing more than just key and value, also separately-allocated in some implementations, so you use more memory and increase chances of a cache miss.
Of course, if you really care about how any of these data structures will perform, you should test them. You should have little problem finding good implementations of any of these for most common languages. It shouldn't be too difficult to throw some of your real data at each of these data structures and see which performs best.
92.b. How would you store 1 million phone numbers?
At first sight, a trie seems interesting since it offers classification and simple retrieval.
A trie, also called digital tree or prefix tree, is an ordered tree data structure that is used to store a dynamic set or associative array where the keys are usually strings. Unlike a binary search tree, no node in the tree stores the key associated with that node; instead, its position in the tree defines the key with which it is associated. All the descendants of a node have a common prefix of the string associated with that node, and the root is associated with the empty string. Values are normally not associated with every node, only with leaves and some inner nodes that correspond to keys of interest. For the space-optimized presentation of prefix tree, see compact prefix tree.

The problem with a trie comes from the space overhead since it requires O(n log n) space to store the pointers.
However, there are rules for engagement when dealing with phone numbers. They're sparse, for one, meaning not all possible area codes are used. In this case, a simple tree is a-ok. I mean think about it... you only need 269 + 26 for Canada. That's pretty small, and you've cut out a large portion of space PLUS increased search time. Not only that, but it can be augmented for location information.
After that, you've got a 7 digit number. This can be stored in a single 32-bit integer. Sort on insert, and you've got a pretty fast mechanism for retrieval as you can do binary search on the remainder of the number.
In java, an implementation I would look into a BitSet:
private BitSet dir = new BitSet(1000000);
public void addTelephoneNumber(int number) {
dir.set(number);
}
public void removeTelephoneNumber(int number) {
if (dir.get(number)) {
dir.flip(number);
}
}
public boolean isNumberPresent(int number) {
return dir.get(number);
}
I would suggest a typical Hash Table interface since a cache is nothing more regarding its APIs. The bug difference is that a cache is bounded in terms of size.
It has a maximum size with an eviction method (either LRU or LFU).
In addition, a lot of cache implementation support artificial eviction of elements from the cache using:
- Maximum Idle Time: the maximum duration (typically in secs or millisecs) before an element in the cache that hasn't been used any more is removed from the cache.
- Maximum Time To Live: the absolute maximum time an element is allowed to be kept in the cache before its is removed (no mather whether it has been used or not)
I would hence suggest as typical API this way (using a Java interface):
public interface Cache<TKey, TObj> {
void put (Tkey, TObj);
TObj get (Tkey);
boolean contains (Tkey);
}
In case of an LRU cache, one could implement get and put this way, usingf pseudo code:
(I asume here we are using both MAX_IDLE_TIME, MAX_TIME_TO_LIVE
procedure get (tKey)
if underlyingMap contains tKey then // one should better get object and compare with null
lastUsedTime = getLastUsedTimestamp (tKey)
currentTime = getCurrentTime()
if lastUsedTime + MAX_TIME_TO_IDLE < currentTime then
cachePutTime = getPutInCacheTimeStamp (tkey)
if cachePutTime + MAX_TIME_TO_LIVE < currentTime then
return underlyingMap.get (tKey)
end if
end if
// I assume cache eviction following time limits is passive
// If I reach this point I can get rid of the element anyway
removeFromCache (tKey) // needs to remove tStamps as well
end if
return NULL;
end proc
procedure put (tkey, tObj)
underlyingMap.put (tkey, tObj)
currentTime = getCurrentTime()
saveLastUsedTimeStamp (tKey, currentTime)
savePutInCacheTimeStamp (tKey, currentTime)
if (underlyingMap.size() > MAX_CACHE_SIZE) then
removeLeastRecentlyUsed()
end if
end proc
One can generalize this to a filtering iterator.
A simplified version of a filtering iterator is as follows:
public abstract class FilteringIterator<Type> implements Iterator<Type> {
private Iterator<Type> model = null;
private Type prefetched = null;
public FilteringIterator(Iterator<Type> model) {
this.model = model;
}
public boolean hasNext() {
if (this.prefetched != null) {
return true;
}
// so, prefetched == null
while (model.hasNext()) {
Type o = model.next();
if (this.shouldShow(o)) {
this.prefetched = o;
return true;
}
}
return false;
}
public Type next() {
if (this.prefetched == null && !this.hasNext()) { // has next will set prefetched for the below
throw new NoSuchElementException();
}
Type ret = this.prefetched;
this.prefetched = null;
return ret;
}
protected abstract boolean shouldShow(Type o);
}
Then one is left with implementing the filter method shouldShow() this way:
protected boolean shouldShow(Integer o) {
return o.intValue() < 0;
}
94.b. How would you implement an Iterator for Binary tree inOrder traversal
The idea consists in merging the iterative inOrder algorithm with the next() method of the iterator:
- The "visit" operation consists in stopping the inOrder iteration and returning the result.
- Upon a call to next, resume the inOrder algorithm iterations.
Assuming a tree node is defined with:
node.leftnode.informationnode.right
One can write it this way in Java
public class InOrderIterator<E extends Comparable<? super E>> implements Iterator<E> {
private LinkedList<Node<E>> parentStack = new LinkedList<Node<E>>();
private Node<E> node = null;
private E current = null;
public InOrderIterator (Node root) {
this.node = root;
fetchNext();
}
public boolean hasNext() {
return current != null;
}
public E next() {
E retValue = current;
if (parentStack.isEmpty() && node == null) {
current = null;
}
fetchNext();
if (retValue != null) {
return retValue;
} else {
throw new NoSuchElementException();
}
}
private void fetchNext() {
while (!parentStack.isEmpty() || node != null) {
if (node != null) {
parentStack.add(node);
node = node.left;
} else {
node = parentStack.removeLast();
// visit
current = node.information;
node = node.right;
break;
}
}
}
}
- A simple hash could do the trick. On a computer SHA-256. By hand MD5 or something as simple as a sum ...
- Otherwise an RSA Public encryption / Private decryption. Along with the card to Bob you send the public key to be used for the encryption.
- Others such that Diffie-Hellman key exchange seems unappliable due to the requirement of more than one exchange to set up the communication.
Just a reminder on the RSA algorithm:
Security relies on the concept of a TOW (Trapdoor One-Way function) and the difficulty to factoriue large number.
Key generation:
- Generate 2 prime numbers p and q (>= 512 bit each)
- Compute n = pq
- Choose a small number e which is not a divisor of fi(n) = (p - 1)(q - 1)
=> e in Z_fi(n)*- numer of different possible e : fi(fi(n))
- e is inversible mod fi(n)
- Compute d = e^(-1) (mod fi(n))
- Define : (n, e) = RSA Public Key
- Define : (n, d) = RSA Private Key
Encryption : Compute c = m^e (mod n)
Decryption : Compute m = c^d (mod n)
Real solution using a balanced-binary search tree
- We use a binary search tree that is balanced (AVL/Red-Black/etc), So adding an item is O(log n)
- One modification to the tree: for every node we also store the number of nodes in its subtree. This doesn't change the complexity.
(For a leaf this count would be 1, for a node with two leaf children this would be 3, etc)
This implies:
- -> When ading an element, the count for each traversed node is incremented by 1
- -> The usual rotation algorithms need to be adapted as well in order to adapt the count of the moved nodes
Note : We can now access the Kth smallest element in O(log n) using these counts:
procedure get_kth_item(subtree, k)
if subtree.left is null then
left_size = 0
else
left_size = 0 subtree.left.size
if k < left_size then
return get_kth_item(subtree.left, k)
else if k == left_size then
return subtree.value
else # k > left_size
return get_kth_item(subtree.right, k-1-left_size)
A median is a special case of Kth smallest element (given that you know the size of the set).
So all in all this is another O(log n) solution.
In conclusion with such a data structure:
- Insertion takes still O(log n) since incrementing the count only adds a constant factor
- Find median takes O(1) :
- either both sides of the root have same count => root is median (O(1))
- either left side has more nodes => an easy algorithm can return the median from the left sub-tree (O(1))
- eithre right side has more nodes => same thing
- Find kth element takes O(log n)
Note : If the low insertion time constraint is released, another solution for FIND-MEDIAN
If only FIND-MEDIAN is important, one can simply maintain two sorted lists kept the same size.
- At all time, the median is stored in a variable.
- left list stores element below the median while right list stores element above the median
- After an insertion, of one list's sizes becomes bigger that the other, then the current median is added to the other list and the new median is poped from the bigger list.
(at end of the left list or beginning of the right list)
In java:
public static int fromExcelColumn (String columnLabel) {
// sanitizing
if (columnLabel == null || columnLabel.trim().length() == 0) {
return 0;
}
String label = columnLabel.trim().toUpperCase();
int retValue = 0;
// algorithm
for (int i = 0; i < label.length(); i++) {
retValue = (retValue * 26) + (label.charAt(i) - 'A' + 1) ;
}
return retValue;
}
98. What would you do if senior management demanded delivery of software in an impossible deadline?
First I would point out the The Project Management Triangle (called also Triple Constraint). This is a model of the constraints of project management:
TIME - COST - SCOPE.
These three variables cannot be all the three together arbitrarily decided, only two at a times. It basically states that management can fix two of these variables. The third one is then implied.
I would point ou a warning though: rather sacrifice the scope than the expected cost to ensure the delivery date since adding manpower to a project that is already late only makes it worst (Mythical man month - Brooks - 9 women cannot make a baby in one month.).
One should not that XP adds one variable to them:
TIME - COST - SCOPE - QUALITY
The principle is other than that almost the same.
Let's break it down. The product of their ages is 72. So what are the possible choices?
2, 2, 18 => sum(2, 2, 18) = 22
2, 4, 9 => sum(2, 4, 9) = 15
2, 6, 6 => sum(2, 6, 6) = 14
2, 3, 12 => sum(2, 3, 12) = 17
3, 4, 6 => sum(3, 4, 6) = 13
3, 3, 8 => sum(3, 3, 8 ) = 14
1, 8, 9 => sum(1,8,9) = 18
1, 3, 24 => sum(1, 3, 24) = 28
1, 4, 18 => sum(1, 4, 18) = 23
1, 2, 36 => sum(1, 2, 36) = 39
1, 6, 12 => sum(1, 6, 12) = 19
The sum of their ages is the same as your birth date. That could be anything from 1 to 31 but the fact that Jack was unable to find out the ages, it means there are two or more combinations with the same sum. From the choices above, only two of them are possible now.
2, 6, 6 - sum(2, 6, 6) = 14
3, 3, 8 - sum(3, 3, 8 ) = 14
Since the eldest kid is taking piano lessons, we can eliminate combination 1 since there are two eldest ones. The answer is 3, 3 and 8.
Source : http://mathforum.org/library/drmath/view/58492.html
Don't hesitate to leave a comment or contact me should you see any error in here, or any improvement, better solution, etc. and I'll update the post accordingly.
Tags: hard-questions interview-questions software-engineering software-engineering-interview-questions